Это перевод материала, опубликованного на сайте Medium. Предыдущие части текста здесь и здесь.

Атаки чёрного ящика, основанные на решении граничной аппроксимации
В настройках чёрных ящиков злоумышленники не могут получить доступ к полной структуре модели и поэтому вычисление dL/dx напрямую невозможно. По этой причине этот способ атак основан на различных методах вычисления предполагаемого поведения модели, которые базируются на имеющихся входных данных. Вот понятный пример из жизни: вы психолог и задаёте вопросы пациенту, получая ответы на них вы ставите диагноз. Этот метод атак представляет из себя нечто похожее.
Атака, заменяющая чёрный ящик
Идея, которая стоит за атакой-заменителем чёрного ящика (Papernot et al., 2016), состоит в том, чтобы приблизиться к грани решения модели чёрного ящика, который злоумышленник намеревается атаковать. Для этого необходимо полностью обучить модель-заменитель синтетическому набору данных, которые будут соответствовать тем, что использовались при обучении чёрного ящика. К примеру, предположим, что кто-то пожелал атаковать чёрный ящик, который обучен распознавать рукописный текст при помощи датасета MNIST. В самом простом случае мы сможем создавать синтетические данные вручную, при помощи подделки почерка. Самое интересное заключается в том, что метка синтетического набора данных должна исходить из прогноза, который был сделан чёрным ящиком.
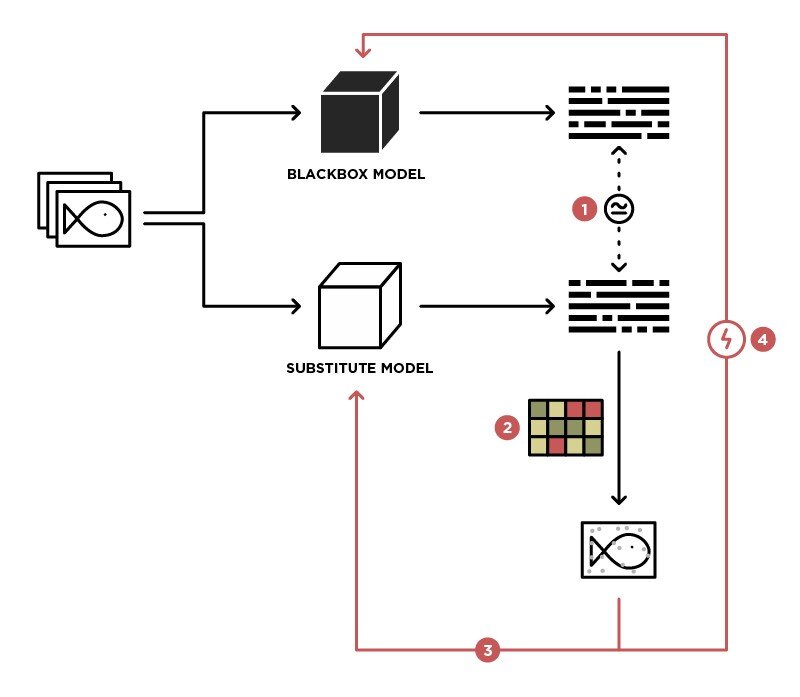
В статье Papernot et al. (2016) отмечается, что на практике мошенники не могут воспроизвести неограниченные запросы на целевую модель. Для того, чтобы отследить такие действия был разработан метод увеличения набора данных, который называется «увеличение набора данных на основе якобиана». Этот метод увеличения основан на вычислении градиентов метки, которая является целевой моделью, относящейся к входным данным. Это нужно для того, чтобы создать несколько дополнительных выборок вокруг несущественного исходного набора синтетических данных. Однако злоумышленник не может обладать информацией о целевой модели, поэтому градиенты будут вычисляться посредством параметров замещающей модели. В статье Papernot et al. (2016) утверждается, что этот метод дополнения данных является более эффективным для приближения к границам решений целевой модели без какой-либо необходимости в создании большого количества запросов.
Обучение замещающей модели с применением предложенного метода дополнения данных работает следующим образом. Изначально злоумышленник создаёт небольшой обучающий набор, который можно инициализировать, если выбрать один образец из каждого предполагаемого набора данных, представляющих входной домен целевой модели. Далее замещающая модель учится на синтетических наборах данных посредством меток, которые были предоставлены целевой моделью (достаются они при помощи запроса к целевой модели). После того, как обучение будет завершено, новые точки данных создаются путем возмущения выборок в имеющемся наборе данных. Возмущения должны соответствовать вычисленным градиентам. Далее новые входные данные добавляются к уже существующему набору данных. В результате происходит увеличение набора синтетических данных на итерацию. Этот процесс должен произойти несколько раз.
После того, как обучение модели завершится, злоумышленник сможет генерировать соперничающие примеры, которые смогут обмануть оригинальную модель. Для этого будут применяться методы белых ящиков, так как злоумышленник будет иметь абсолютный доступ к заменяемой модели. Как демонстрируется в статье Papernot et al. (2016), соперничающие примеры, которые были созданы подобным образом, могут использоваться для обмана модели чёрного ящика, а всё благодаря свойству заменяемости, которым обладают такие соперничающие примеры. Более того, такая атака довольно часто используется для того, чтобы обойти методы защиты, которые в большинстве своём полагаются на градиентную маскировку. Одним из ярких примеров градиентной маскировки является защитная дистилляция (Papernot et al., 2015).
Атаки чёрного ящика, основанные на эвристическом анализе
В отличие от другого типа атак, которые направлены на dL/dx, в этом случае соперничающие примеры можно обнаружить при помощи эвристического анализа. К примеру, можно сгенерировать набор правил, который будет характеризовать сопутствующие примеры и применять алгоритмы анализа для поиска входных данных, удовлетворяющих данным правилам.
Пограничная атака
Пограничная атака (Brendel et al., 2018), также является формой атаки на чёрный ящик. Её работа осуществляется при помощи оценки последовательности возмущенных изображений через модель. Для проведения нецелевой атаки начальное изображение может быть взято из равномерного шума. Если злоумышленник решится провести целевую атаку, то начальный образ будет являться примером, основанным на деклассификации цели. Далее метод изменяет образ итеративно, чтобы он получил больше общих черт с примерами из других классов. При всём этом он продолжает быть соперничающим примером. Весь смыл пограничной атаки заключается в том, чтобы медленно, но верно, прощупывать «почву».
На практике в статье Brendel et al., 2018 устанавливаются некоторые ограничения, которые применяются после выборки шума η из алгоритма выше. Первое и второе ограничения являются гарантами того, что изображение всё ещё находится в рамках [0, 255] (для 8-битного RGB изображения). Последнее ограничение гарантирует то, что η уменьшит расстояние между возмущенным изображением и исходными данными, оставаясь при этом соперничающим примером. Прочтите этот документ, проливающий свет на некоторые детали реализации.
На рисунке выше описана целевая пограничная атака, где всё начинается с настоящего изображение из желаемого класса. Делается этого для того, чтобы противник неверно классифицировал его (как рыбу) и изображение продолжило двигаться в направлении действительного ввода, относящегося к другому классу (например, кошки). Происходит это на протяжении нескольких итераций.
Заключение
В течение целых трёх статей мы разбирали различные типы атак. И вот, настал момент, когда пора подвести итоги:
- Некоторые атаки направлены на производную первого порядка, при этом они вычисляют производную функции потери по отношению к входу. Таким образом вход проталкивается к направлению, в котором показатель потери будет увеличиваться (FGSM, BIM, R+FGSM).
- Другие атаки основываются на итеративном процессе оптимизации целевых функций (L-BFGS, C&W, stAdv). Для таких атак используются L-BFGS, Ada (Kingma & Ba, 2014), а также другие методы оптимизации. Преимуществом подобных атак является то, что злоумышленник может применять мощные соперничающие критерии как целевую функцию. Кроме того, соперничающие примеры также можно получить посредством обучения генеративной модели трансформации для оптимизации целевых функций (ATN).
- Мы можем положиться на свойство заменяемости соперничающих примеров для атаки чёрного ящика. При этом атакуется замещающая модель, которая обучена на тех же данных, что и чёрный ящик.
- Ещё одна атака может быть проведена, если злоумышленник начнёт своё движение с точки данных, находящихся за пределами цели. Далее он должен попытаться приблизиться к границе решения между соперничающим и неконфликтным классом. После чего происходит «прощупывание почвы» посредством метода выборки отклонений.
Я надеюсь, что данный материал был полезен для вас, и вы заинтересуетесь соперничающим машинным обучением.