Если вы кликали когда-нибудь в фейсбуке на формочках «этот перевод верен / этот перевод неверен», знайте, ваш труд пропал не зря. Фейсбук выкатил в опенсорс независимые от языка эмбеденги предложений (LASER — Language-Agnostic SEntence Representations). Все это добро работает для 90 языков и 28 алфавитов. Пишут, что это SOTA на современных NLP задачах. Все это сделано на Encoder-Decoder архитектуре с многослойным BiLSTM энкодером. Работает, как и положено для Фейсбука, на PyTorch. Причем, в зависимостях написано, что достаточно PyTorch 1.0 (!). В общем, нужно качать и тестировать: https://github.com/facebookresearch/LASER Чем на это ответит Гугл?
Если вы кликали когда-нибудь в фейсбуке на формочках «этот перевод верен / этот перевод неверен», знайте, ваш труд пропал не зря.
Фейсбук выкатил в опенсорс независимые от языка эмбеденги предложений (LASER — Language-Agnostic SEntence Representations). Все это добро работает для 90 языков и 28 алфавитов. Пишут, что это SOTA на современных NLP задачах.
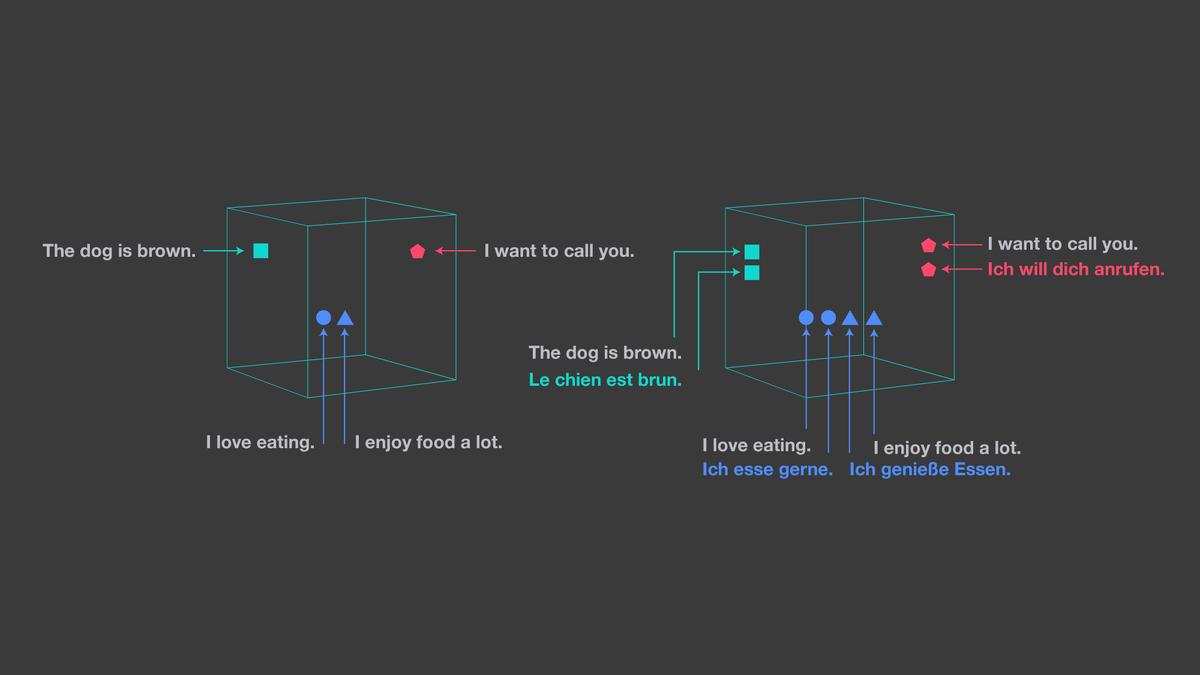
Все это сделано на Encoder-Decoder архитектуре с многослойным BiLSTM энкодером. Работает, как и положено для Фейсбука, на PyTorch. Причем, в зависимостях написано, что достаточно PyTorch 1.0 (!).
В общем, нужно качать и тестировать:
https://github.com/facebookresearch/LASER
Чем на это ответит Гугл?