Как я говорил ранее, прежде чем начать построение любой модели данные следует подготовить. Один из таких этапов - это удаление лишних, избыточных данных. Но как понять какие данные лишние?
Для начала разобъём наш dataset на векторы-столбцы, то есть векторы будут хранить значения всех объектов своего одного признака.
Одна из таких техник - это поиск линейно зависимых признаков. Линейная зависимость является симптомом того, что один признак может быть выведен из другого признака. Например, хранение одних и тех же данных в разных размерностях. Скажем, размер квартиры в метрах(первый признак) и сантиметрах (второй признак). Тогда зависимость между этими векторами можно записать так:
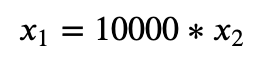
Jupyter позволяет отображать математические формулы прямо в ячейке ноутбука используя LaTeX формат в режиме Markdown-разметки ячейки. Например, более сложная формула ниже описана выражением "$$\beta_{1}x_{1} + \dots + \beta_{n}x_{n} = 0$$".
Линейно зависимыми могут быть более двух признаков, тогда линейную зависимость можно описать следующим образом:
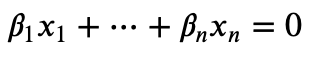
Есть одно следствие - если один из векторов-признаков состоит полностью из нулевых значений, то система всех признаков является избыточной. Перед нулевым вектором можно взять любой бета-коэффициент, а остальные beta-коэффициенты могут быть нулями, чтобы сработало условие нахождения линейно зависимости.
Таким образом если у нас есть векторное пространство V, то максимальное количество линейно-независимых векторов в этом векторном пространстве называется размерностью векторного пространства и обозначается dimV.