Мы продолжаем наше изучение основ Искусственного Интеллекта. Давайте вслед за структурным подходом погрузимся в таинства квазибиологического и эволюционного подходов. Они тоже в целом относятся к восходящей парадигме, да и сами по себе крайне интересны.
Квазибиологический подход в Искусственном Интеллекте или одним словом «биокомпьютинг» — это направление, сосредоточенное на разработке и использовании компьютеров, которые функционируют как живые организмы или содержат биологические компоненты. Родоначальником этого направления считается Уоррен Маккаллок.
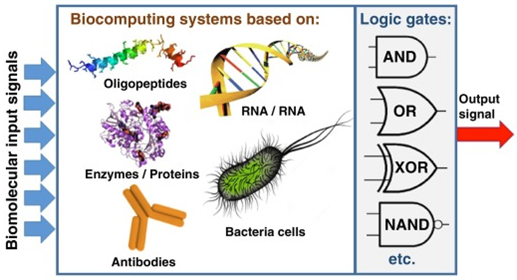
В основе этого подхода лежит понимание, что феномены человеческого поведения, наша способность к обучению и адаптации, есть следствие именно биологической структуры и особенностей её функционирования. Хотя на мой взгляд это очень слабая гипотеза.
Вычисления в рамках квазибиологического подхода организуются при помощи живых тканей, клеток, вирусов и биомолекул. Часто используются молекулы дезоксирибонуклеиновой кислоты, на основе которого создают ДНК-компьютер. Кроме ДНК, в качестве биопроцессора могут использоваться также белковые молекулы и биологические мембраны.
Обычно для решения определённой задачи создаётся так называемая «индивидуальная машина», которая в отличие от универсальной машины Тьюринга, направлена на решение конкретной задачи, причём обычно делает это более эффективным способом, поскольку индивидуальная машина специально сконструирована для решения этой задачи.

Машина Тьюринга, лежащая в основе стандартной вычислительной модели, выполняет свои команды последовательно, а в рамках квазибиологической парадигмы часто рассматривается массовый параллелизм. Ну вот если, к примеру, рассмотреть ДНК-компьютер, то в нём все молекулы ДНК одновременно участвуют во взаимодействиях, параллельно проводя вычисления.
Что такое машина Тьюринга? Это абстрактная вычислительная модель, предложенная Аланом Тьюрингом в качестве базового механизма описания алгоритмов. Согласно тезису Чёрча-Тюринга любой алгоритм может быть реализован при помощи программы для машины Тьюринга. А сама машина представляет собой бесконечную ленту, на которой специальное устройство может записывать символы, и оно же может символы считывать. Устройство движется по ленте вправо и влево, пока не встретит специальный символ окончания программы.
Работу жёстко запрограммированной машины легко нарушить, если на вход подать ей данные, которые она не может обработать. Индивидуальная машина может быть подвергнута эволюции, поэтому она может адаптироваться к изменению входных данных, как к резким, так и малозаметным.
Два самых главных направления в рамках квазибиологического подхода — это молекулярные вычисления и биомолекулярная электроника. Можно ещё упомянуть нейрокомпьютинг, но он обычно рассматривается как часть структурного подхода и искусственных нейронных сетей.
Молекулярные вычисления — это отдельная вычислительная модель, в которой решение задачи осуществляется при помощи проведения сложных биохимических или нанотехнологических реакций. Молекулярные компьютеры — это молекулы, запрограммированные на нужные свойства и поведение, которые, участвуя в химических реакциях, как бы «выращивают» результат.
Что интересно, идею биокомпьютинга подсказал выдающийся математик Джон фон Нейман в своей книге «Теория самовоспроизводящихся автоматов», которую, кстати, как обычно очень рекомендую. В этой книге описан проект клеточных автоматов, которые могут самовоспроизводиться, как и живая клетка.
Почти в каждой живой клетке нашего организма есть длинная молекула ДНК, которая кодирует генетическую информацию. При помощи различных ферментов цепочки ДНК могут быть разрезаны, склеены, в них могут добавляться буквы генетического кода или удаляться из них. Всё это — базовые операции работы с информацией, которые могут быть использованы для производства вычислений.
Более того, цепочки ДНК могут воспроизводиться и клонироваться. Это позволяет запустить массовый параллелизм поиска решения. В небольшой пробирке после проведения должным образом сконструированной биохимической реакции будет получен результат, который считывается специальной аппаратурой.
Интерес вызывает то, что для некоторых задач молекулярные компьютеры очень быстро и точно находят приемлемые решения, в то время как традиционные компьютеры затрудняются это сделать. Например, решение задача коммивояжёра, то есть поиска кратчайшего пути обхода графа, при помощи реакций с ДНК осуществляется практически мгновенно, в то время как для обычного компьютера требуется огромное количество времени.
Правда, тут есть одна тонкость, которая мешает работе обычному компьютеру — это комбинаторный взрыв. И если в традиционной архитектуре он ведёт к увеличению времени решения, то для ДНК-компьютера требуется подготовка огромного количества вариантов нуклеотидных нитей. Соответственно, объём пробирки растёт так же, как и количество вариантов в комбинаторном взрыве.
Второе направление — биомолекулярная электроника. Она основана на том, что биомолекулы переносят заряд, а потому могут быть использованы для построения электронных устройств обработки информации. А поскольку размеры молекул находятся в наноинтервалах, то это прямой путь к настоящим нанотехнологиям.
Ну хорошо. Теперь давайте посмотрим на эволюционный подход. В его рамках предполагается как бы «выращивание» нужного решения при помощи генетических процедур и отбора. То есть, фактически, в рамках эволюционного подхода представлены некоторые эвристические методы оптимизации, которые очень часто используются в Искусственном Интеллекте.
В рамках эволюционного подхода обычно выделяют следующие технологии и методы: эволюционное программирование, генетическое программирование, эволюционные стратегии, генетические алгоритмы, дифференциальная эволюция и нейроэволюция.
Другими словами, а что если вычислительные процессы могли бы эволюционировать так же, как это делают биологические виды в своей экологической среде? Возможно, получилось бы «выращивать» программы для оптимального решения поставленной задачи? Эволюционное программирование как раз и основано на этой идее.
Если же в качестве объектов отбора выступают сами программы, то получается уже генетическое программирование. Ведь, действительно, программы пишутся на определённом языке программирования и, в конечном итоге, представляют собой строки символов. Эти строки можно подвергнуть генетическим преобразованиям и отбору. Эта очень мощная идея получила своё развитие в том, что программы начали писать и оптимизировать другие программы, и уже исследователи, запустившие процесс, не могут разобрать и интерпретировать полученные исходные коды, которые работают правильно и очень эффективно.
Генетические алгоритмы — это наиболее яркий представитель эволюционного подхода. Сами по себе они опять являются одним из эвристических методов оптимизации для поиска оптимального решения (или, как минимум, субоптимального). Они работают с данными, которые могут быть представлены в виде «хромосом» — последовательностей генов, то есть списков каких-либо значений, к которым можно применить генетические операции. Здесь уже нет такого жёсткого требования насчёт типа таких данных, главное — чтобы на генах были определены эти операции, которые возвращали бы приемлемый результат, имеющий смысл.
Генетический алгоритм состоит из следующих шагов.
Генерация начальной популяции. Это значит, что необходимо подготовить некоторое количество «начальных» значений в пространстве поиска, с которых алгоритм начнёт свою работу. Начать можно с произвольных значений, но если такие значения будут как можно более близки к целевому, то алгоритм отработает намного быстрее.
Запуск цикличного процесса рождения новых поколений и отбора. Фактически, это и есть сам генетический алгоритм, который раз за разом запускает процесс порождения новых поколений, изучения новых особей и отбора наиболее интересных. Этот процесс состоит из следующих шагов и операций.
Скрещивание (или перекрёст) — это операция, при которой берутся две особи текущего поколения, и их генотип перемешивается друг с другом. Чаще всего два генотипа разрезаются в одинаковом случайном месте, и после этого вторые части переставляются друг с другом. Так получаются два новых потомка. Фактически, скрещивание делается каждой особи с каждой, да ещё и по нескольку раз, чтобы разрезание генотипа происходило в разных местах. Так получается набор особей следующего поколения.
Мутация — это операция по внесению случайных изменений в генотип потомства. С установленной частотой в каждый новый генотип после скрещивания вносятся случайные изменения. Если частота мутаций высокая, то наблюдается «подвижность» поиска, если же частота мутаций слишком низкая, то часто это приводит к «залипанию» алгоритма в локальном экстремуме, из которого он не может выбраться и, соответственно, остановиться. Величину частоты мутаций часто подбирают при помощи экспериментов для каждой конкретной задачи.
Отбор — это операция по выбору наиболее приспособленных особей. Обычно выбирается какая-то доля (например, 10 %) тех особей нового поколения, для которых фитнесс-функция возвращает наилучшие результаты. Иногда в отобранное множество особей нового поколения добавляются наименее приспособленные особи, для которых фитнесс-функция возвращает наихудшие результаты. Это делается для получения генетического разнообразия и является инструментов борьбы с залипанием в локальных экстремумах. Также иногда в состав нового поколения включаются некоторые представители предыдущего поколения, которые в данном случае называются «элитой». Вообще, операция отбора также подбирается на основе экспериментов для каждой конкретной задачи.
Мы ещё детально ознакомимся с генетическими алгоритмами и вообще эволюционным подходом в будущих публикациях. Ну и на этой жизнеутверждающей ноте я спешу закончить. Мы изучили некоторые технологии и методы в рамках квазибиологического и эволюционного подходов, а в следующий раз мы обратим свой взгляд на агентный подход. Оставайтесь с нами и до скорой встречи. Пока.