Всем доброго времени суток!)
В двух прошлых статьях, я рассказывал про парсинг, как он работает, какие библиотеки использовать и немножко рассказал про requests.
Сегодня, мы посмотрим на такую библиотеку как bs4 и напишем парсер вордпресса.
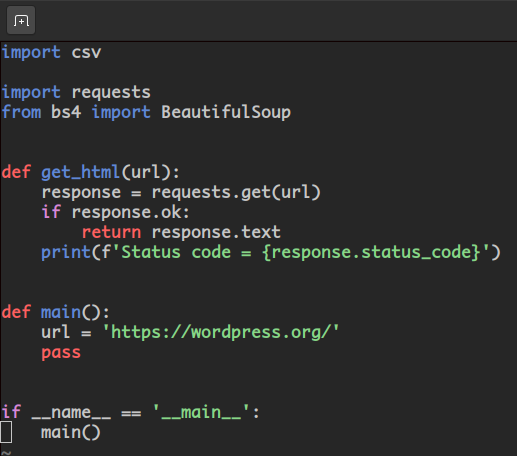
Сейчас мы имеем вот такой код. Соберем популярные плагины и запишем в csv.
Напишем функцию, которая собирает данные.
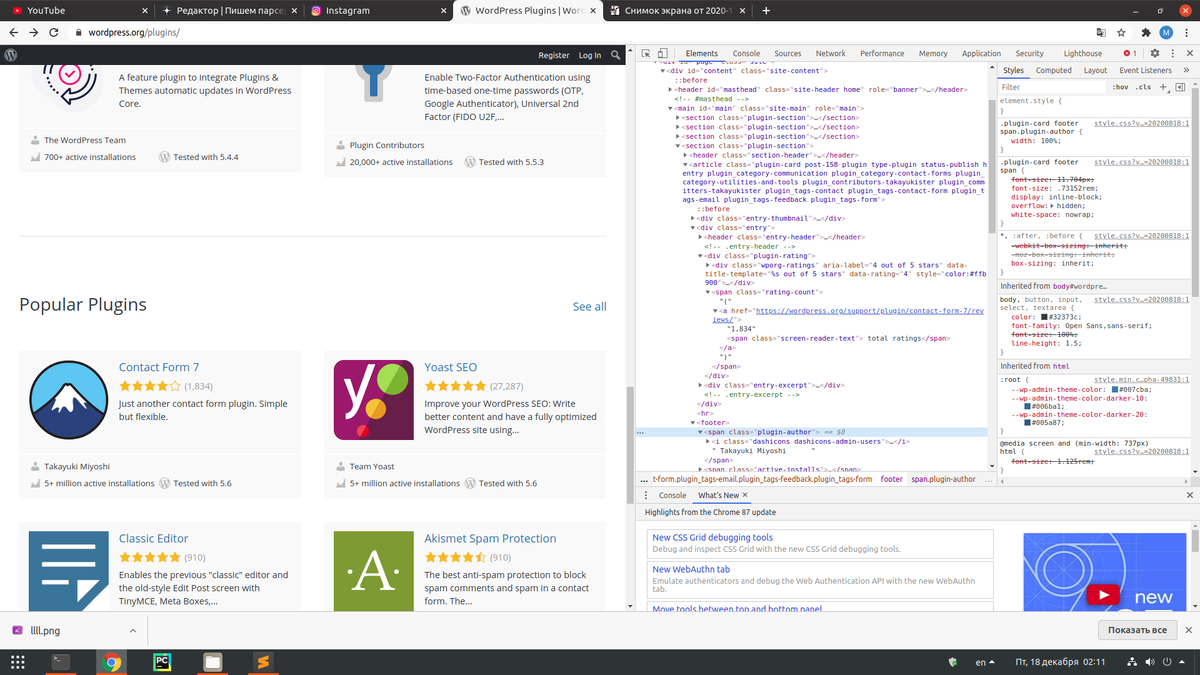
Вот что мы имеем на сайте вордпресс. У нас есть 4 секции, внутри каждой по 4 тега article, как раз они нам и нужны. Внутри них вся информация, которая нам нужна (название плагина, рейтинг и автор).
Вот такая получилась функция
Создаем объект бьютифулсупа, который будет парсить наш html.
Сначала забираем все секции с помощью метода find_all. Он возвращает список и мы берем оттуда последний элемент. (т.к нам нужна последняя секция).
Далее собираем все теги article, также с помощью метода find_all. И уже внутри этих тегов нужная нам инфа.
Запускаем цикл и перебираем каждый плагин, собирая информацию.
Получается вот такой код
Учитесь и задавайте вопросы. Спасибо за внимание!)