В этой статье я расскажу о том, как выбирать модель классификации, какие существуют метрики для этого и как они подсчитываются.
Ориентироваться стоит на цели работы алгоритма, чтобы модель не ошибалась в наиболее критичных ситуациях. Допустим, вы отвечаете за качество биометрической системы аутентификации в банке, которая после подтверждения подлинности человека по голосу позволяет ему осуществлять значимые операции (перевод со счетов, снятие наличных...).
Система может допускать ошибки первого и второго рода (ложноотрицательная, ложноположительная классификация). Для предложенной ситуации они важны в разной степени. Так, допустить ошибку первого рода и не пропустить человека по его голосу, не так критично, как авторизовать злоумышленника, подделавшего свой голос под реального клиента.
Соответственно, в данной ситуации нам принципиально свести к нулю число ложноположительных случаев. А ложноотрицательные, желательно, одновременно держать в разумных пределах.
Для интерпретации этих целей введены понятия точности и полноты:
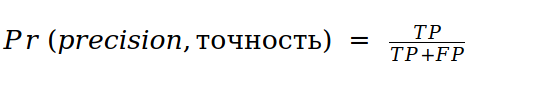
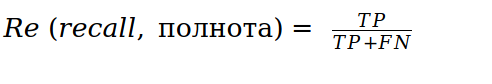
В данной терминологии и приведенной выше задаче для нас важнее точность, чем полнота.
Другой пример. Если по территории страны распространяется опасная эпидемия, то для руководства важнее идентифицировать всех заболевших (уменьшить число ложноотрицательных случаев, повысить полноту), нежели ошибиться и признать здорового больным.
Аналогичным образом для компании, добывающей ценные породы из астероидов в космосе, из-за дороговизны процедуры важнее минимизировать ложноположительные случаи и точно определить содержит ли астероид добываемые ресурсы, нежели ошибочно признать его не представляющим интереса. В то же время богатой школе, отбирающей талантливых детей, важнее не пропустить ценного ученика, нежели ошибочно завысить интеллект ребенка.
Иногда бывают ситуации, когда ошибки первого и второго рода одинаково критичны. Тогда вы можете ориентироваться на третью метрику:
Как можно заметить, она изменяется от 0 до 1 и придает одинаковый вес обоим видам ошибок.
Теперь рассмотрим пример подсчета этих метрик. Пусть некий И. зарегистрировался в приложении знакомств, алгоритм на основе машинного обучения порекомендовал И. 30 друзей из 100. И. лайкнул 15 фотографий из 30 предложенных, в дальнейшем выяснилось, что И. мог бы лайкнуть еще 30 фотографий из 70 непредложенных.
Предположим, что лайк И. является положительным исходом, а отсутствие лайка - отрицательным. Соответственно предсказанный лайк, совпавший с реальным - TP, предсказанный лайк, не завершившийся реальным лайком - FP и т. д. Тогда:
Pr = 15/(15+15) = 0.5
Re = 15/(15+30) = 0.33
F1 = 2*0.5*0.33/(0.5+0.33) = 0.4