Часто бывает нужно скопировать с какого-либо сайта большой объем данных, и поддерживать эти данные в актуальном состоянии. Делюсь пошаговой инструкцией, как это сделать!
Какое-то время назад я уже публиковал статью о том, как можно парсить данные с помощью гугл таблиц: вот эта статья, и мне теперь приходят вопросы, как это правильно делать. Сложность заключается в подборе правильных параметров для аргумента xpath в формуле importxml.
Вот и недавно пришел еще один вопрос:

Поэтому, давайте сегодня разберем еще раз, и в деталях, как парсить сайты с помощью google sheets.
Смотрите видео или читайте текст ниже, как вам удобнее!
С чего начнем? Давайте я коротко расскажу о том, что такое XPath.
1. XPath - что это?
XPath расшифровывается как XML Path Language - язык пути для XML, и служет для идентификации узлов и навигации по XML документу (Обычная веб-страница - это входит в подмножество документов XML). Это один из основных стандартов для интернета: с 16 ноября 1999 XPath стал получил рекомендацию W3C (World Wide Web Consortium) - главной организации, занимающейся стандартами в интернет.
Выражения XPath используется во многих языках программирования, включая JavaScript, Java, PHP, Python, С/С++ и многие другие.
Подробно про XPath можно прочитать на этом сайте (Жмите кнопку Next/Следующий вверху). Кстати, сайт можно перевести с помощью гугл-переводчика, и качество перевода отличное.
Доступна отличная шпаргалка по XPath: здесь.
2. Смотрим исходный код веб-страницы
Следующий шаг - нам нужно посмотреть код веб-страницы. Но не весь, от начала и до конца, а то, что касается элементов, которые мы хотим импортировать в таблицу. Жмем правой кнопкой мыши на интересующем элементе и выбираем "Просмотр кода элемента" ("Inspect") (в разных браузерах название этого пункта меню может немного отличаться).
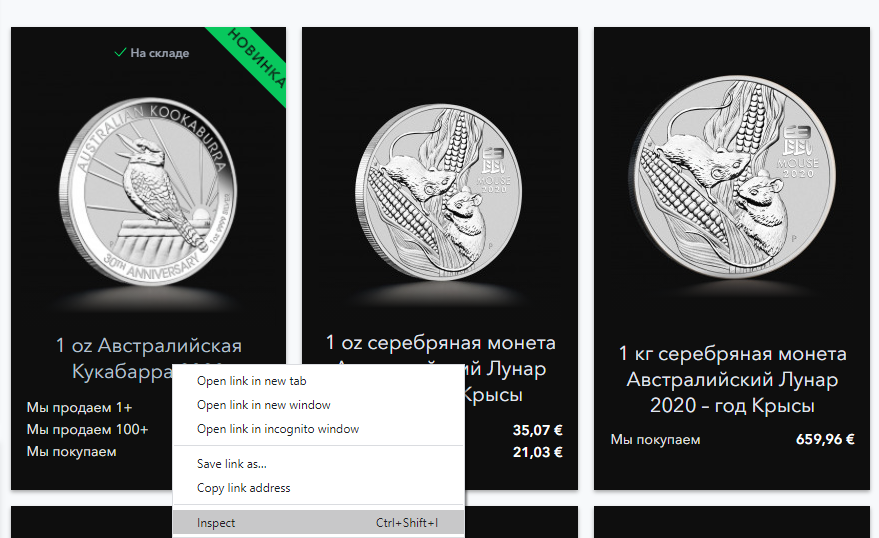
После этого в правой панели текущего окна или в новом окне откроется консоль разработчика, в которой отображено дерево элементов веб-страницы. Водя мышкой над этими элементами можно заметить, как на веб-странице подсвечиваются те или иные области:
Нам для импорта понадобятся:
- Элемент div с параметром class="grid__col--xs-6 grid__col--sm-4"
- Элемент figure и элемент img под ним
- Элемент div с параметром class="product__meta-box"
При этом второй и третий элементы должны быть вложены в первый, иначе мы захватим немного лишнего (Например, такие же элементы, которые доступны через меню, но относящиеся к другим монетам).
Ну что, подготовительная работа на этом завершилась. Приступим к парсингу.
3. Парсинг сайта в гугл шитс
Открываем таблицы гугл, и на новом листе пишем формулу. Я бы разместил ее в ячейке A2, чтобы потом в верхней строке можно было добавить заголовок. Чтобы не сочли рекламой, не буду писать ссылку на сайт в формуле. Вместо "адрес сайта" вам нужно будет подставить реальную ссылку.
=IMPORTXML("адрес сайта"; "//div[@class=""grid__col--xs-6 grid__col--sm-4""]//figure/span/img/attribute::data-srcset")
Надеюсь, эта формула не испугала вас? В ней говорится, что мы хотим найти элемент div с параметром class="grid__col--xs-6 grid__col--sm-4", и в дочерних элементах найти вложенные друг в друга элементы figure, span и img, и выгрузить в таблицу параметр "data-srcset" элемента img.
Результат пока мало похож на то, что мы ожидали, но это потому, что он в "сыром" виде. Его нужно немного приготовить. Посмотрев на эти данные, мы можем сделать вывод, что здесь указаны ссылки на иллюстрации разных размеров для каждого из товаров. Разделяются запятой, а размер изображения отделен от ссылки символом новой строки. Разобьем все это на отдельные элементы с помощью функции SPLIT. Как аргументы мы укажем нашу импортированную таблицу, символы которые разделяют (запятая и перевод строки. Перевод строки задается с помощью спец-символа с кодом 10). Ввиду того, что у нас IMPORTXML возвращает массив, а функция SPLIT привыкла работать с одной строкой, нужно с помощью ARRAYFORMULA указать, что мы работаем с массивом. Итак, конструируем формулу:
=arrayformula(split(IMPORTXML("адрес сайта"; "//div[@class=""grid__col--xs-6 grid__col--sm-4""]//figure/span/img/attribute::data-srcset");","&char(10);true;true))
Результат уже больше похож на таблицу. Давайте вместо ссылок поставим картинки. Еще раз поменяем формулу:
С помощью функции index оставим только 7 столбец (ссылки на среднюю по размеру картинку), допишем к нему в начале "http:", чтобы была правильная ссылка. Также обратим внимание, что ссылка заканчивается лишним пробелом или каким-то другим спец-символом; удалим его с помощью функции trim. И все это используем как аргумент функции image:
=arrayformula(image(trim("http:"&index(split(IMPORTXML("адрес сайта";"//div[@class=""grid__col--xs-6 grid__col--sm-4""]//figure/span/img/attribute::data-srcset");","&char(10);true;true);;7))))
Увиличем еще высоту строк. Первый столбец нашей таблицы готов, дальше будет проще.
Во второй колонке мы напишем новую формулу. Точно так же мы будем искать элемент div с параметром class="grid__col--xs-6 grid__col--sm-4" и извлекать весь текст в элементе div с параметром class="product__meta-box":
=IMPORTXML("https://tavid.ee/ru/serebro/serebryanye-monety/";"//div[@class=""grid__col--xs-6 grid__col--sm-4""]//div[@class=""product__meta-box""]")
Добавим все-таки в верхней строчке заголовки.
Видно, что скопировалось все что нам было нужно, и осталось это немного причесать, и из сырого вида привести в требуемый для таблицы. Колонка "Название" уже в требуемом виде. Напишем формулу в F2:
=iferror(arrayformula(REGEXEXTRACT(C2:C;"Мы продаем 1\+([\s\S]*)€"));"")
Этой формулой мы извлекаем из данных в столбце C все, что находится между словами "Мы продаем 1+" и знаком евро.
Кстати, про регулярные выражения у меня уже была статья. Почитайте, если интересно!
Аналогичная формула для ячейки G2:
=iferror(arrayformula(REGEXEXTRACT(D2:D;"Мы продаем 100\+([\s\S]*)€"));"")
И такая же для H2, с единственным отличием, что данные "мы покупаем" у нас отображаются вразнобой, то в столбце D то в столбце E:
=iferror(arrayformula(if(E2:E="";REGEXEXTRACT(D2:D;"Мы покупаем([\s\S]*)€");REGEXEXTRACT(E2:E;"Мы покупаем([\s\S]*)€"))))
Любуемся результатом:
Два маленьких, финальных штриха. Скрываем колонки C:E. Обращаем внимание, что на исходном сайте отображается две страницы с товарами, и страницы подгружаются динамически.
Попробуем загрузить вторую страницу, добавив параметр page=2 в эдресной строке, как это делается на многих других сайтах. Фокус сработал. На скриншоте видно, что браузер перешел на страницу /page/2.
Теперь нужно аналогичным образом вытянуть данные и по второй ссылке - дописать аналогичную формулу в конце таблицы, или воспользоваться массивом - вместо каждой формулы IMPORTXML подставить конструкцию:
={ <формула для первой ссылки> ; <формула для второй ссылки> }
Т.е. у нас получится такая формула для картинок:
=arrayformula(image(trim("http:"&index(split({IMPORTXML("адрес сайта";"//div[@class=""grid__col--xs-6 grid__col--sm-4""]//figure/span/img/attribute::data-srcset");IMPORTXML("адрес сайта/page/2";"//div[@class=""grid__col--xs-6 grid__col--sm-4""]//figure/span/img/attribute::data-srcset")};","&char(10);true;true);;7))))
И аналогично, формула для столбца B:
={IMPORTXML("адрес сайта";"//div[@class=""grid__col--xs-6 grid__col--sm-4""]//div[@class=""product__meta-box""]"); IMPORTXML("адрес сайта/page/2";"//div[@class=""grid__col--xs-6 grid__col--sm-4""]//div[@class=""product__meta-box""]")}
И вот, готовый результат - таблица из 41 строк:
Саму таблицу вы можете найти по ссылке: https://docs.google.com/spreadsheets/d/1CIOfVun1Q3HTSsqU8Btsuc86K2LyBb4gavZu6qmPHd0/edit
Буду рад вашим вопросам или рекомендациям, как улучшить этот метод :-)