Данный этап кулинарии с данными просто необходим для повышения эффективности моделей машинного обучения. Рассказываю, как проделать этот трюк в самой продвинутой библиотеке - TensorFlow.

Перемешивание данных в Dataset TensorFlow 2 реализуется с помощью метода shuffle, который в качестве параметра принимает размер буфера и равновероятно выбирает из него следующий элемент. На первом этапе в буфер поступает вмещающаяся информация, а затем на место случайно извлекаемых элементов поступают новые. Учитывая эту особенность, от его размера в значительной степени зависит итоговый результат. Поэтому для идеального перемешивания размер должен быть не менее длины Dataset.
Приведем пример. Сначала построчно прочитаем набор данных о пассажирах трагического рейса на Титанике (предварительно сохранен в текстовом файле titanic.csv) с помощью метода tf.data.TextLineDataset (подробнее рассказывал здесь). Затем создадим счетчик tf.data.experimental.Counter(), а также Dataset из строк и их номеров, вызовем shuffle с размером буфера 100 и batch для разбиения данных на пакеты. После извлечем номера строк первого пакета:
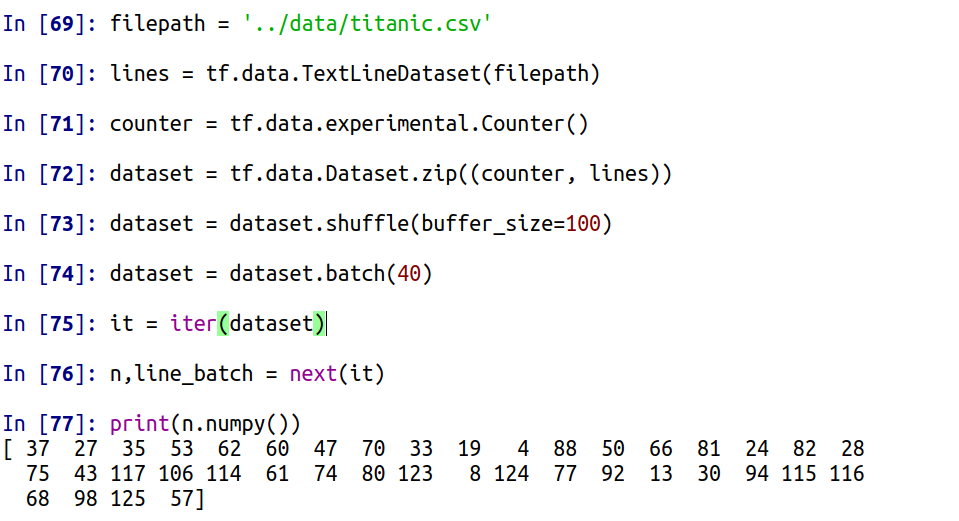
Так как buffer_size равен 100, а размер пакета - 40, в наборе не содержится строк с индексом более 140. Соответственно, второй пакет не содержит индекса более 180, а третий - 220 и т.д..:
Если конвейер данных включает перед перемешиванием метод repeat для организации нескольких проходов по ним (эпох, подробнее читай здесь), то вы не сможете явным образом отделить одну итерацию от другой.
В то же время, если repeat помещается после перемешивания, мы сможем отследить окончание эпохи, когда после первого прохода буфер в shuffle исчерпает все данные:
С учетом количества строк (628) и размера пакета (10), 63 пакет оказался неполным.