Мне интересная тема data engineering, поэтому читаю периодически статьи, смотрю видео и ищу курсы на эту тему. Решила поделиться своим вольным переводом статьи на животрепещущий вопрос для каждого новичка: "Что нужно знать для того, чтобы стать инженером данных?" Это непрофессиональный перевод, у меня всего лишь уровень intermediate в английском, но я надеюсь, что он сможет пригодиться тем, у кого с языком дела обстоят хуже. Замечания приветствуются, но в уважительной форме.
Оригинальная статья. Статья небольшая и написана на среднем уровне английского языка.
Словарь терминов и сокращений:
- Data engineer(DE) - дата инженер, инженер данных.
- ML engineer - инженер машинного обучения.
- Data scientist(DS) - дата саентист, «учёный по данным». Это аналитик, который хорошо понимает математику, строит модели и обучает их предсказывать значения на основании исторических данных.
- Machine learning(ML) - машинное обучение, процесс обучения математических моделей в DS
- Data platform - платформа, система данных. Подход к работе с большими данными.
- Data warehouse(DWH) - хранилище данных.
- Big Data - большие данные. Область работы с данными, которая предполагает большое их количество и, как следствие, другие механизмы обработки, трансформации и анализа.
- Pipeline("трубы") - пайплайн, конвейер данных, по которому данные перетекают из одного состояния и системы в другие.
- Open-source продукт - внутренний продукт компании, который она поддерживает и исходный код которого предоставляет в открытом доступе для использования.
Дальше повествование пойдёт от лица автора оригинальной статьи.
Введение в data engineering
Самые часто задаваемые вопросы
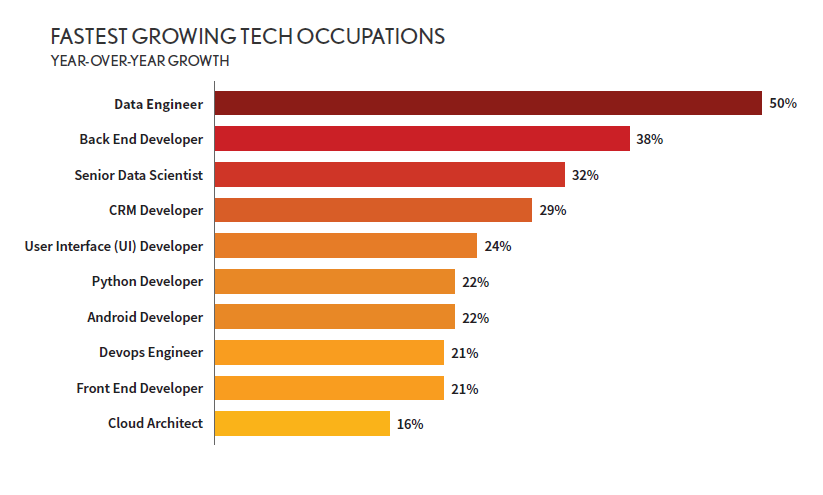
Согласно недавней публикации в Dice 2020 Tech Job Report, data engineer была самой быстрорастущей профессией за 2019 год, количество открытых вакансий на 50% больше, чем в предыдущем году. Data engineering относительно новое направление и люди, которые интересуются им для своей карьеры, часто задают мне вопросы, чем я занимаюсь. В этом посте, я поделюсь своей собственной историей становления дата инженером и отвечу на некоторые часто задаваемые вопросы об этой области.
Мой путь в дата инженеры
Пару лет назад, до того, как стать дата инженером, я, в основном, работал с базой данных и разрабатывал приложения( + масштабировал и тестировал производительность). Мне нравилось работать с RDBMS и данными так сильно, что я решил сосредоточиться на инженерии, которая работает с большими данными(Big Data). После поисков в интернете, я узнал о профессии, о которой раньше не слышал: data engineer. Я растерялся, потому что не знал с чего начать и подойдёт ли это мне. К счастью, у меня был ментор, который помог устроиться на мою первую работу дата инженером. С этого времени и я работаю полный день и люблю этого!
Задай мне любой вопрос
В: Что должен делать дата инженер?
Если кратко, то дата инженер проектирует, разрабатывает и поддерживает платформы данных, которая включает в себя инфраструктуру данных, приложения, хранилище данных(DWH) и конвейеры данных(pipelines).
В больших компаниях, инженеры данных обычно делятся на разные группы для работы над отдельной специфической частью этой платформы.
- DWH и pipelines. DWH инженеры строят порционные и/или real-time(в реальном времени) пайплайны, чтобы интегрировать данные между системами и также поддерживать работу DWH.
- Инфраструктура данных. Здесь инженеры строят и поддерживают базис платформы с данными: распределительные системы, на которых все работает. Например, в Target команда инженеров поддерживает кластеры Hadoop, которые используются во всей организации.
- Приложения для данных. Инженеры в этой группе разрабатывают приложения для интеграции данных и API. Иногда, хорошее внутреннее приложение может стать open-source продуктом компании. Как пример, одна продуктовая команда из Lyft сделала инструмент для поиска данных, который называется Amundsen. Он стал доступен, как open-source, в 2019 году.
В: Что такое data warehouse(DWH)?
Data warehouse - это система хранения, заполняемая данными из разных источников, в основном, она используется для работы аналитиков данных. Данные компании чаще всего хранятся в разных транзакционных системах(или, что хуже, в текстовых файлах), транзакционные данные высоко нормализованы и не подготовлены для анализа. Главная причина строительства DWH в том, чтобы хранить все типы данных в централизованном месте в удобном формате для того, чтобы дата саентисты могли вместе анализировать их. Существует множество баз данных, которые служат для хранения данных, например Apache Hive, BigQuery (GCP), and RedShift (AWS).
В: Что такое data pipeline?
Это серия процессов(конвейер данных), которые извлекают, обрабатывают и загружают данные между разными системами. Есть 2 основных типа пайплайнов: batch-driven и real-time.
- Batch-driven. Пайплайны такого типа только обрабатывают данные с определенной частотой и настраиваются инструментами оркестрации данных, таких как Airflow, Oozie, или Cron. Они обычно обрабатывают большой пакет исторических данных за раз, поэтому требуют много времени для завершения, что вызывает большую задержку в появлении данных в конечной системе. Например, такой пайплайн загружает данные за предыдущий день из API в 12 часов ежедневно, преобразовывает данные и потом загружает в хранилище данных.
- Real-time. Пайплайны в реальном времени загружают новые данные сразу же, как они становятся доступными и нет задержки между источником и конечной системой. Такая архитектура сильно отличается от порционной(batch-driven), потому что данные обрабатываются как поток событий, а не как куски записей. Например, чтобы перестроить batch-driven пайплайна в real-time нужен инструмент потоковой передачи событий, такой как Kafka: транслировать из API будет Kafka Connector и передавать в Kafka topic, потом Kafka Streams (или Kafka Producer) будет трансформировать сырые данные из Kafka topic и загружать измененные данные в другой Kafka topic. Задержка между источником API и конечным Kafka topic может исчисляться секундами!

В: Чем data engineer отличается от data scientist?
Инженер строит платформу для данных, которая позволит data scientist анализировать данные и тренировать модели машинного обучения(ML). Иногда data engineer также может понадобиться для анализа и помочь data scientist интегрировать модель в пайплайн. В некоторых аналитических командах, data scientist занимаются работой инженера. Есть несколько смежных навыков у DE и DS: программирование, построение дата пайплайнов и анализ данных.
Сейчас появляется новая роль, которая называется инженер машинного обучения, который объединяет обе профессии. Инженер ML владеет hard навыками в обоих направлениях и отвечает за оптимизацию и производство ML моделей.
В: Чтобы стать data engineer какой язык программирования нужно изучить?
Если коротко: Python, Java/Scala, и SQL.
Для отслеживания работы приложений вам также нужно выучить обычный язык программирования для full-stack разработчика, т.е. HTML, CSS, and JavaScript.
мысли переводчика: эти языке же для front-разработчика нужны, но в сочетании с знаниями Python, SQL получается full-stack, наверное это имел в виду автор.
В: Какие навыки и инструменты мне нужно уметь и знать?
Вот список основных навыков и один из популярных фреймворков:
- Система доставки данных: Hadoop
- База данных: MySQL
- Платформа для обработки данных: Spark
- Real-time экосистема данных: Kafka
- Инструмент оркестрами данных: Airflow
- Full-stack разработка: React
Т.к в мире больших данных больше не существует универсальных решений, каждая компания использует разные инструменты для своей платформы с данными. Поэтому, я рекомендую вам для начала получить базовые знания основных навыков, потом выбрать популярный инструмент для глубокого изучения и понять разницу между тем, что вы выбрали и другими инструментами. Чтобы перейти на новый уровень, вам также понадобятся знания того, как все инструменты работают вместе в архитектуре данных.
На сегодняшний день около 1,7 МБ новых данных генерируется человеком каждую секунду и эти данные хранят огромное значение, которое не может быть собрано без дата инженера. Инженеры данных помогают людям принимать правильные решения, поэтому я люблю свою работу так сильно)
Не стесняйтесь и дайте мне знать, если у вас есть еще вопросы, связанные с data engineering or data science!
Автор перевода: я постараюсь еще переводить новые статьи по теме data engineering. Если есть какие-то темы либо же статьи, то скидывайте в комментарии, попробуем вместе разобраться!