Источник: Nuances of Programming
Основанная на микросервисах инфраструктура Soluto, совмещенная со всеми инструментами CI/CD, позволяет осуществлять по несколько релизов в день, предоставляя пользователям новые возможности и внося исправления.
При таком быстром темпе иногда уже после релиза в производственной среде могут проскакивать ошибки. В таких случаях нужно защитить клиентов от негативного влияния этих ошибок и в то же время обнаружить их как можно раньше. Именно здесь на арену выходит Argo Rollouts, предлагающий поддержку стратегии canary-релизов.
Примечание
Существует множество руководств по настройке процесса canary-релизов в кластере K8s. Эта же статья не из разряда “Как сделать то или иное…”, она предполагает, что вы уже знаете принцип работы Argo Rollouts и содержит информацию о доступных вариантах, возможных проблемах и оптимизациях, которые помогут повысить эффективность процесса релизов. Вы можете либо прочесть ее целиком для наилучшего понимания темы, либо сразу перейти к разделам “Краткого содержания” и “Усвоенных уроков”, сэкономив время.
Чего стоит ожидать от canary-релизов?
Реализация данной стратегии преследует следующие цели:
“При каждом очередном развертывании сохранять работоспособность предыдущей версии и давать нововведению время для проверки работоспособности в производственной среде с минимальным воздействием на клиентов”.
Это означает, что нам нужно:
- Выполнять в производственном кластере K8s две версии сервиса одновременно.
- Разделять производственный трафик между этими двумя версиями контролируемым образом.
- Автоматически анализировать, насколько хорошо работает новая версия.
- Автоматически сменять версии или выполнять откат на основе предыдущего анализа.
Argo Rollouts
Для создания canary-релизов существуют такие решения, как flagger, который, кстати, подразумевает слияние с Argo Rollouts, но мы выбрали именно Argo по следующим причинам:
- Наличие поддержки разделения трафика без использования поставщика сетки для внутреннего трафика, не проходящего через Ingress.
- У нас был Argo CD, с которым данная технология отлично интегрируется. Подробнее об этом будет сказано чуть позже.
Это означает, что если у вас нет поставщика сетки (Istio), то Argo Rollouts разделяет трафик между версиями, создавая новый набор реплик, использующий тот же объект сервиса. При этом данный сервис по-прежнему будет разделять трафик между старыми и новыми подами поровну. Другими словами, управляя числом подов, мы контролируем процент трафика.
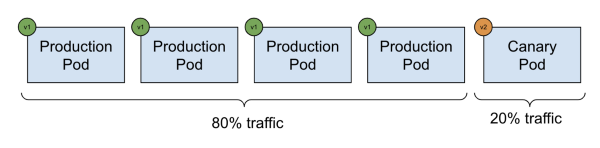
Это не идеальный вариант, но с задачей справляется. Если же у вас есть Istio, то вы можете контролировать трафик более эффективно, о чем можно прочитать в документации здесь.
Реализация
Жизненный цикл canary
Держа во внимании наши задачи, мы начинаем представлять желаемое поведение canary-процесса:
- У нас уже есть развернутая в производственной среде версия N.
- Версия N+1 была развернута как canary-релиз.
- Теперь у нас есть версии N и N+1, и мы выделяем для N+1 определенный процент трафика.
- Ждем некоторое время.
- Оцениваем, насколько хорошо работает N+1.
- Если работает она хорошо, увеличиваем для нее трафик и переходим к этапу 4.
- Если же она работает плохо, удаляем ее и снова переводим весь трафик на N.
- Повторяем шаги с 4 по 7 до тех пор, пока весь цикл анализа не даст желаемый результат, после чего переключаем весь трафик на N+1 и удаляем N.
Написание реального и практичного анализа canary
Комбинация Rollout и AnalysisTemplate в Argo Rollouts дает достаточную гибкость при настройке стратегии canary-релизов подобно описанной выше в отношении этапов, контроля трафика и анализа. Но что же такое хорошая стратегия? На этот вопрос нет универсального ответа, все зависит от конкретного случая. Ниже описан процесс формирования подходящего варианта для нашего случая. Он может подойти и вам, по меньшей мере в качестве примера.
С самого начала мы поставили перед собой следующие вопросы:
Какой процент трафика стоит выделить canary?
Если он будет слишком мал, canary не получит достаточно трафика, и результат анализа будет недостоверным. Если же трафика будет слишком много, то в случае возникновения сбоя, пострадает много клиентов. Другими словами, canary-релиз должен обрабатывать от 5 до 10% всего трафика.
Как долго стоит выполнять анализ?
Чтобы метрики статистического анализа были достоверными, нужно не менее 50 точек данных для получения хороших результатов, т.е. необходимо делать паузу на время, требуемое системе мониторинга (Ptometheus, DataDog и т.д.) для сбора метрик по меньшей мере 50 раз. Это время может варьироваться в зависимости от настройки, но в нашем случае мы добились сбора метрик каждые 15 секунд, т.е. минимальное время приостановки составляло около 12,5 минут при наличии активных пользователей, генерирующих трафик.
Сколько этапов нужно включить?
Однозначно ответить на этот вопрос нельзя, но наши разработчики не хотели тратить время на ожидание, пока что-то пойдет не так, к тому же нам нужно было оградить клиентов от возможных сбоев.
Первый шаг (Fail Fast): если в новом релизе присутствует очевидная проблема, разработчики не хотели дожидаться полного завершения анализа, чтобы ее обнаружить. Нам нужно было что-то, что может сообщить о неработоспособности кода очень быстро, поэтому анализ для первого этапа был таким:
- 5% трафика;
- 13 минут приостановки (также 50 точек данных);
- оценка метрик и либо удаление canary, либо переход к следующему этапу.
Этапы 2 и 3 идентичны: 10% трафика при продолжительности 30 минут.
Такой вариант выглядел оптимальным. При общем времени выполнения канарейки в 1,25 часа ждать приходилось недолго. Однако, как выяснилось, такая конфигурация оказалась недостаточно хороша. Причины можете прочесть в разделе “Усвоенные уроки”.
Как узнать, что происходит?
Чтобы увидеть, что происходит при выполнении canary-релиза, можно использовать любое из этих средств:
- Argo Rollouts kubectl plugin: предоставляет хорошо отформатированный вывод о состоянии canary.
- Argo CD: если вы используете этот инструмент, то уже знаете, что у него приятный UI, показывающий состояние приложения внутри кластера. Если же совместить этот инструмент с релизами, то с помощью красочного UI можно наблюдать происходящее в реальном времени.
- Metrics: да, Argo Rollouts раскрывает метрики, с помощью которых можно создавать панели, чтобы демонстрировать состояние всех релизов таким вот образом:
Какие метрики нужно измерять?
У нас есть два типа сервисов:
- Сервисы API (http): показывают API, вызванные при помощи http-протокола.
- Сервис-работники: получают сообщение из системы очередей вроде pub/sub kafka и т.д.
В обоих случаях нужно измерить:
- Показатель успеха — процент успешных операций должен превышать 95%.
В API это отношение 2хх ответов к их общему числу. В сервис-работнике это уже сложнее, так как в нем нет http-вызовов. Как же в этом случае измерить показатель успешности?
- Задержка — длительность выполнения операции до завершения.
В API это общее время от начала запроса до возвращения ответа. В сервис-работнике это общее время от получения сообщения до его обработки и подтверждения.
Для максимального выравнивания метрик между API и сервис-работником мы привлекли факт использования в работнике шаблона Sidecar, который выполняет потребление из очереди и вызывает основной сервис при помощи http:
Таким образом происходит преобразование основного сервиса в http-сервис, в котором можно использовать те же метрики, что и в API.
Краткие выводы
Мы позволили разработчикам использовать технику Canary-релизов в течение нескольких месяцев и наблюдали. Она спасала ситуацию немало раз, но не всегда. Да, всему виной была короткая продолжительность выполнения и ряд других факторов, которые объясняются ниже.
Усвоенные уроки
Canary-релизам нужно больше трафика
Да, чем больше трафика, тем больше операций, а больше операций означает более точный анализ. В нашем случае часовой пояс клиентов не совпадал с предусмотренным релизами, поэтому при выполнении они не получали нужного объема трафика. В итоге мы на собственном опыте поняли, что проблемы проще обнаруживать, если анализ выполняется при более высокой активности клиентов.
Для преодоления этой сложности анализ canary должен выполняться во время повышенного трафика, поэтому для лучшего обнаружения неполадок продолжительность этого анализа должна быть не менее 24 часов.
Возможность пропускать анализ canary
Когда в производственной среде возникают проблемы, требующие срочного устранения, мы не можем ждать 24 часа до выпуска исправления. Поэтому в конвейерах CD мы добавили опцию пропуска анализа canary при релизе. Эта опция стала удачным дополнением для подобных случаев.
Взвешивание операций при анализе
Например, если нам нужно, чтобы показатель успешности был выше 95%, то для его вычисления используем следующий prometheus-запрос:
sum(increase(http_request_duration_seconds_count{status_code=~"2.*"}[15m])) / sum(increase(http_request_duration_seconds_count[15m]))
Как видите, он суммирует запросы всех конечных точек, но некоторые из этих точек вызываются чаще других. Это не значит, что они более важны, но в этом запросе конечные точки, вызываемые реже, не оказывают такого же эффекта на итоговый процент.
В связи с этим возникает необходимость изменить запрос, представив его в виде взвешенной суммы каждой конечной точки. Например, рассмотрим две из них:
Поскольку getAnotherThing получает меньше трафика, чем getSomething, мы увеличили ее влияние на конечный результат. Это хорошо в плане чисел, но итоговый запрос может оказаться очень сложен в обслуживании, поэтому применяйте данный метод обдуманно.
Краткое содержание
После выполнения процесса canary-релиза в кластерах kubernetes при помощи Argo Rollouts на протяжении нескольких месяцев, наблюдая и собирая обратную связь, мы выработали ряд его оптимизаций:
- Нагрузка, направляемая на canary, должна составлять от 5 до 10% от общего объема трафика.
- Использование шаблона Sidecar помогает унифицировать метрики, используемые в сервисах.
- Лучше выполнять анализ canary более продолжительное время, охватывая периоды повышенного трафика, т.е. не менее 24 часов.
- Для уменьшения недовольства разработчиков в первом этапе анализа может применяться техника “Fail Fast”, в которой продолжительность анализа определяется минимальным количеством времени, необходимым системе мониторинга для сбора 50 точек данных из метрик, предоставляемых сервисом. Обычно это 50 минут, но при возможности выполнять сбор каждые 15 секунд этот промежуток сокращается до 13 минут.
- Чем больше трафика, тем лучше. Следует стараться делать релизы в пиковые часы использования сервиса. Если же это невозможно, то либо симулируйте больше трафика, либо увеличивайте продолжительность анализа, как указывается в пункте 3.
- Если можете, выполняйте анализ, будь то запрос Prometheus или другие, в виде суммы веса каждого API/операции, а не в виде общего среднего значения, поскольку некоторые конечные точки вызываются реже, но при этом являются равно важными.
- Держите разработчиков в курсе о состоянии их релиза, создав в Grafana панели, показывающие это состояние наряду с уведомлениями.
- В завершении предоставьте разработчикам возможность пропускать анализ canary при новых релизах. Это особенно полезно при срочных исправлениях багов в производственной среде, которые не могут ждать несколько дней до развертывания релиза.
Рекомендуется следовать этим инструкциям, чтобы добиться от canary-релизов оптимальной отдачи. Конечно же, вам также следует улучшать и подстраивать их под собственные случаи, поскольку при реализации canary не существует единого универсального порядка.
Читайте также:
Перевод статьи Sari Alalem: Practical Canary Releases in Kubernetes with Argo Rollouts