Как можно использовать теорию вероятности при анализе цены? Для многих людей теория вероятностей представляется сложным и непонятным разделом математики. Наверное, поэтому те, кто сталкивается с анализом цены используют готовые формулы, не пытаясь разобраться в их смысле. В этой статье мы попытаемся применить теорию вероятности, причем сделаем это максимально наглядно. С другой стороны, те, кто анализирует цены может использовать, описанный способ, при этом понимая, что он делает.
Постановка цели
Здесь мы попытаемся математическими методами определить вероятность отклонения цены определенного финансового актива за неделю. Для примера возьмем самый торгуемый фьючерс на 10-летние казначейские облигации США тикер ZN (TY). В качестве дополнительной цели мы попытаемся определить наиболее вероятный диапазон цен за неделю.
Получение данных
Для этого нам потребуется данные максимум и минимум цен за неделю в течение 5 лет. Чем больше выборка, тем точнее будет результат вычисления вероятностей. Нужные нам данные мы можем получить с сайта investing.com.
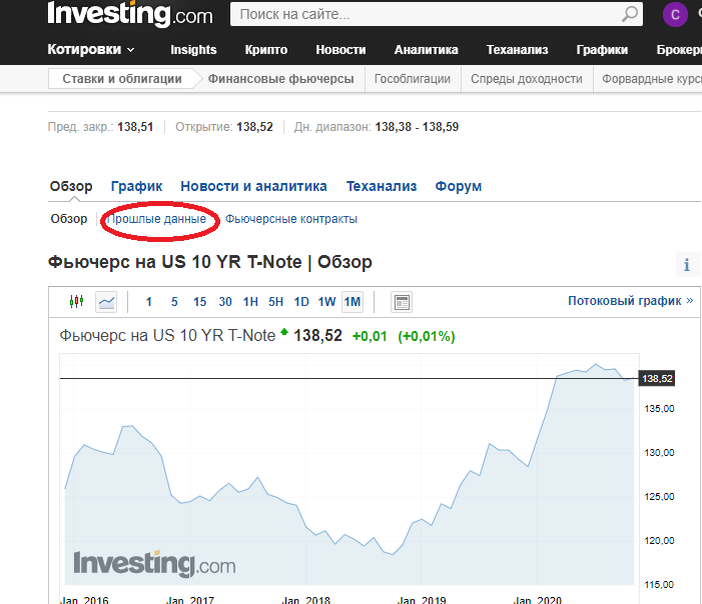
Щелкнув по "Прошлые данные" (на рисунке обведены красным овалом), вы перейдете на страницу, где нужно установить "Временной период" неделя, а диапазон с 01.01.2016 по текущую дату. После чего можно скачать данные, нажав на соответствующую кнопку. Вы получите текстовый файл, который следует особым образом загрузить в Excel. Если у вас возникнут проблемы, например, вы используете браузерный редактор электронных таблиц, в котором нет возможности загружать данные из текстового файла, то вам готовый файл Excel. Импорт данных из текстового файла можно осуществить, например, через меню "Данные" -> "Из текста". В результате в получите такое диалоговое окно.
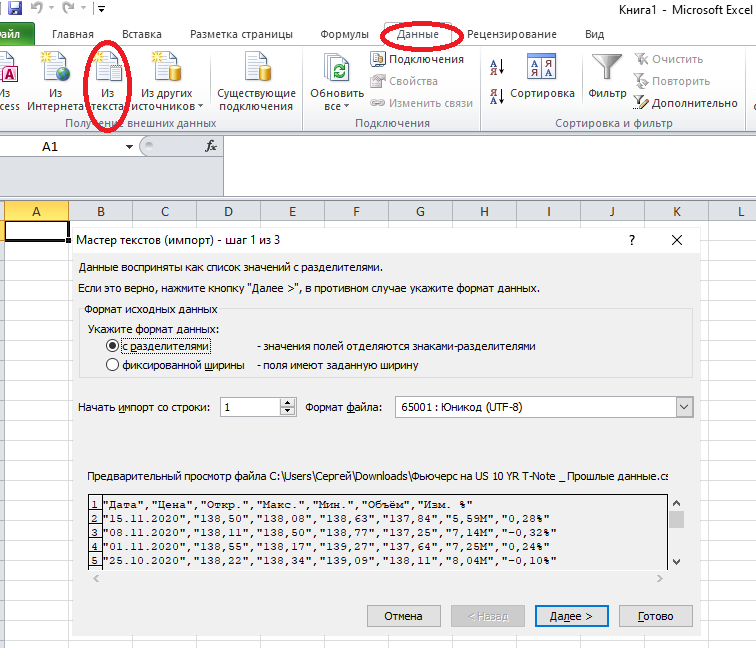
Должно быть выбрано "с разделителями", нажимаем "Далее". Символом-разделителем должна быть запятая, после чего вы увидите правильное разбитие на колонки.
На следующем шаге можно выбрать формат даты для первой колонки, и можно завершить импорт, нажав кнопку "Готово".
Расчет волатильности за неделю
Существует несколько определений волатильности, но нам, исходя из цели, нужна волатильность High-Low. Которая рассчитывается как разница между максимумом и минимумом выбранного таймфрейма. В ячейке H1 введем заголовок HLV (сокращение High-Low Volatility). В H2 введем формулу "=(D2-E2)*2/(D2+E2)". Смысл этой формулы в определении разницы между максимумом и минимумом, выраженное в доле от полусуммы (поделенное на половину суммы). То же самое можно сделать в несколько шагов: сначала разницу ("=D2-E2"), потом определить знаменатель ("=(D2+E2)/2"), ну и наконец определить долю ("=I2/J2"). Скорее всего, вы уже догадались, что все значения будут положительными и в диапазоне от 0 до 1. Нулевые значения будут означать очень странный случай, когда максимум будет равен минимуму. Еще более странным будут значения выше 50%.
Такой подход к расчету удельной волатильности является нестандартным, но его можно легко и понятно объяснить. Использование доли устраняет погрешность размерности актива, то есть позволяет сравнивать активы с разной размерностью (тысячи, сотни, десятки, единицы). Еще важнее сравнивать один и тот же актив в глубокой исторической перспективе. Например, индекс S&P500 в 90-х годах измерялся в сотнях, а сейчас в тысячах. Существуют методы расчета, использующие в качестве знаменателя среднее значение за определенный временной промежуток, например, среднее из 200 последних значений. На первый взгляд такой подход будет более точным, далее мы убедимся, что это не так.
Для наглядности следует использовать процентное представление вместо долевого. Можно изменить формулу, а можно задать для ячейки процентный формат. Для этого надо щелкнуть правой кнопкой мыши на нашей ячейке (H2), из контекстного меню выбрать "Формат ячеек...". На первой вкладке ("Число") выбрать в списке "Числовые форматы" пункт "Процентный". Распространим нашу формулу на все строчки. Для этого подведите указатель мыши в правый нижний край ячейки H2 (где у нас готовая формула) так, чтобы указатель мыши сменился на черный крестик. Удерживая позицию (черного крестика), сделайте двойной щелчок, таким образом формула распространится по всем строчкам.
Гистограмма распределения
Мы получили более двух сотен значений удельной волатильности. Теперь нам надо как-то определить частоту разных значений этой самой волатильности. Для этого мы воспользуемся инструментом "Анализ данных". По умолчанию он не включен. Если на вкладке "Данные" вы не увидите "Анализ данных", то вам надо включить надстройку "Анализ данных". Если не знаете как это сделать, то поищите в интернете. Тем, кто пользуется браузерным редактором электронных таблиц придется скачать готовый файл в конце статьи, потому что в нем не предусмотрен такой функционал (или я не знаю, как это сделать).
Нажмите "Анализ данных", в появившемся диалоговом окне в списке выберите "Гистограмма". В следующем диалоговом окне надо задать "Входной интервал". Это весь массив данных волатильности, который мы рассчитали. Для указания входного интервала, не закрывая диалогового окна, щелкните мышкой в ячейку H2 (начало интервала), зажмите одновременно клавиши Shift и Ctrl, не отпуская их нажмите третью клавишу стрелка вниз, после чего отпустите все клавиши.
Щелкните мышью "Выходной интервал", после чего щелкните в поле выходного интервала. Если вы этого не сделаете, то активным останется поле входного интервала и все изменения будут применяться к нему. Выделите ячейку J1, и поставьте галочку напротив "Вывод графика", нажмите кнопку "ОК". Последняя галочка нужна для графического представления частоты распределения.
Анализ распределения
Если вы знаете, что такое нормальное распределение, то даже по графическому представлению вы видите, что цены никак не хотят влезать в это прокрустово ложе. Для тех, кто не знает или забыл про нормальное распределение, следует отметить, что большинство цен группируется в небольшом диапазоне, но есть небольшое количество случаев, когда цены отклоняются слишком сильно. Следовательно, нам надо определить диапазон "нормальности" и вероятность "ненормальности".
Для этого нам потребуется еще две колонки. Если вам будем мешать график, то его можно выделить и удалить (или перенести). В первой колонке мы будем считать вероятность отклонения, как отношение случаев отклонения на общее количество. Последний параметр можно посчитать суммируя все значения в колонке "Частота" (К). Для этого в ячейку K18 введите формулу "=СУММ(K2:K17)".
Это же значение можно получить, посчитав общее количество недель в, рассматриваемом нами, временном диапазоне. И в том и в другом случае получилось значение 255. В ячейке L1 вводим заголовок "Вероятность", в L2 формулу "=K2/$K$18". Знаки доллара закрепляют ячейку, то есть при смещении формулы знаменатель будет оставаться одним и тем же. Более простой вариант: прописать значение 255 прямо в формуле. Вероятность также удобнее представлять в виде процентов, поэтому повторите операцию применения процентного формата. После чего распространите формулу на все значимые ячейки этой колонки.
Если вы сложите проценты диапазона L2:L8, то получите почти 96,5% вероятности нахождения цены в диапазоне до 2%. Чуть более 3,5% вероятности, что цена скакнет на величину более 2%. Что дают вам подобные расчеты? Выводы вы сделаете сами, когда придет осознание этих цифр. Например, одним из выводов может быть такой: существует некая вероятность закрытия по маржинколу позиций без стоп-лосса. Точное значение зависит от размера вашего депозита, размера вашей позиции.
А у нас с вами осталась еще одна колонка, которую мы назовем "Матожидание" (сокращение от математическое ожидание). Считается оно как произведение вероятности на величину (величина располагается в колонке "Карман"). То есть формула будет такой "=J2*L2". Максимальное значение матожидание имеет при 1% отклонении. Дальше матожидание снижается. Это означает, что наиболее вероятный диапазон движения этого актива составляет чуть более 1% в неделю.
Окончательный файл со всеми расчетами вы можете скачать здесь. В нем намеренно удалена графическая гистограмма распределения, которую вы можете построить с помощью мастера диаграмм.