Всем привет! Приступим сразу к делу :)
Как известно, компьютеры хранят информацию в виде байтов (1 байт - 8 бит :)). Поэтому необходимо было придумать систему, которая бы позволила сопоставить используемые пользователями символы (буквы любого алфавита, цифры, греческие символы, значки доллара и евро и т.д.) с целыми положительными числами (кодом символа).
В 60-х годах прошлого века, на заре развития вычислительной техники в американском национальном институте стандартизации (ANSI) была разработана таблица кодирования символов, которая затем стала использоваться во всех операционных системах. В ней каждому конкретному символу был поставлен в соответствие байт с конкретным значением. Эта таблица называется ASCII (American Standard Code for Information Interchange) и представлена ниже.
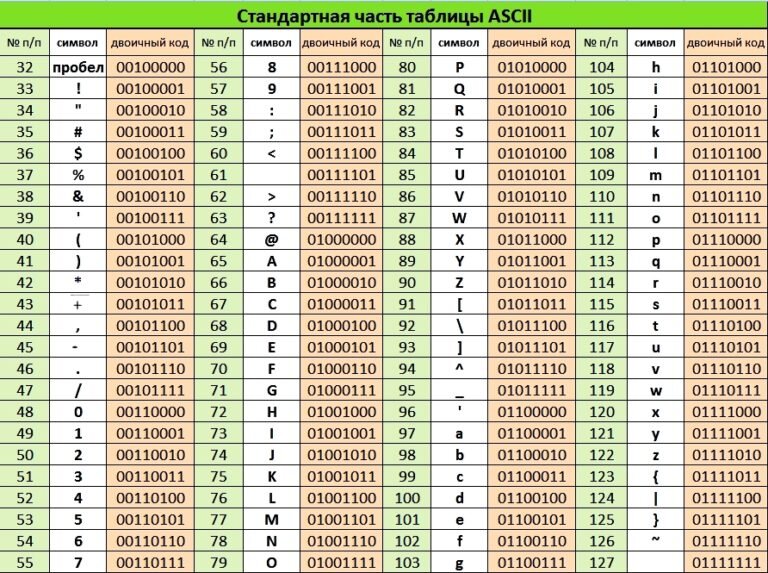
Мы видим, что 7-битная кодировка позволяет закодировать 128 символов (2^7). Однако помимо английского существует ещё 7173 языка в мире. Возникла потребность в разработке кодировок, использующих большее количество битов. Например, почитайте здесь об истории развития кодировок ISO-8859.
Однако большое количество кодировок, как и большое число языков в мире создает некоторые неудобства при общении :). Поэтому было решено придти к единой кодировке. Так появилась кодировка Юникод. В настоящее время определено уже более 1 млн символов Юникода. Ниже приведу две наиболее популярные кодировки Юникода:
- Кодировка UTF 8. Очень удобна и компактна для написания английского текста. и если в нем используются только символы из набора ASCII, то файлы с текстом в кодировке UTF 8 ничем не отличаются от файлов в кодировке ASCII.
- Кодировка UTF 16. В ней для кодирования значительной части символов используются два байта и для остальных – четыре байта.
Теперь поговорим немного о метод str.encode(). Данный метод кодирует строку в байты/байтстроку, используя зарегистрированный кодек.
Строки 14-18 - то, что получилось. Мы видим, что в кодировке ascii нет русских букв, так что если бы я не использовал "replace" (замена чего нет на знаки вопроса) или "ignore" (игнорирование символов, которых нет в используемой кодировке, питон выдал бы ошибку: UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-2: ordinal not in range(128)
Декодировать строку можно с использованием метода bytes.decode(). Например, чтобы получить кота, нужно прописать:
print(b'\xd0\xba\xd0\xbe\xd1\x82'.decode())
На этом всё, спасибо, что подписываетесь и дочитываете :)