Задача зачем, и что за контент, я описывал в своей статье "Нейросеть для ведения канала". В рамках же этого материала, хочу более подробно остановиться на технической стороне вопроса, что потребовалось, как организовано и т.п. Советую прочитать сначала ту статью, потом вернуться к этой, так будет более понятно, на мой взгляд.
Технологический стек
Для этой задачи я решил применять такие технологии:
#typescript
#docker
#BrainJs
#kafka
Схему приведу еще раз, для наглядности:
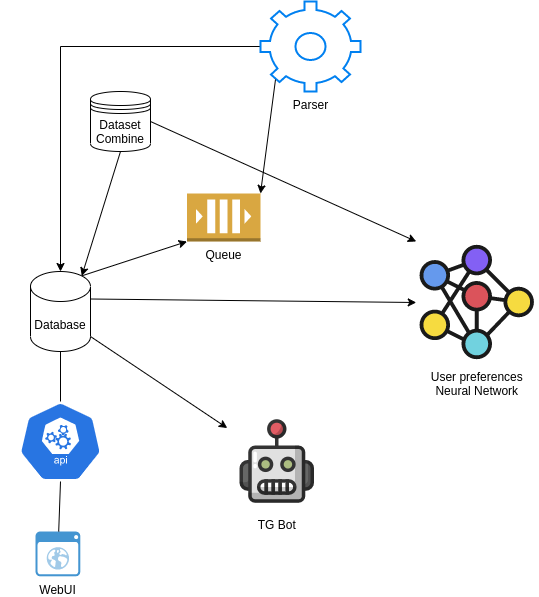
Почему Typescript? Да потому что Python я не знаю, а Typescript уже знаком, а другие языки имеют еще меньший выбор библиотек для машинного обучения.
Docker, потому что удобно развернуть микросервисы прямо у себя на локальном компьютере.
BrainJS. Сложно ответить почему он, а не например TensorFlow, и ответ простота правдивый и не совсем. Скажем так, для такой простой задачи, как спрогнозировать число от 0 до 1 при нескольких десятках входных параметров очень хорошо подходит BrainJS, с ним легче начать, но если нужна визуализация данных обучения, то лучше сразу брать TensorFlow. Не претендую в данном случае на истинность высказывания, это чисто мое субъективное мнение.
Kafka. Ну я люблю два брокера, RabbitMQ и Apache Kafka. В данном случае у меня просто уже были контейнеры с настроенной "кафкой" и "зоокипером", а также проверенная библиотека для работы с Кафкой для TypeScript, это KafkaJs.
Подготовка данных
Итак как я уже и сказал, в BrainJS легко начать. К сожалению ЯндексДзен не позволяет вставлять красиво подсвеченный код, поэтому вставлю скриншотом, сделаным прямо из официальной документации BrainJS ля механизма XOR:
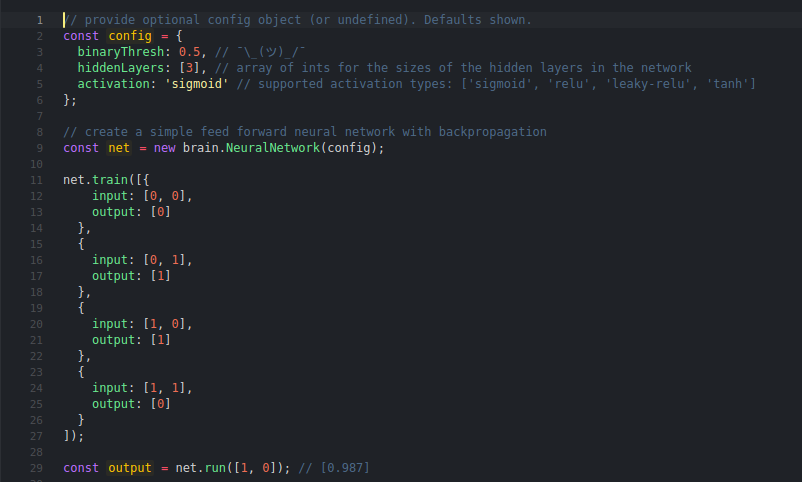
Вот наш пример обучения на тегах почти такой же простой, только данных в `input` будет побольше, т.е. побольше входных параметров, а выход одно значение от 0 до 1. Или можно даже округлить все либо до 0, либо до 1.
Готовим Датасет
Мы определились, что у нас оценка контента будет происходить по следующим параметрам:
- Теги контента
- Академическая тошнота
- Водность текста
Для начала их достаточно, потом можно еще какие-то корректирущие коэффициенты подставить, в зависимости от тематики и целей. Можно, например использовать Фог-Индекс, индекс Флеша, классическую тошноту или какие-либо еще показатели.
Про то как посчитать Тошноту, водность или приведенные мною индекса, я писать не буду, информации много. Просто формулы по сути. А вот теги уже используют по разному и я расскажу о способе, который я применил.
На контенте, который публикуется на моем канале, имеется 2-4 тега. Итак в базе мы имеем например 100 тегов всего, и 2, 3 или 4 тега у каждого контента по отдельности. Т.е. как мимнимум в массив `input` мы можем сложить 100 чисел, 1 на тех местах, где в нашем контенте есть тег, и 0 - где нет, соответственно. Главное, чтобы порядок тегов был везде одинаковый. Поэтому, для обучения и сборки датасета, мы сначала получим теги, они уже будут отсортированы в каком-то порядке, например по id или по названию в алфавитном порядке. Это не имеет особого значения как именно, можно так SELECT id, name FROM tags ORDER BY id ASC
Далее получаем весь контент, который будет анализироваться. Т.е. нам нужен контент, который был опубликован в канале, и у него есть реакции пользователей. Собираем весь, вместе с тегами, если они в разных таблицах как у меня, лучше это делать пачками, чтобы не перегружать базу. Далее каждый контент в датасет собираем через цикл:
Так у нас получится массив, со 100 числами (по количеству тегов) где все 100 мест будут заняты 0 и 1. Остальные показатели так же Push'им в этот же массив. Главное это порядок чисел в массиве, он должен сохраняться для всех статей в анализе.
Ну и последний момент, мы должны записать что то в data.output для каждого. Это и будет показатель, к которому должна стремиться нейросеть при обучении. Когда данных мало, лучше, если в этом массиве будет или 0 или 1. Поэтому я сделал следующее:
- Считаем отношений лайков к общему числу реакций
например, всего 17 реакций из них 11 лайков:
11 ÷ 17 ≈ 0,65 - Определяем условие, например, если коэффициент > 0,6 пишем 1
иначе 0
Сразу скажу приводить ответ к 1 или к 0 не очень. Будет некая порывистость у обученной модели, но это спасает на начальных этапах, когда мало данных. Когда данных достаточно, можно в качестве ответа использовать непосредственно сам коэффициент 0,65 вместо 1, это будет точнее и лучше, но к этому еще нужно прийти.
Собственно всё. В BrainJS мы можем запустить net.train() с этим датасетом и он обучит нейронку. Для начала можно сделать так:
Т.е. практически все параметры дефолтные, только функцию активации, используем сигмоиду. И да сразу показываю, что можно сохранить модель в JSON для дальнейшего использования.
После этих "танцев" можно сделать скрипт прогнозирующий контент. Здесь код не буду приводить, но суть простая, вы пакетно получаете контент из базы данных, и делаете прогноз для каждой статьи на основе сохраненной обученной модели. В зависимости от того, какая будет средняя арифметическая оценка и какие вообще вы увидите числа, вы поймете, насколько хорошо обучена модель нейросети. Для проверки можно взять любой контент который очевидно понравился почти всем вашим подписчикам и заставить модель сделать прогноз на него. Если прогноз будет близок к 1, значит обучение не прошло в пустую.
Эту спрогнозированную оценку для неопубликованного контента можно использовать как параметр публикации. И если нейросеть обучена достаточно хорошо, вы можете публиковать контент, например только с рейтингом оценки > 0.90. При этом продолжать получать реакции пользователей и переодически переобучать ее. Я это повесил на Cron, и у меня переобучение происходит раз в 2 дня.
Пишите комментарии, что добавить, что плохо рассказал, может что-то хотелось увидеть подробней, или где то я налил много воды, я люблю конструктивную критику.