
В этой статье мы рассмотрим нейронные сети, чтобы узнать, как их построить с нуля.
Одна вещь, которая меня больше всего волнует в глубоком обучении, - это возиться с кодом, чтобы создать что-то с нуля. Однако это непростая задача, а научить этому кого-то еще труднее.
Я прошел курс Fast.ai, и этот блог очень вдохновлен моим опытом.
Без промедления давайте начнем наше чудесное путешествие по демистификации нейронных сетей.
Как работает нейронная сеть?
Давайте начнем с понимания высокоуровневой работы нейронных сетей.
Нейронная сеть принимает набор данных и выдает прогноз. Это так просто.
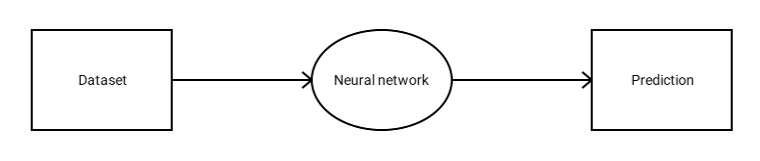
Позвольте привести пример.
Допустим, один из ваших друзей (который не является большим футбольным фанатом) указывает на старую фотографию известного футболиста - скажем, Лионеля Месси - и спрашивает вас о нем.
Вы сможете опознать футболиста за секунду. Причина в том, что вы уже тысячу раз видели его картины. Так что вы сможете опознать его, даже если снимок старый или был сделан при тусклом свете.
Но что будет, если я покажу вам фотографию известного бейсболиста (а вы никогда раньше не видели ни одной бейсбольной игры)? Вы не сможете узнать этого игрока. В этом случае, даже если картинка четкая и яркая, вы не узнаете, кто это.
Этот же принцип используется для нейронных сетей. Если наша цель - создать нейронную сеть для распознавания кошек и собак, мы просто показываем нейронной сети набор изображений собак и кошек.
В частности, мы показываем нейросети изображения собак, а затем говорим, что это собаки. А затем покажите ему фотографии кошек и определите их как кошек.
Как только мы обучим нашу нейронную сеть изображениями кошек и собак, она сможет легко определить, содержит ли изображение кошку или собаку. Короче говоря, он может отличить кошку от собаки.
Но если вы покажете нашей нейросети изображение лошади или орла, она никогда не идентифицирует это как лошадь или орла. Это потому, что он никогда раньше не видел изображения лошади или орла, потому что мы никогда не показывали ему этих животных.
Если вы хотите улучшить возможности нейронной сети, то все, что вам нужно сделать, это показать ей изображения всех животных, которых вы хотите, чтобы нейронная сеть классифицировала. На данный момент он знает только кошек и собак и ничего больше.
Набор данных, который мы используем для обучения, во многом зависит от стоящей перед нами проблемы. Если вы хотите классифицировать, имеет ли твит положительное или отрицательное настроение, то, вероятно, вам понадобится набор данных, содержащий множество твитов с соответствующей меткой как положительный или отрицательный.
Теперь, когда у вас есть общий обзор наборов данных и того, как нейронная сеть учится на этих данных, давайте углубимся в то, как работают нейронные сети.
Понимание нейронных сетей
Мы построим нейронную сеть, чтобы классифицировать цифры три и семь на изображении.
Но прежде чем строить нейронную сеть, нам нужно глубже понять, как они работают.
Каждое изображение, которое мы передаем в нашу нейронную сеть, представляет собой просто набор чисел. То есть каждое из наших изображений имеет размер 28 × 28, что означает, что оно имеет 28 строк и 28 столбцов, как и матрица.
Мы видим каждую цифру как законченное изображение, но для нейронной сети это просто набор чисел от 0 до 255.
Вот пиксельное представление цифры пять:
Как вы можете видеть выше, у нас есть 28 строк и 28 столбцов (индекс начинается с 0 и заканчивается на 27), как и матрица. Нейронные сети видят только эти матрицы 28 × 28.
Чтобы показать больше деталей, я просто показал оттенок вместе со значениями пикселей. Если вы присмотритесь к изображению, вы увидите, что значения пикселей, близкие к 255, темнее, тогда как значения, близкие к 0, светлее по оттенку.
В PyTorch мы не используем термин «матрица». Вместо этого мы используем термин тензор. Каждое число в PyTorch представлено в виде тензора. Итак, с этого момента мы будем использовать термин тензор вместо матрицы.
Визуализация нейронной сети
Нейронная сеть может иметь любое количество нейронов и слоев.
Так выглядит нейронная сеть:
Пусть вас не смущают греческие буквы на картинке. Я вам это разобью:
Возьмем случай прогнозирования того, выживет ли пациент или нет, на основе набора данных, содержащего имя пациента, температуру, артериальное давление, состояние сердца, ежемесячную зарплату и возраст.
В нашем наборе данных только температура, артериальное давление, состояние сердца и возраст имеют важное значение для прогнозирования выживет пациент или нет. Таким образом, мы присвоим этим значениям более высокое значение веса, чтобы показать более высокую важность.
Но такие особенности, как имя пациента и ежемесячная заработная плата, практически не влияют на выживаемость пациента. Поэтому мы назначаем этим функциям меньшие значения веса, чтобы показать меньшую важность.
На приведенном выше рисунке x1, x2, x3 ... xn - это функции в нашем наборе данных, которые могут быть значениями пикселей в случае данных изображения или таких функций, как артериальное давление или состояние сердца, как в приведенном выше примере.
Значения признаков умножаются на соответствующие значения веса, обозначаемые как w1j, w2j, w3j ... wnj. Умноженные значения суммируются и передаются на следующий уровень.
Оптимальные значения веса узнаются во время обучения нейронной сети. Значения весов постоянно обновляются таким образом, чтобы максимально увеличить количество правильных прогнозов.
В нашем случае функция активации - это не что иное, как сигмовидная функция. Любое значение, которое мы передаем сигмоиду, преобразуется в значение от 0 до 1. Мы просто помещаем сигмоидальную функцию поверх нашего прогноза нейронной сети, чтобы получить значение от 0 до 1.
Вы поймете важность сигмовидного слоя, когда мы начнем строить нашу модель нейронной сети.
Есть много других функций активации, которые даже проще изучить, чем сигмовидную.
Это уравнение сигмовидной функции:
Узлы круговой формы на схеме называются нейронами. На каждом уровне нейронной сети веса умножаются на входные данные.
Мы можем увеличить глубину нейронной сети, увеличив количество слоев. Мы можем улучшить емкость слоя, увеличив количество нейронов в этом слое.
Понимание нашего набора данных
Первое, что нам нужно для обучения нашей нейронной сети, - это набор данных.
Поскольку цель нашей нейронной сети состоит в том, чтобы определить, содержит ли изображение число три или семь, нам необходимо обучить нашу нейронную сеть изображениями троек и семерок. Итак, давайте построим наш набор данных.
К счастью, нам не нужно создавать набор данных с нуля. Наш набор данных уже присутствует в PyTorch. Все, что нам нужно сделать, это просто загрузить его и выполнить с ним несколько основных операций.
Нам нужно загрузить набор данных под названием MNIST (Модифицированный национальный институт стандартов и технологий) из библиотеки torchvision PyTorch.
Теперь давайте углубимся в наш набор данных.
Что такое набор данных MNIST?
Набор данных MNIST содержит рукописные цифры от нуля до девяти с соответствующими метками, как показано ниже:
Итак, мы просто скармливаем нейронной сети изображения цифр и соответствующих им меток, которые сообщают нейронной сети, что это три или семь.
Как подготовить наш набор данных
В загруженном наборе данных MNIST есть изображения и соответствующие им метки.
Мы просто пишем код для индексации только изображений с меткой три или семь. Таким образом, мы получаем набор данных троек и семерок.
Для начала импортируем все необходимые библиотеки.
import torch
from torchvision import datasets
import matplotlib.pyplot as plt
Импортировать библиотеки
Мы импортируем библиотеку PyTorch для построения нашей нейронной сети и библиотеку torchvision для загрузки набора данных MNIST, как обсуждалось ранее. Библиотека Matplotlib используется для отображения изображений из нашего набора данных.
Теперь давайте подготовим наш набор данных.
mnist = datasets.MNIST('./data', download=True)
threes = mnist.data[(mnist.targets == 3)]/255.0
sevens = mnist.data[(mnist.targets == 7)]/255.0
len(threes), len(sevens)
Подготовка набора данных
Как мы узнали выше, все в PyTorch представлено в виде тензоров. Итак, наш набор данных также имеет форму тензоров.
Скачиваем набор данных в первой строке. Мы индексируем только изображения, целевое значение которых равно 3 или 7, и нормализуем их путем деления на 255 и сохраняем их отдельно.
Мы можем проверить, правильно ли была выполнена индексация, запустив код в последней строке, который дает количество изображений в тензоре троек и семерок.
Теперь давайте проверим, правильно ли мы подготовили наш набор данных.
def show_image(img):
plt.imshow(img)
plt.xticks([])
plt.yticks([])
plt.show()
show_image(threes[3])
show_image(sevens[8])
Проверьте проиндексированные изображения
Используя библиотеку Matplotlib, мы создаем функцию для отображения изображений.
Давайте быстро проверим работоспособность, распечатав форму наших тензоров.
print(threes.shape, sevens.shape)
Проверить размер тензоров
Если все пойдет правильно, вы получите размер тройки и семерки как ([6131, 28, 28]) и ([6265, 28, 28]) соответственно. Это означает, что у нас есть 6131 изображение размером 28 × 28 для троек и 6265 изображений размером 28 × 28 для семерок.
Мы создали два тензора с изображениями троек и семерок. Теперь нам нужно объединить их в единый набор данных для передачи в нашу нейронную сеть.
combined_data = torch.cat([threes, sevens])
combined_data.shape
Соедините тензоры
Мы объединим два тензора с помощью PyTorch и проверим форму объединенного набора данных.
Теперь мы сгладим изображения в наборе данных.
flat_imgs = combined_data.view((-1, 28*28))
flat_imgs.shape
Сгладьте изображения
Мы сгладим изображения таким образом, чтобы каждое из изображений размером 28 × 28 стало одной строкой с 784 столбцами (28 × 28 = 784). Таким образом, форма преобразуется в ([12396, 784]).
Нам нужно создать метки, соответствующие изображениям в объединенном наборе данных.
target = torch.tensor([1]*len(threes)+[2]*len(sevens))
target.shape
Создавайте метки достоверности
Мы присваиваем метку 1 изображениям, содержащим тройку, и метку 0, изображениям, содержащим семерку.
Как обучить нейронную сеть
Чтобы обучить нейронную сеть, выполните следующие действия.
Шаг 1. Построение модели
Ниже вы можете увидеть простейшее уравнение, показывающее, как работают нейронные сети:
у = Wx + b
Здесь термин «y» относится к нашему предсказанию, то есть три или семь. «W» относится к нашим значениям веса, «x» относится к нашему входному изображению, а «b» - это смещение (которое, наряду с весами, помогает делать прогнозы).
Короче говоря, мы умножаем каждое значение пикселя на значения веса и добавляем их к значению смещения.
Веса и значение смещения определяют важность каждого значения пикселя при прогнозировании.
Мы классифицируем три и семь, поэтому нам нужно предсказать только два класса.
Таким образом, мы можем предсказать 1, если изображение равно трем, и 0, если изображение равно семи. Прогноз, который мы получаем на этом шаге, может быть любым действительным числом, но нам нужно, чтобы наша модель (нейронная сеть) предсказывала значение от 0 до 1.
Это позволяет нам создать порог 0,5. То есть, если прогнозируемое значение меньше 0,5, то это семь. В противном случае это тройка.
Мы используем сигмовидную функцию, чтобы получить значение от 0 до 1.
Мы создадим функцию для сигмоида, используя то же уравнение, которое было показано ранее. Затем мы передаем значения из нейронной сети в сигмоид.
Создадим однослойную нейронную сеть.
Мы не можем создать много циклов для умножения каждого значения веса на каждый пиксель изображения, так как это очень дорого. Таким образом, мы можем использовать волшебный трюк, чтобы выполнить все умножение за один раз, используя умножение матриц.
def sigmoid(x): return 1/(1+torch.exp(-x))
def simple_nn(data, weights, bias): return sigmoid((data@weights) + bias)
Определение нейронной сети
Шаг 2: Определение потерь
Теперь нам нужна функция потерь, чтобы рассчитать, насколько наше предсказанное значение отличается от истинного значения.
Например, если прогнозируемое значение равно 0,3, но истинное значение равно 1, то наши потери очень высоки. Таким образом, наша модель попытается уменьшить эту потерю, обновив веса и смещение, чтобы наши прогнозы стали близкими к истине.
Мы будем использовать среднеквадратичную ошибку, чтобы проверить значение убытка. Среднеквадратичная ошибка находит среднее значение квадрата разницы между предсказанным значением и истинным значением.
def error(pred, target): return ((pred-target)**2).mean()
Определение потери
Шаг 3. Инициализируйте значения веса
Мы просто случайным образом инициализируем веса и смещение. Позже мы увидим, как эти значения обновляются, чтобы получить наилучшие прогнозы.
w = torch.randn((flat_imgs.shape[1], 1), requires_grad=True)
b = torch.randn((1, 1), requires_grad=True)
Инициализировать параметры
Форма значений веса должна быть следующей:
(Количество нейронов в предыдущем слое, количество нейронов в следующем слое)
Мы используем метод, называемый градиентным спуском, для обновления наших весов и смещения, чтобы сделать максимальное количество правильных прогнозов.
Наша цель - оптимизировать или уменьшить потери, поэтому лучший метод - рассчитать градиенты.
Нам нужно взять производную от каждого веса и смещения по функции потерь. Затем мы должны вычесть это значение из наших весов и смещения.
Таким образом, наши значения весов и смещения обновляются таким образом, что наша модель дает хороший прогноз.
Обновление параметра для оптимизации функции - не новость - вы можете оптимизировать любую произвольную функцию с помощью градиентов.
Мы установили для специального параметра (называемого requires_grad) значение true для вычисления градиента весов и смещения.
Шаг 4. Обновите веса
Если наш прогноз не приближается к истине, это означает, что мы сделали неверный прогноз. Это означает, что наши веса неправильные. Поэтому нам нужно обновлять наши веса, пока мы не получим хорошие прогнозы.
Для этого мы помещаем все вышеперечисленные шаги в цикл for и позволяем ему повторяться любое количество раз, которое мы пожелаем.
На каждой итерации вычисляются потери, а веса и смещения обновляются, чтобы получить лучший прогноз на следующей итерации.
Таким образом, наша модель становится лучше после каждой итерации, находя оптимальное значение веса, подходящее для нашей задачи.
Для каждой задачи требуется свой набор значений веса, поэтому нельзя ожидать, что наша нейронная сеть, обученная классификации животных, будет хорошо справляться с классификацией музыкальных инструментов.
Вот как выглядит обучение нашей модели:
for i in range(2000):
pred = simple_nn(flat_imgs, w, b)
loss = error(pred, target.unsqueeze(1))
loss.backward()
w.data -= 0.001*w.grad.data
b.data -= 0.001*b.grad.data
w.grad.zero_()
b.grad.zero_()
print("Loss: ", loss.item())
Обучение модели
Мы будем рассчитывать прогнозы и сохранять их в переменной pred, вызывая функцию, которую мы создали ранее. Затем мы вычисляем среднеквадратичную потерю ошибки.
Затем мы вычислим все градиенты для наших весов и смещения и обновим значение, используя эти градиенты.
Мы умножили градиенты на 0,001, и это называется скоростью обучения. Это значение определяет скорость, с которой наша модель будет учиться, если она слишком низкая, тогда модель будет учиться медленно, или, другими словами, потери будут уменьшаться медленно.
Если скорость обучения слишком высока, наша модель не будет стабильной, перескакивая между широким диапазоном значений потерь. Это означает, что он не сможет сойтись.
Мы выполняем указанные выше шаги 2000 раз, и каждый раз наша модель пытается уменьшить потери, обновляя значения весов и смещения.
Мы должны обнулить градиенты в конце каждого цикла или эпохи, чтобы не было накопления в памяти нежелательных градиентов, которые повлияют на обучение нашей модели.
Поскольку наша модель очень мала, обучение на 2000 эпох или итераций не займет много времени. После эпохи 2000 наша нейронная сеть дала значение потерь 0,6805, что неплохо для такой маленькой модели.
Вывод
В только что созданной модели есть огромные возможности для улучшения.
Это простая модель, и вы можете поэкспериментировать с ней, увеличив количество слоев, количество нейронов в каждом слое или увеличив количество эпох.
Короче говоря, машинное обучение - это целая магия с использованием математики. Всегда изучайте базовые концепции - они могут показаться скучными, но со временем вы поймете, что эти скучные математические концепции создали такие передовые технологии, как дипфейки .
Вы можете получить полный код на GitHub или поиграть с кодом в Google colab .