Особенности сбора семантики для Яндекс Директ и Гугл ЭДС. Фишки.
Сегодня поговорим об особенностях сбора семантики для каждого из поисковых гигантов. В этой статье речь пойдет о поиске.
Итак, начнем с Яндекса. Яндекс ориентируется на грамматическую (неизменяемую) основу слова- это очень важный момент при сборе семантического ядра. Обратимся к уже избитому примеру: мы рекламируем вазы для цветов, неизменяемая часть слова - ваз, т.е. вазы для цветов и автомобиль ВАЗ для Яндекса одно и тоже. Здесь важно отминусовать !ВАЗ с применением оператора, иначе нецелевой трафик нам обеспечен.
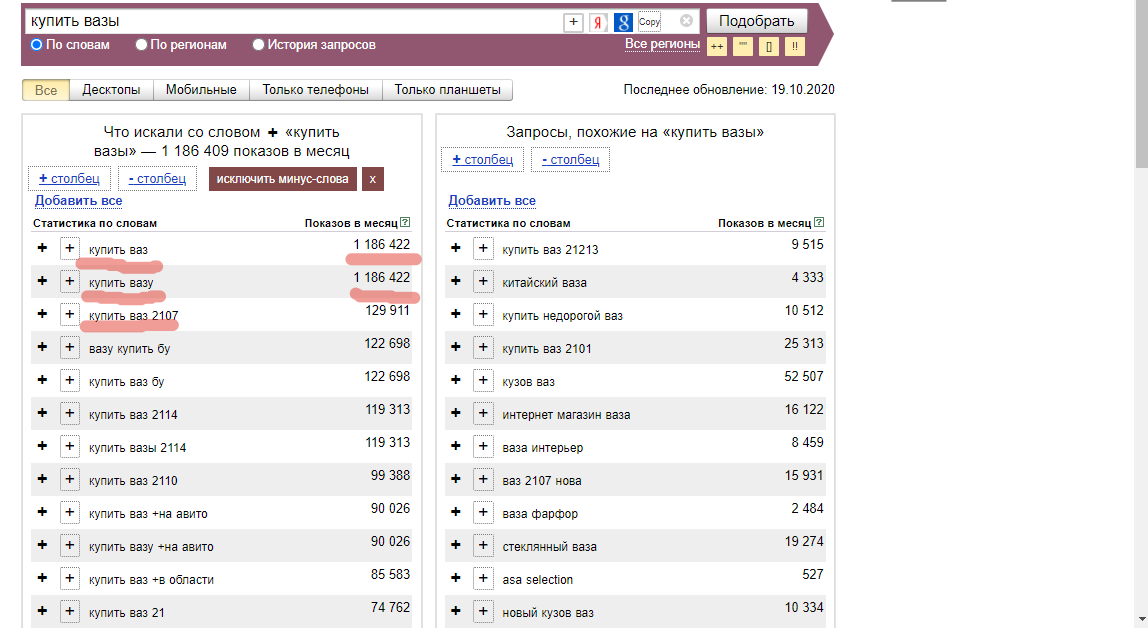
Обратите внимание на два первых запроса: купить ваз и купить вазу. Частотность у этих запросов одинаковая, что говорит о том, что для Яндекса это одно и тоже. Отдадим должное Яндексу, ведь он оставляет для специалистов достаточно инструментов для контроля над процессами. А это значит, что если мы правильно отминусуем словоформу ВАЗ, то в вордстате увидим только вазы для цветов.
Теперь разберем этот пример для Гугл.
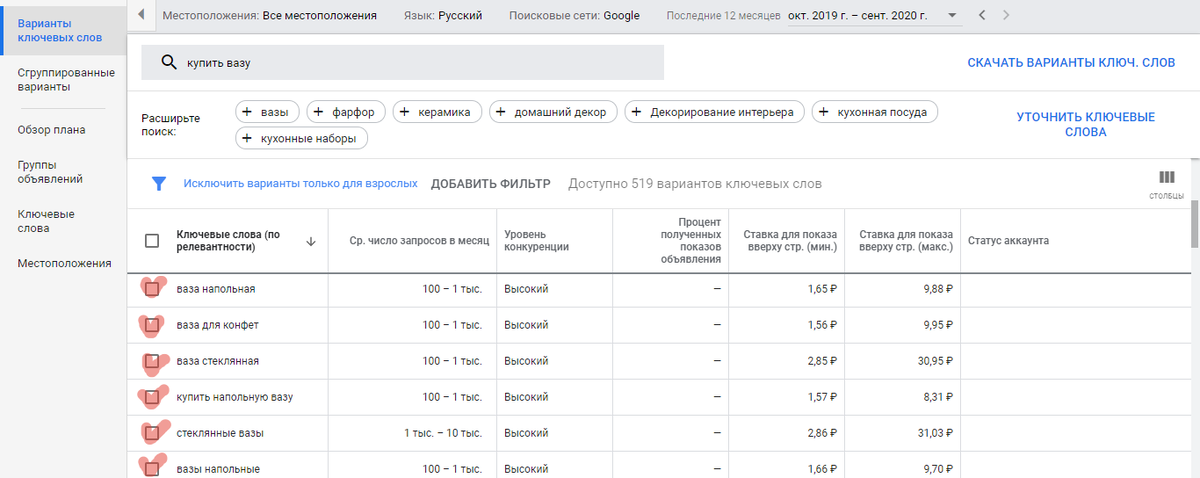
Планировщик Гугл выдает нам только различные варианты ваз для цветов, конфет, фруктов и т.д. Никаких автомобилей мы здесь не наблюдаем. Принцип работы Гугла с семантикой совершенно отличается от Яндекса. Гугл пытается определить значение слова. Т.е. Гугл понимает, что если человек ищет вазу, то он не собирается покупать автомобиль. Но при этом, Гугл подберет великое множество ваз, вазонов, цилиндров и прочего мусора. Для того, чтобы от этого мусора избавиться, нужно перед каждым словом поставить оператор широкого соответствия "+". И тогда Гугл будет подбирать близкие синонимы.
Гугл более автоматизирован, чем Яндекс. Гугл пытается убрать из процесса специалиста по рекламе. Но с помощью оператора "+" мы можем управлять Гуглом, не так, как хотелось бы, но все же можем.
Подытожим: 1) в Яндексе мы можем контролировать процесс, Гугл не раскрывает нам алгоритмы работы;
2) в вордстате мы можем глубоко проработать семантику, собрать частотности. Гугл не выдает точную частотность и при этом не любит низкочастотные фразы;
Из всего вышесказанного делаем вывод, что семантику нужно собирать для Яндекса в вордстате, после уже переносить ее в Гугл планировщик и адаптировать под Гугл.
Продолжение в следующей статье.