У большинства из нас были отличные оценки по математике в школе и в универе. Помните, как мы решали примеры? Скажем, нужно взять производную от функции:
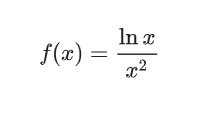
Мы задумывались на несколько секунд и записывали готовый результат:
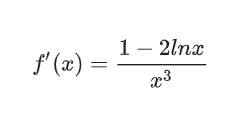
Ученики послабее записывали решение по шагам и тратили существенно больше времени:
Нам, отличникам, всё это ни к чему. Зачем писать столько ненужных промежуточных действий, когда можно сразу готовый ответ? Мы же хотим поскорее разделаться с этим примером, чтобы перейти к следующему!
Почему мы так можем, а другие — не могут?
Математика и кратковременная память
Нет, это очевидно, что мы можем выполнить все необходимые операции в уме, и нам нет необходимости записывать промежуточные результаты на бумаге. Но почему это возможно?
В когнитивной психологии ту часть памяти, в которой непосредственно производятся вычисления «в уме», называют кратковременной и рабочей. Там всё сложно и неоднозначно, но как её ни назови, а объём этой памяти сильно ограничен. Разные исследователи называют «магические числа» семь и пять. Это средние значения. Объём «рабочей» памяти зависит от обстоятельств и коррелирует с интеллектуальными способностями.
Получается, способность не записывать промежуточные результаты обусловлена возможностями нашей рабочей (или кратковременной) памяти. У нас, технарей, рабочая память для хранения «технических» элементов объёмнее, чем у гуманитариев. Чем больше памяти, тем больше промежуточных шагов мы можем накапливать в ней, не записывая.
Программирование и кратковременная память
А теперь попробуем представить, как работают наши сверхспособности, когда мы программируем.
Для решения полученной задачи требуется написать определённое количество кода. Но мы торопимся, и мы способны удержать в голове массу деталей. Чувствуете, куда я клоню? Мы не записываем промежуточные шаги. Вместо этого мы пишем такие алгоритмы, которые получают исходные данные и сразу выдают готовый результат. Они длинные, эти алгоритмы, и они делают очень много работы. Столько, сколько мы смогли уместить в нашей собственной рабочей памяти, когда их писали.
Гипотеза. Чем умнее программист (чем более объёмной рабочей памятью он располагает), тем более длинные методы и функции он пишет.
Попробуем подсчитать, насколько большой объём рабочей памяти требуется при программировании. Поскольку мы не знаем, как именно устроено мышление, и какими именно «объектами» оно оперирует, то просто будем подсчитывать независимые объекты, которые встречаются в коде программы.
В качестве подопытного я взял функцию на Ruby длиной 150 строк из проекта BigBlueButton. Сразу признаюсь, что этот код задел меня за живое. Пришлось потратить пару дней и почти полностью переписать несколько методов, чтобы внести косметические изменения в функциональность небольшой части проекта. Ни одну сколько-нибудь длинную последовательность строк не получилось использовать повторно.
Этот код прекрасно иллюстрирует гипотезу. Он был написан так же, как мы привыкли решать примеры. Масса промежуточных шагов удерживалась непосредственно в голове, а «на бумагу» попало лишь окончательное решение. 150 строк, которые решают всю чёртову задачу одним махом. Этот код явно был написан очень талантливым парнем!
Мы делаем это не злонамеренно. Основа работы программиста — удерживать в голове колоссальное количество объектов и связей между ними. Что плохого в том, что мы задействуем сразу побольше этих объектов в одном методе, чтобы как можно скорее разделаться с ними и перейти к следующему большому набору объектов? Последовательное решение задачи «понемногу», «шаг за шагом» — это ведь для троечников, правда?
Так вот, я грубо посчитал количество независимых объектов, которые фигурируют в коде. То количество объектов, которые пришлось удерживать в голове более-менее одновременно, чтобы понимать, что происходит во всей этой портянке сверху донизу. Вот что у меня получилось:
- 4 аргумента функции, которые упоминаются в общей сложности 15 раз;
- 42 внутренних переменных, использованных ещё 131 раз;
- 52 обращения к 24 различным элементам хэшей, переданных функции в качестве аргументов (чтобы работать с кодом, необходимо удерживать в голове внутреннее «устройство» всех этих хэшей);
- 9 обращений к 8 различным внешним сущностям (константам и методам классов).
Итого, считая по-минимуму, получились 4+42+24+8=78 независимых объектов. И это я ещё не считал операции, которые выполняются над объектами. А ведь операции тоже «занимают» какую-то долю рабочей памяти.
78 объектов против «магических» семи — не многовато ли для одной функции?
Конечно, тут можно бесконечно спорить о том, что раз код написан и работает, значит, 78 объектов — вовсе не проблема. Это ведь не самый длинный метод, так? Значит, объектов может быть ещё больше? К тому же, кто сказал, что все 78 необходимо удерживать строго одновременно?
Проблема длинного метода не в том, что его невозможно понять. Проблема в том, что понять его сложно, потому что требуются усилия для того, чтобы «прогреть наш кеш». Нужны время и силы, чтобы загрузить в рабочую память весь набор объектов, составляющих изучаемый фрагмент кода, и удерживать их там продолжительное время. Чем больше объектов — тем больше подавай рабочей памяти, а она у всех разная, да и у одного и того же разработчика зависит от степени усталости и настроения…
Метрики и кратковременная память
Для оценки качества кода применяются различные метрики. Например, Морис Холстед исследовал численные метрики кода ещё в 70-х (!) годах. Вроде бы понятно, что измерять и оценивать качество кода — дело хорошее. И спору нет, что чем сложнее код, тем больше умственных усилий он требует. Но есть с метриками один вопрос. По выражению EvgeniyRyzhkov, «в метриках не придумано главного — что с ними делать».
Программирование — сложный интеллектуальный процесс. На его протекание влияют множество факторов. Самый значимый фактор, на мой взгляд — это свойства и ограничения главного рабочего инструмента для создания кода — интеллекта программиста. Изучением «внутреннего устройства» интеллекта занимается когнитивная психология. Благодаря ей достоверно известно, что возможности интеллекта ограничены, и величина этих ограничений даже была измерена. А раз ограничены возможности инструмента, значит и «изделие» будет и должно иметь определённую специфику. «Будет» — потому что код является продуктом работы мозга-инструмента. «Должно» — потому что код является одновременно также и исходным сырьём.
Код-сырьё должен отвечать определённым критериям, чтобы мозг-инструмент не сломался во время его обработки.
Раз наука, которая изучает свойства интеллекта, называется когнитивной, то и метрику, которая соотносится с ограничениями этого интеллекта, логично тоже назвать когнитивной. Назову её, скажем, когнитивным весом. А то когнитивная сложность уже занята. Кстати, Холстед в своих «Началах науки о программах» описывает метрику, на которую когнитивный вес очень сильно похож. Только Холстед не апеллирует к понятию «когнитивный». (К слову, «Cognitive Psycology» R. Solso была впервые опубликована в 1979-м, а «Elements of Software Science» M. Halstead — в 1977-м).
Так вот, отвечаю на вопрос про метрики.
Практически полезные метрики качества кода следует строить так, чтобы они показывали, с каким кодом мозгу-инструменту будет работать легко, а на каком он «сломается». И не «интуитивно», а опираясь на данные, получаемые от когнитивной науки.
Резюме
Запись решения «шаг за шагом» требуется не только для того, чтобы троечник мог решить пример. Она нужна, чтобы на чтение и проверку решения требовалось настолько мало умственных усилий, чтобы делать это мог даже троечник. Отличник разберётся и в записи решения без промежуточных шагов, но если примеры сложные, а прочитать их нужно тысячи… В общем, вы поняли.
В следующий раз расскажу о приёмах, которые я использую для уменьшения сложности своего кода.
P.S. Один из моих шайтан-методов, до которого никак не доходят руки отрефакторить, имеет длину 120 строк. Когнитивный вес даже считать не хочется. Стыдно.
UPD
Судя по каментам, я неясно выразил смысл, который вкладывал в термины «отличник» и «троечник». Эта пара терминов — всего лишь литературный приём: метафора и гипербола. Нужны были какие-то короткие наименования для понятий «лицо со способностями к точным наукам выше среднего» и «лицо с менее развитыми способностями к точным наукам». Нигде в тексте, как мне кажется, я не восхваляю первых и не дискредитирую вторых. Напротив, одна из идей, «зашитых» в тексте (не новая и не моя): если «отличники» будут необдуманно пользоваться своими отличными способностями в процессе кодинга, ничего отличного из этого не получится.
Школьные оценки для меня никогда не были показателем чего-то существенного. У меня самого по всем предметам, кроме математики, были крайне средние оценки. Своей дочери я всегда старался внушить мысль, что оценки — не главное в жизни. Важно, чтобы что-то было в голове: знания, понимание, интерес к чему-то. Хотя, она меня не слушала и закончила школу с золотой медалью.
UPD2
Нет, я имел в виду именно тех отличников, которые соображают и понимают, а не зубрят. В учебных предметах наши способности позволяют нам получать верные решения очень быстро, пропуская несущественные промежуточные шаги. Да и в реальных технических задачах высокая скорость решения, как правило, — положительный фактор.
А в программировании промежуточные шаги внезапно оказываются самыми существенными. И мы начинаем искренне недоумевать по поводу наездов на наши прекрасные 300-строчные функции. Но мы ведь старались, мы делали лучшее, на что способны! Просто никто не объяснил, что в программировании нужно в точности наоборот: писать тупой код, а быстрые и умные решения всегда имеют вредные последствия.
Мне в универе рассказывали только про структурное программирование Дейкстры, а про принцип единственной ответственности я узнал много позже. Что удивительного, что я рассуждал о длине метода, опираясь на чьи-то советы по поводу размера экрана, не понимая, какова истинная причина того, почему методы должны быть короткими.