BGP Fundamentals
С точки зрения BGP autonomous system (AS) - это совокупность маршрутизаторов одной организации, использующих один или несколько IGP и общие метрики для маршрутизации пакетов внутри AS. Если в AS используются несколько IGP или метрик, эта AS должна быть согласованной с внешними AS в политике маршрутизации. IGP не требуется в AS; AS может использовать BGP как единственный протокол маршрутизации.
Autonomous System Numbers
Для подключения к Интернету требуется получить номер автономной системы (ASN). Изначально ASN были 2 байтами (16-битный диапазон), что делало возможным 65 535 ASN. Из-за исчерпания возможностей RFC 4893 расширил поле ASN до 4 байтов (32-битный диапазон). Это позволяет использовать 4 294 967 295 уникальных ASN, что значительно превышает исходные 65 535 ASN.
Любая организация может использовать два блока частных ASN при условии, что они никогда не будут видны в Интернет. ASN 64 512–65 535 являются частными ASN в 16-разрядном диапазоне ASN, а 4 200 000 000–4 294 967 294 являются частными ASN в расширенном 32-разрядном диапазоне.
Управление по присвоению номеров в Интернете (IANA) отвечает за назначение всех общедоступных ASN, чтобы гарантировать их глобальную уникальность. При запросе общедоступного ASN IANA требует следующее:
- Подтверждение публично выделенного network range
- Доказательство того, что подключение к Интернету обеспечивается через несколько подключений
- Необходимость уникальной политики маршрутизации от провайдеров
Если организация не может предоставить эту информацию, ей следует использовать ASN, предоставленный ее Интернет провайдером.
NOTE Крайне важно использовать только ASN присвоенный IANA, ASN назначенный вашим Интернет провайдером или private ASN. Использование ASN другой организации без разрешения может привести к потере трафика и вызвать хаос в Интернете.
Path Attributes
BGP использует path attributes (PAs), связанные с каждым network path. PA обеспечивают детализацию BGP и контроль политик маршрутизации внутри BGP. Path attributes (PAs) BGP классифицируются следующим образом:
- Well-known mandatory (Общеизвестный обязательный)
- Well-known discretionary
- Optional transitive (Необязательный транзитивный)
- Optional non-transitive (Необязательный нетранзитивный)
Согласно RFC 4271 Well-known атрибуты должны распознаваться всеми реализациями BGP. Well-known mandatory атрибуты должны быть включены в каждый prefix advertisement; well-known discretionary атрибуты могут быть включены или не включены в prefix advertisement.
Optional атрибуты не обязательно должны распознаваться всеми реализациями BGP. Optional атрибуты можно установить так, чтобы они были транзитивными и оставались с анонсированием маршрута от AS к AS. Нетранзитивны PA не могут переходить от AS к AS. В BGP Network Layer Reachability Information (NLRI) - это обновление маршрутизации, которое состоит из префикса сети, длины префикса и любых PA BGP для определенного маршрута.
Loop Prevention
BGP - это path vector протокол маршрутизации, который не содержит полной топологии сети, как это делают link-state протоколы маршрутизации. BGP ведет себя как distance vector протоколы, обеспечивая отсутствие петель на пути.
Атрибут BGP AS_Path является Well-known mandatory атрибутом и включает в себя полный список всех ASN, через которые прошел анонс префикса от своей source AS. AS_Path используется в BGP как механизм предотвращения петель. Если маршрутизатор BGP получает prefix advertisement с его (этого BGP маршрутизатора) AS, указанным в атрибуте AS_Path, он отбрасывает префикс, поскольку маршрутизатор считает, что анонс образует петлю.
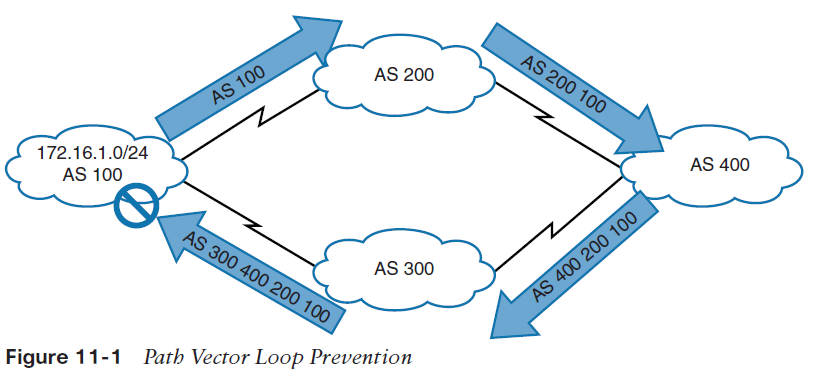
На рисунке ниже показан механизм предотвращения петель:
- AS 100 анонсирует префикс 172.16.1.0/24 в AS 200.
- AS 200 анонсирует префикс в AS 400, который затем анонсирует префикс в AS 300.
- AS 300 анонсирует префикс обратно в AS 100 с AS_Path 300 400 200 100. AS 100 видит себя в переменной AS_Path и отбрасывает префикс.
Address Families
Первоначально BGP был предназначен для маршрутизации префиксов IPv4 между организациями, но RFC 2858 добавил возможность Multi-Protocol BGP (MP-BGP), добавив расширение, называемое address family identifier (AFI). Address family коррелирует с конкретным сетевым протоколом, таким как IPv4 или IPv6, а дополнительная детализация обеспечивается с помощью subsequent addressfamily identifier (SAFI). MBGP получает такое разделение (в смысле IPv4 или IPv6) с помощью атрибутов пути BGP (PA) MP_REACH_NLRI и MP_UNREACH_NLRI. Эти атрибуты переносятся в BGP update messages и используются для передачи информации о доступности сети для различных семейств адресов.
NOTE Некоторые сетевые инженеры называют Multiprotocol BGP MP-BGP, а другие используют термин MBGP. Оба термина относятся к одному и тому же.
Каждое address family поддерживает отдельную базу данных и конфигурацию для каждого протокола (address family + sub-address family) в BGP. Это позволяет политике маршрутизации в одном address family отличаться от политики маршрутизации в другом address family, даже если это происходит в пределах одной BGP сессии. BGP использует AFI и SAFI в каждом анонсе маршрута, чтобы различать базы данных AFI и SAFI.
Inter-Router Communication
BGP не использует hello пакеты для обнаружения соседей, как это делают протоколы IGP, и не может динамически обнаруживать соседей. BGP был разработан как inter-autonomous протокол маршрутизации, подразумевая, что соседство не должно часто меняться и находится под контролем. Соседи BGP определяются IP-адресом.
BGP использует TCP-порт 179 для связи с другими маршрутизаторами. TCP позволяет обрабатывать фрагментацию, упорядочивание и надежность (подтверждение и повторную передачу) пакетов связи. Самые последние реализации BGP устанавливают бит do-not-fragment (DF), чтобы предотвратить фрагментацию и полагается на path MTU discovery.
IGP следуют физической топологии, в смысле что сессии формируются с hellos, которые не могут пересекать границы сети. (т.е находяться в single hop only). BGP использует протокол TCP, который может пересекать границы сети (то есть поддерживает multi-hop). Хотя BGP может формировать соседские смежности, которые directly connected, он также может формировать смежности, удаленные на несколько hops.
BGP session относится к установленной смежности между двумя маршрутизаторами BGP. Multi-hop sessions требует, чтобы маршрутизатор использовал маршрут из RIB (статический или из любого протокола маршрутизации), для установления сеанса TCP с другим BGP роутером.
На рисунке ниже R1 может установить прямой сеанс BGP с R2. Кроме того, R2 может установить сеанс BGP с R4, даже если он проходит через R3. R1 и R2 используют directly connected маршрут для поиска друг друга. R2 использует статический маршрут для достижения сети 10.34.1.0/24, а R4 имеет статический маршрут для достижения сети 10.23.1.0/24. R3 не знает, что R2 и R4 установили сеанс BGP, даже если пакеты проходят через R3.
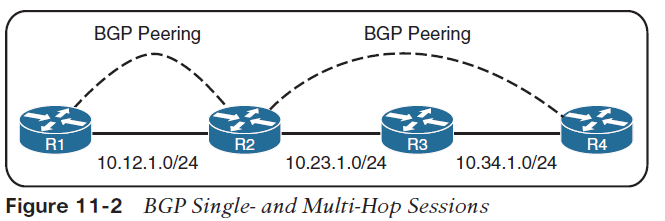
NOTE Соседи BGP в одной сети используют таблицу ARP для определения IP-адреса пира. Multi-hop BGP сессии требуют информации таблицы маршрутизации для поиска IP-адреса пира. Обычно между соседями iBGP выполняется статический маршрут или протокол IGP для предоставления информации о топологии для установления сеанса TCP BGP. Маршрута по умолчанию недостаточно для установления сессии multi-hop BGP.
BGP можно рассматривать как control plane протокол маршрутизации или как приложение, поскольку он позволяет обмениваться маршрутами с пиром, находящимся на расстоянии нескольких hops. Маршрутизаторы BGP не обязательно должны находиться в data plane (path) для обмена префиксами, но все маршрутизаторы на пути данных должны знать все маршруты, которые будут проходить через них.
BGP Session Types
Сессии BGP делятся на два типа:
- Internal BGP (iBGP): Сессии, установленные с маршрутизатором iBGP, которые находятся в одной AS или участвуют в одной конфедерации BGP. Префиксам iBGP назначается административное расстояние (AD) 200 после установки в RIB маршрутизатора.
- External BGP (eBGP): Сессии, установленные с маршрутизатором BGP, который находится в другой AS. Префиксам eBGP назначается 20 AD при установке в RIB маршрутизатора.
В следующих разделах рассматриваются эти два типа сеансов BGP.
iBGP
Потребность в BGP у AS обычно возникает, когда требуется несколько политик маршрутизации или когда между автономными системами обеспечивается транзитное соединение. На рисунке ниже AS 65200 обеспечивает транзитное соединение AS 65100 с AS 65300. AS 65100 подключается к R2, а AS 65300 подключается к R4.
R2 мог бы формировать сессию iBGP напрямую с R4, но тогда R3 не знал бы, куда направлять трафик от AS 65100 или AS 65300. Посмотрим на нижний рисунок . Когда трафик достигает R3 от любой из AS, R3 не имеет соответствующей информации о маршрутизации.
Вы можете предположить, что редистрибьюция таблицы BGP в IGP решает проблему, но это не жизнеспособное решение по нескольким причинам:
- Scalability: Интернет на момент написания этой статьи имел 780 000+ сетевых префиксов IPv4 и продолжает увеличиваться в размерах. IGP не могут масштабироваться до этого уровня маршрутов.
- Custom routing: Link-state и distance vector протоколы маршрутизации используют метрику как основной метод выбора маршрута. Протоколы IGP поступают так всегда. BGP использует несколько шагов для определения наилучшего пути и позволяет атрибутам пути BGP управлять выбором пути для определенного префикса (NLRI). Путь может быть длиннее, а это обычно считается неоптимальным с точки зрения IGP.
- Path attributes: Все атрибуты пути BGP не поддерживаются в протоколах IGP. Только BGP может поддерживать атрибут пути, поскольку префикс объявляется от одного края AS к другому. Установление iBGP сессий между всеми маршрутизаторами (R2, R3 и R4) по full mesh схеме позволит организовать правильную пересылку трафика между автономными системами.
NOTE Интернет провайдеры обеспечивают транзитное соединение. Корпоративные организации являются потребителями и не должны обеспечивать транзитное соединение между автономными системами через Интернет.
eBGP
eBGP пиринги являются основным компонентом BGP в Интернете. eBGP предполагает обмен префиксами сети между автономными системами. Существуют следующие отличия поведение сессий eBGP от сессий iBGP:
- Время жизни (TTL) для пакетов eBGP по умолчанию установлено на 1. Пакеты eBGP сбрасываются при передаче, если предпринимается попытка организации multi-hop BGP сессии. (TTL для пакетов iBGP установлен на 255, что позволяет использовать multi-hop сессии.)
- Роутер, занимающийся анонсированием, изменяет BGP next-hop адрес на ip адрес sourcе BGP роутера (т.е. next-hop-ом для BGP пакета всегда будет роутер, откуда пришел предыдущий BGP пакет).
- Роутер, занимающийся анонсированием, добавляет свой ASN к существующей переменной AS_Path.
- Принимающий маршрутизатор проверяет, что переменная AS_Path не содержит ASN, который соответствует локальным маршрутизаторам. BGP отбрасывает NLRI, если он не проходит проверку предотвращения петель AS_Path.
Конфигурации для сессий eBGP и iBGP в основном одинаковы, за исключением того, что ASN в remote-as заявлении отличается от ASN, определенного в процессе BGP.
Рисунок ниже показывает eBGP и iBGP сессии, которые потребуются между маршрутизаторами для обеспечения связи между AS 65100 и AS 65300. Обратите внимание, что AS 65200 R2 устанавливает сеанс iBGP с маршрутизатором R4, чтобы обойти функцию loop-prevention при изучении маршрутов iBGP.
BGP Messages
Для связи BGP используются четыре типа сообщений, как показано в таблице ниже.
OPEN: Сообщение OPEN используется для установления смежности BGP. Обе стороны согласовывают возможности сеанса до установления пиринга BGP. Сообщение OPEN содержит номер версии BGP, ASN исходного маршрутизатора, the Hold time, BGP identifier и другие необязательные параметры, которые определяют возможности сессии.
- Hold time: Атрибут hold time устанавливает таймер удержания в секундах для каждого соседа BGP. После получения UPDATE или KEEPALIVE таймер сбрасывается до начального значения. Если таймер удержания достигает нуля, сессия BGP прерывается. При этом маршруты от этого соседа удаляются, и отправляется соответствующее update route сообщение другим соседям BGP для затронутых префиксов. Hold time - это контрольный механизм для соседей BGP, гарантирующий, что сосед жив и здоров. При установлении сессии BGP маршрутизаторы выбирают наименьшее значение hold time, содержащееся в OPEN сообщениях двух маршрутизаторов. Значение в hold time должно быть не менее 3 секунд или установлено в 0, чтобы отключить keepalive сообщения. Для маршрутизаторов Cisco hold timer по умолчанию составляет 180 секунд.
- BGP identifier: ID маршрутизатора BGP (RID) - это 32-битный уникальный номер, который идентифицирует маршрутизатор BGP в анонсируемых префиксах. RID может использоваться как loop-prevention механизм для маршрутизаторов, объявленных в автономной системе. RID можно установить вручную или динамически для BGP. Чтобы маршрутизаторы стали соседями, необходимо установить ненулевое значение.
KEEPALIVE: BGP не полагается на состояние TCP-соединения, чтобы гарантировать, что соседи все еще живы. KEEPALIVE сообщения отправляются каждые треть времени hold timer, согласованного между двумя маршрутизаторами BGP. У устройств Cisco время удержания по умолчанию составляет 180 секунд, поэтому keepalive интервал по умолчанию составляет 60 секунд. Если время удержания установлено на 0, то между соседями BGP не отправляются сообщения keepalive.
UPDATE: UPDATE сообщение анонсирует любые возможные маршруты, отменяет ранее объявленные маршруты или может делать и то, и другое. UPDATE сообщение включает Network Layer Reachability Information (NLRI), такие как префикс или связанные с ним PA BGP, при анонсировании префиксов. Удаленные NLRI включают только префикс. UPDATE сообщение также может выполнять роль keepalive для уменьшения лишнего трафика.
NOTIFICATION: NOTIFICATION сообщение отправляется, когда в сеансе BGP обнаруживается ошибка, такая как истечение hold timer, изменение возможностей соседей или запрос сброса BGP сессии. Это приводит к закрытию BGP-соединения.
BGP Neighbor States
BGP формирует TCP сессию с соседними маршрутизаторами, называемыми пирами. BGP использует finite-state machine (FSM) для ведения таблицы всех BGP пиров и их рабочего состояния. Сессия BGP может сообщать о следующих состояниях:
- Idle
- Connect
- Active
- OpenSent
- OpenConfirm
- Established
На рисунке ниже показаны BGP FSM и состояния, перечисленные в порядке, используемом при установлении сессии BGP.
Idle
Idle(ожидание)- это первая стадия BGP FSM. BGP обнаруживает старт и пытается инициировать TCP-соединение с пиром BGP, а также прослушивает новое соединение от маршрутизатора пира. Если ошибка заставляет BGP вернуться в Idle состояние во второй раз, ConnectRetryTimer устанавливается в 60 секунд и должен уменьшиться до нуля, прежде чем соединение может быть инициировано заново. Дальнейшие сбои при выходе из Idle состояния приводят к удвоению длины ConnectRetryTimer по сравнению с предыдущим разом.
Connect
В состоянии Connect BGP инициирует TCP-соединение. Если трехстороннее TCP handshake завершено, установленный процесс сессии BGP сбрасывает ConnectRetryTimer и отправляет сообщение Open соседу; затем он переходит в состояние OpenSent. Если ConnectRetryTimer не сбросился и дошел до 0 до завершения этого этапа, предпринимается попытка нового TCP-соединения. При этом ConnectRetryTimer сбрасывается, и состояние изменяется на Active. Если получен любой другой ввод, состояние меняется на Idle.
На этом этапе соединением управляет сосед с более высоким IP-адресом. Маршрутизатор, инициирующий запрос, использует динамический source порт, но destination порт всегда 179.
В примере ниже показан установленный сеанс BGP с использованием команды show tcp brief для отображения активных TCP сессий на маршрутизаторах. Обратите внимание, что source порт TCP - 179, а destination порт - 59884 на R1; на R2 порты противоположные.
Active
В состоянии Active BGP начинает новое трехстороннее TCP handshake. Если соединение установлено, отправляется сообщение Open, hold timer устанавливается на 4 минуты и состояние переходит в OpenSent. Если эта попытка TCP-соединения не удалась, состояние возвращается в состояние Connect, а ConnectRetryTimer сбрасывается.
OpenSent
В состоянии OpenSent сообщение Open было отправлено от исходного маршрутизатора и ожидает сообщения Open от другого маршрутизатора. Как только исходный маршрутизатор получает сообщение OPEN от другого маршрутизатора, оба сообщения OPEN проверяются на наличие ошибок. При этом исследуются следующие элементы:
- Версии BGP должны совпадать.
- Source IP-адрес сообщения OPEN должен совпадать с IP-адресом, настроенным для соседа.
- Номер AS в сообщении OPEN должен соответствовать тому, что настроено для соседа.
- Идентификаторы BGP (RID) должны быть уникальными. Если RID не существует, это условие не выполняется.
- Параметры безопасности (такие как пароль и TTL) должны быть установлены соответствующим образом.
Если сообщения OPEN не содержат ошибок, согласовывается hold time (используется наименьшее значение) и отправляется KEEPALIVE сообщение (при условии, что значение не установлено на 0). Затем состояние подключения перемещается в OpenConfirm. Если в сообщении OPEN обнаружена ошибка, отправляется сообщение NOTIFICATION, и состояние возвращается в состояние Idle.
Если TCP получает disconnect сообщение, BGP закрывает соединение, сбрасывает ConnectRetryTimer и устанавливает состояние Active. Любой другой ввод в этом процессе приводит к переходу в состояние Idle.
OpenConfirm
В состоянии OpenConfirm BGP ожидает сообщения KEEPALIVE или NOTIFICATION. После получения сообщения KEEPALIVE от соседа состояние меняется на Established. Если hold timer истекает, случается остановка или получено сообщение NOTIFICATION, состояние переводится в состояние Idle.
Established
В состоянии Established сессия BGP установлена. Соседи BGP обмениваются маршрутами с помощью сообщений UPDATE. При получении сообщений UPDATE и KEEPALIVE hold timer сбрасывается. Если hold timer истекает, обнаруживается ошибка, и BGP переводит соседа обратно в состояние Idle.
Basic BGP Configuration
При настройке BGP лучше всего рассматривать конфигурацию с точки зрения модулей. Для настройки маршрутизатора BGP требуются следующие компоненты:
- BGP session parameters: Параметры BGP сессии обеспечивают настройки, которые включают установление связи с удаленным соседом BGP. Настройки сессии включают ASN BGP пира, аутентификацию и keepalive таймеры
- Address family initialization: Address family инициализируется в режиме конфигурации маршрутизатора BGP. Сетевая анонсы и суммирование происходят внутри address family.
- Activate the address family on the BGP peer: Чтобы сессия иницииировалась, должно быть активировано одно address family для соседа. IP-адрес маршрутизатора добавляется в таблицу соседей, и BGP пытается установить BGP сессию или принимает BGP сессию, инициированную маршрутизатором пира.
Следующие шаги показывают, как настроить BGP:
- Step 1. Инициализируйте процесс маршрутизации BGP с помощью глобальной команды router bgp as-number.
- Step 2. (Optional) Статически определите идентификатор маршрутизатора BGP (RID). Логика динамического распределения RID использует наивысший IP-адрес из всех up loopback интерфейсов. Если нет up loopback интерфейса, тогда наивысший IP-адрес любого активного up интерфейса становится RID при инициализации процесса BGP. Чтобы гарантировать, что RID не изменится, назначается статический RID (обычно представляющий адрес IPv4, который находится на маршрутизаторе, например, адрес loopback интерфейса). Можно использовать любой IPv4-адрес, включая IP-адреса, не настроенные на маршрутизаторе. Статическая настройка BGP RID является наилучшей практикой и предполагает использование команды bgp router-id router-id. При изменении router ID все сеансы BGP сбрасываются, и их необходимо переустановить.
- Step 3. Определите IP-адрес соседа BGP и номер автономной системы с помощью команды настройки маршрутизатора BGP neighbour ip-address remote-as as-number. Важно понимать какие BGP пакеты ходят между пирами. Source IP-адрес пакетов BGP по-прежнему отражает IP-адрес исходящего интерфейса. Когда получен пакет BGP, маршрутизатор коррелирует source IP-адрес пакета с IP-адресом, настроенным для этого соседа. Если source BGP пакета не соответствует записи в таблице соседей, пакет не может быть ассоциирован с соседом и отбрасывается.
NOTE IOS по умолчанию активирует address family IPv4. Это может упростить настройку в среде IPv4, поскольку шаги 4 и 5 необязательны, но могут вызвать путаницу при работе с другими address families. Команда настройки маршрутизатора BGP no bgp default ip4-unicast отключает автоматическую активацию IPv4 AFI, поэтому потребуются шаги 4 и 5.
- Step 4. Инициализируйте address family с помощью команды настройки маршрутизатора BGP address-family afi safi. Примерами значений afi являются IPv4 и IPv6, а примерами значений safi являются unicast и multicast.
- Step 5. Активируйте address family для BGP-соседа с помощью команды neighbor ip-address activate.
NOTE На устройствах IOS и IOS XE идентификатор (SAFI) по умолчанию для address families IPv4 и IPv6 является unicast и не является обязательным.
На следующем рисунке показана топология простой конфигурации BGP.
В примере ниже показано, как настроить R1 и R2 с использованием CLI IOS. R1 настроен с включенным address family IPv4 по умолчанию, а R2 отключает address family IPv4 по умолчанию и вручную активирует его для конкретного соседа 10.12.1.1.
Verification of BGP Sessions
Сессия BGP проверяется с помощью команды show bgp afi safi summary. На примере ниже показан вывод IPv4 BGP unicast summary. Обратите внимание, что BGP RID и table version являются первыми показанными компонентами. Столбец Up/Down указывает, что сессия BGP активна более 5 минут.
Таблица ниже объясняет поля вывода, отображаемые в таблице BGP (как в примере выше).
Состояние BGP сессий с пирами, таймеры и другая важная информация о пиринге доступна с помощью команды show bgp afi safi neighbors ip-address, как показано в примере ниже.
Prefix Advertisement
В настройки BGP не включают выбранные интерфейсы в BGP, а объявляет выбранные сетевые префиксы, которые необходимо установить в таблицу BGP, известную как таблица Loc-RIB.
После настройки в BGP сети для анонсирования, процесс BGP ищет в глобальный RIB (Routing Information Base) этот префикс сети с точным совпадением. BGP должен знать куда отправлять трафик для этого префикса. Сетевой префикс может быть connected network, a secondary connected network или любой маршрут протокола маршрутизации. После проверки того, что анонсированная сеть соответствует префиксу в глобальном RIB, префикс устанавливается в таблицу BGP Loc-RIB. В зависимости от типа префикса, с ним устанавливаются следующие PA BGP.
- Connected network: BGP атрибут next-hop устанавливается в 0.0.0.0, BGP атрибут origin устанавливается в i (IGP), а BGP weight устанавливается 32768.
- Static route or routing protocol: BGP атрибут next-hop устанавливается равным IP-адрес next-hop в RIB, BGP атрибут origin устанавливается в i (IGP), BGP weight устанавливается 32768, а MED установлен на метрику IGP.
Не каждый маршрут в таблице Loc-RIB анонсируется BGP пиру. Все маршруты в таблице Loc-RIB используют следующий процесс для анонсирования BGP пирам.
Step 1. Проверка на валидность. Убедитесь, что NRLI валидный и что next-hop адрес достижим в глобальном RIB. Если NRLI неверный, NLRI остается, но не обрабатывается дальше.
Step 2. Применения политик для исходящих маршрутов. После применения, если маршрут не был отклонен политиками исходящих маршрутов, он сохраняется в таблице Adj-RIB-Out для дальнейшего использования.
Step 3. Анонсирование NLRI BGP пирам. Если BGP PA next-hop NLRI равен 0.0.0.0, то next-hop адрес изменяется на IP-адрес BGP сессии.
На рисунке ниже показана концепция установки префикса сети из локализованных сетевых анонсов BGP в таблицу BGP.
NOTE BGP объявляет только лучший путь другим партнерам BGP, независимо от количества маршрутов (NLRI) в таблице BGP Loc-RIB.
Анонс сети находится в соответствующем address family в конфигурации маршрутизатора BGP. Команда network network mask subnet-mask [route-map route-map-name] используется для анонсирования сетей IPv4. Дополнительный route-map предоставляет возможность установки определенных PA BGP при установке префикса в таблицу Loc-RIB (Более детально это будет рассматриваться в теме "Advanced BGP").
На рисунке 11-7 показаны R1 и R2, подключенные через сеть 10.12.1.0/24. Пример ниже демонстрирует конфигурацию, в которой оба маршрутизатора анонсируют интерфейсы Loopback 0 (192.168.1.1/32 и 192.168.2.2/32 соответственно) и сеть 10.12.1.0/24 в BGP. Обратите внимание, что R1 использует address family IPv4 по умолчанию, а R2 явно указывает address family IPv4.
Receiving and Viewing Routes (Получение и просмотр маршрутов)
BGP использует три таблицы для поддержания network prefix и path attributes (PAs) для маршрута:
- Adj-RIB-In: Содержит NLRI в оригинальной форме (то есть до применения политик для входящих маршрутов). Для экономии памяти таблица очищается после применения всех политик маршрутизации.
- Loc-RIB: Содержит все NLRI, которые возникли локально или были получены от других BGP пиров. После того, как NLRI проходят проверку валидности и next-hop достижимости, BGP best-path алгоритм выбирает лучший NLRI для определенного префикса. Таблица Loc-RIB - это таблица, используемая для представления маршрутов таблице IP routing
- Adj-RIB-Out: Содержит NLRI после после применения политик к исходящим маршрутам.
Не каждый префикс в таблице Loc-RIB анонсируется BGP пиру или устанавливается в глобальный RIB при получении от BGP пира. BGP выполняет следующие шаги обработки маршрута:
- Step 1. Сохраняет маршрут в таблице Adj-RIB-In в оригинальном состоянии и применяется политика для получаемых от соседа маршрутов.
- Step 2. Обновляется Loc-RIB с последней записью. Таблица Adj-RIB-In очищается для экономии памяти.
- Step 3. Происходит проверка валидности маршрута и доступности next-hop адреса в глобальной RIB. В случае сбоя маршрута он остается в таблице Loc-RIB, но не обрабатывается дальше.
- Step 4. Определяется лучший путь BGP и передается на шаг 5 только лучший путь и его атрибуты пути. Процесс выбора наилучшего пути BGP описан в главе Advanced BGP.
- Step 5. Устанавливается best-path маршрут в глобальный RIB, применяется политика для исходящего маршрута, не отброшенные маршруты сохраняются в таблице Adj-RIB-Out и анонсируются BGP пирам.
На рисунке ниже показана полная логика обработки маршрута BGP. Она включает получение маршрута от BGP пиров и алгоритм наилучшего пути BGP.
Команда show bgp afi safi отображает содержимое базы данных BGP (Loc-RIB) на маршрутизаторе. Каждая запись в таблице BGP Loc-RIB содержит как минимум один путь, но может содержать несколько путей для одного и того же сетевого префикса. В примере ниже показана таблица BGP на маршрутизаторе R1, которая содержит полученные маршруты и локально сгенерированные маршруты.
В таблице ниже поясняются поля вывода при отображении таблицы BGP.
Команда show bgp afi safi network отображает все пути для определенного маршрута и атрибуты пути BGP для этого маршрута. В примере ниже показаны пути для сети 10.12.1.0/24. Вывод включает количество путей и лучший путь.
NOTE Команда show bgp afi safi detail отображает всю таблицу BGP со всеми атрибутами пути.
Таблица Adj-RIB-Out - это уникальная таблица, поддерживаемая для каждого пира BGP. Это позволяет сетевому инженеру просматривать маршруты, анонсированные каждому конкретному маршрутизатору. Команда show bgp afi safi neighbor ip-address advertised routes отображает содержимое таблицы Adj-RIB-Out для соседа.
В следующем примере показаны записи Adj-RIB-Out, относящиеся к каждому соседу. Обратите внимание, что адрес next-hop отражает локальный маршрутизатор и будет изменен по мере объявления маршрута пиру.
Команда show bgp ipv4 unicast summary также можно использовать для проверки обмена NLRI между узлами, как показано в примере ниже.
Маршруты BGP в глобальной таблице маршрутизации (RIB) отображаются с помощью команды show ip route bgp. В примере ниже показана эта команда. Префиксы взяты из сеанса eBGP и имеют AD 20, а метрика отсутствует.
BGP Route Advertisements from Indirect Sources (Анонсирование BGP маршрута из непрямых источников)
Как указывалось ранее, BGP следует рассматривать как приложение маршрутизации с двумя отдельными компонентами: BGP сессией и анонсированием маршрута. На рисунке ниже показана топология, в которой R1 устанавливает несколько маршрутов, полученных из статических маршрутов, EIGRP и OSPF. R1 может анонсировать эти маршруты к R2.
В примере ниже показана таблица маршрутизации для R1. Обратите внимание, что loopback на R3 была изучена через EIGRP, loopback на R4 достигается с использованием статического маршрута, а loopback на R5 изучена из OSPF.
В примере ниже показана установка в BGP префиксов loopback на R3 и R4 с использованием команды network. Указание каждого сетевого префикса, который следует анонсировать, может показаться утомительным. Loopback на R5 была изучена путем редистрибьюции OSPF прямо в BGP.
NOTE Редистрибьюция маршрутов, полученных от IGP, в BGP совершенно безопасно; однако редистрибьюция маршрутов, полученных от BGP, следует выполнять с осторожностью. BGP разработан для больших масштабов и может обрабатывать таблицу маршрутизации размером с Интернет (780 000+ префиксов), тогда как у IGP могут начаться проблемы со стабильностью с менее чем 20 000 маршрутов.
В примере ниже показаны таблицы маршрутизации BGP на R1 и R2. Обратите внимание, что на R1 next hop соответствует next hop, полученному от RIB, AS_Path пуст, а коды источника - IGP (для маршрутов, полученных из настроек анонсирования сети) или неполные (redistributed). Метрика переносится из протоколов маршрутизации IGP маршрутизаторов R3 и R5 и отображается как MED. R2 изучает маршруты строго из eBGP и видит только MED и origin codes.
Route Summarization
Суммирование префиксов экономит ресурсы маршрутизатора и ускоряет расчет best-path за счет уменьшения размера таблицы. За счет суммирование также получаем некоторое преимущество стабильности, т.к. при этом скрываются отвалившиеся маршруты на нисходящих маршрутизаторах тем самым сокращая отток маршрутизации. Хотя большинство провайдеров не принимают префиксы больше /24 для IPv4 (с /25 по /32), на момент написания этой статьи в Интернете все еще насчитывалось более 780 000 маршрутов, и они продолжают расти. Суммирование маршрута требуется для уменьшения размера BGP таблицы для Интернет-маршрутизаторов.
Суммирование маршрутов BGP на граничных маршрутизаторах BGP уменьшает вычисление маршрута на маршрутизаторах в ядре для полученных маршрутов или для анонсированных маршрутов. На рисунке ниже R3 суммирует все маршруты eBGP, полученные от AS 65100 и AS 65200, чтобы уменьшить вычисление маршрута на R4 во время прерывания соединения. В случае прерывания связи в сети 10.13.1.0/24 R3 удаляет все маршруты AS 65100, полученные непосредственно от R1, и идентифицирует те же префиксы сети через R2 с разными атрибутами пути (более длинный AS_Path). R3 должен анонсировать новые маршруты к R4 из-за этого падения линка, что является пустой нагрузкой на ЦП, поскольку R4 получает соединение только от R3. Если бы R3 суммировал диапазон префиксов сети, R4 выполнил бы best-path алгоритм один раз, и ему не нужно было бы запускать его во время флапания линка 10.13.1.0/24.
Существует два метода BGP суммирования:
- Static: Создайте статический маршрут к Null0 для суммированного префикса и затем анонсируйте его командой network. Недостатком этого метода является то, что суммированный маршрут всегда анонсируется, даже если сети недоступны.
- Dynamic: Сконфигурируйте агрегированный префикс сети. Когда маршруты жизнеспособных компонентов, соответствующие агрегированному префиксу сети, попадают в таблицу BGP, создается агрегированный префикс. Маршрутизатор-создатель этого агрегированного префикса устанавливает next hop в Null0 для этого префикса для предотвращения петель.
В обоих методах агрегации маршрутов в BGP анонсируется новый сетевой префикс с более короткой длиной префикса. Поскольку агрегированный префикс - это новый маршрут, маршрутизатор объявивший суммирование является отправителем для нового агрегированного маршрута.
Aggregate Address
Динамическое суммирование маршрутов выполняется в BGP address-family конфигурации с помощью команды aggregate-address network subnet-mask [summary-only] [as-set].
На рисунке ниже показано, что между маршрутизаторами R1 и R3 убран флапающий serial линк чтобы продемонстрировать агрегацию BGP маршрутов и полученный эффект.
На картинке не показаны, но предполагается что у каждого роутера есть интерфейс lo0 c адресом 192.168.х.х соответственно. Т. е у роутера R1 есть Lo0 интерфейс с адресом 192.168.1.1 и т.д
В следующем примере показаны таблицы BGP для R1, R2 и R3 до выполнения агрегации маршрутов. Тупиковые сети R1 (172.16.1.0/24, 172.16.2.0/24 и 172.16.3.0/24) анонсируются через все автономные системы вместе с loopback адресами роутеров (192.168.1.1/32, 192.168.2.2/32, and 192.168.3.3/32) и пиринговыми линками (10.12.1.0/24 и 10.23.1.0/24).
R1 агрегирует все тупиковые сети (172.16.1.0/24, 172.16.2.0/24 и 172.16.3.0/24) в префикс сети 172.16.0.0/20. R2 объединяет все адреса loopback в сетевой префикс 192.168.0.0/16. В примере ниже показана конфигурация R1, работающего с default IPv4 address family и R2, работающий без default IPv4 address family.
В примере ниже показаны таблицы маршрутизации для R1, R2 и R3 после настройки агрегирования на R1 и R2.
Обратите внимание, что префиксы сети 172.16.0.0/20 и 192.168.0.0/16 видны, но меньшие компоненты этих префиксов все еще существуют на всех маршрутизаторах. Команда aggregate-address анонсирует агрегированный маршрут в дополнение к исходным компонентам сетевых префиксов. Использование необязательного ключевого слова summary-only убирает исходные префиксы-компоненты в суммированном сетевом диапазоне. В примере ниже показана конфигурация с ключевым словом summary-only.
В примере ниже показана таблица BGP для R3 после добавления ключевого слова summary-only к команде агрегирования. Тупиковая сеть маршрутизатора R1 была объединена в префикс сети 172.16.0.0/20, а адреса loopback интерфейсов маршрутизаторов R1 и R2 были объединены в префикс сети 192.168.0.0/16. Ни одна из тупиковых сетей R1 или адреса loopback интерфейсов от R1 или R2 не видны на R3.
В примере ниже показаны таблица BGP и RIB для R2. Обратите внимание, что компоненты - адреса loopback интерфейсов, отсутствуют в BGP и не анонсируются R2. Кроме того, суммарный маршрут был установлен в Null0 в качестве механизма предотвращения петель.
Пример ниже показывает, что тупиковые сети маршрутизатора R1 были убраны (suppressed-подавлены), а суммарный сброшенный маршрут для сети 172.16.0.0/20 также был установлен в RIB.
Atomic Aggregate
Агрегированные маршруты действуют как новые маршруты BGP с более короткой длиной префикса. Когда маршрутизатор BGP суммирует маршрут, он не анонсирует информацию AS_Path, полученную до агрегации. Атрибуты пути BGP, такие как AS_Path, MED и BGP communities, не включаются в новое анонсирование BGP.
Atomic aggregate attribute указывает, что произошла потеря информации о пути. Чтобы продемонстрировать это наилучшим образом, предыдущая агрегация маршрутов BGP на R1 была удалена и добавлена к R2, так что теперь R2 объединяет сети 172.16.0.0/20 и 192.168.0.0/16 с отбрасыванием оригинальных маршрутов. В примере ниже показана конфигурация R2.
В следующем примере показаны таблицы BGP R2 и R3. R2 объединяет и отбрасывает тупиковые сети R1 (172.16.1.0/24, 172.16.2.0/24 и 172.16.3.0/24) в сеть 172.16.0.0/20. Префиксы - исходные компоненты сети поддерживают AS_Path 65100 на R2, в то время как агрегированная сеть 172.16.0.0/20 создается локально на R2.
С точки зрения R3, R2 не анонсирует тупиковые сети R1; вместо этого он объявляет сеть 172.16.0.0/20 как свою собственную. AS_Path для префикса сети 172.16.0.0/20 на R3 - это просто AS 65200 и не включает AS 65100.
Пример ниже показывает явную запись префикса 172.16.0.0/20 на R3. Информация NLRI маршрута указывает, что маршруты были агрегированы в AS 65200 маршрутизатором с RID 192.168.2.2. Кроме того, был установлен atomic aggregate attribute, чтобы указать на потерю атрибутов пути, таких как AS_Path в этом сценарии.
Route Aggregation with AS_SET
Чтобы сохранить историю информации о пути BGP, необязательное ключевое слово as-set может использоваться с командой aggregate-address. По мере того как маршрутизатор генерирует агрегированный маршрут, атрибуты BGP из агрегированных маршрутов-компонентов копируются на него. Настройки AS_Path из исходных префиксов хранятся в части AS_SET AS_Path. AS_SET, отображаемый в скобках, считается только одним hop-ом, даже если указано несколько AS.
В примере ниже показана обновленная конфигурация BGP R2 для суммирования обеих сетей с ключевым словом as-set.
В примере ниже снова показана сеть 172.16.0.0/20, теперь атрибуты BGP будут распространены на новый маршрут. Обратите внимание, что информация AS_Path теперь содержит AS 65100 как часть информации.
Вы заметили, что сеть 192.168.0.0/16 больше не присутствует в таблице BGP маршрутизатора R3? Причина этого в том, что на R2 агрегирует все loopback сети из R1 (AS 65100), R2 (AS 65200) и R3 (AS 65300). И теперь, когда R2 копирует атрибуты пути BGP всех маршрутов-компонентов в информацию AS_SET, AS_Path для сети 192.168.0.0/16 содержит AS 65300. Когда агрегированный маршрут анонсируется на R3, R3 отклоняет этот маршрут, потому что он видит свой собственный AS_Path в анонсе и думает, что это петля.
В примере ниже показана таблица BGP маршрутизатора R2 и атрибуты пути для агрегированной сетевой записи 192.168.0.0/16.
R1 не устанавливает сеть 192.168.0.0/16 по тем же причинам, по которым R3 не устанавливает сеть 192.168.0.0/16. R1 считает, что анонс является петлей, поскольку обнаруживает в анонсе AS65100. Это можно подтвердить, изучив таблицу BGP маршрутизатора R1, как показано в примере ниже.
Multiprotocol BGP for IPv6
Multiprotocol BGP (MP-BGP) позволяет BGP передавать NLRI для нескольких протоколов таких как IPv4, IPv6 и Multiprotocol Label Switching (MPLS) L3 (L3VPNs).
RFC 4760 определяет следующие новые функции:
- Модель нового address family identifier (AFI)
- Новые необязательные и нетранзитивные атрибуты BGPv4:
- Multiprotocol reachable NLRI (многопротокольной доступности NLRI)
- Multiprotocol недостижимый NLRI (многопротокольной недоступности NLRI)
Новый атрибут многопротокольной доступности NLRI описывает информацию о маршруте IPv6, а атрибут многопротокольной недоступности NLRI выводит маршрут IPv6 из обслуживания. Атрибуты являются необязательными и нетранзитивными, поэтому, если старый маршрутизатор не понимает атрибутов, информацию можно просто игнорировать.
Все те же основные функции и правила IPv4 path vector routing протокола также применимы к MP-BGP для IPv6. MP-BGP для IPv6 продолжает использовать тот же хорошо известный порт TCP 179 для пиринга сессий, который BGP использует для IPv4. Во время инициирующих согласование open сообщений, BGP пиры обмениваются возможностями. Расширения MP-BGP включают address family identifier (AFI), который описывает поддерживаемые протоколы, вместе с subsequent address family identifier (SAFI), которые описывают применяется ли префикс к таблице unicast или multicast маршрутизации:
- IPv4 unicast: AFI: 1, SAFI: 1
- IPv6 unicast: AFI: 2, SAFI: 1
На рисунке ниже показана простая топология с тремя разными AS и R2, образующим сессию eBGP с R1 и R3. Будем использовать показанную топологию в этом разделе.
IPv6 Configuration
Все продемонстрированные ранее правила конфигурации BGP применимы к IPv6, за исключением того, что IPv6 address family должно быть инициализировано, а neighbor активирован. Маршрутизаторы с адресацией только IPv6 должны статически определять BGP RID, чтобы разрешить создание сессий.
Протокол, используемый для установления сессии BGP, не зависит от анонсирования маршрута AFI/SAFI. TCP сессия, используемая BGP, является L4 протоколом, и он может использовать адрес IPv4 или IPv6 для формирования сессии смежности и обмена маршрутами.
NOTE Уникальная глобальная unicast адресация - это рекомендуемый метод для BGP пиринга, позволяющий избежать операционных сложностей. BGP пиринг с использованием link-local адреса может представлять опасность, если адрес не назначен интерфейсу вручную. Аппаратный сбой или перестановка кабеля изменят MAC-адрес, что приведет к новому локальному link-local адресу. Это приведет к потере сессии, поскольку автоконфигурация адреса без сохранения состояния создаст новый IP-адрес.
В следующем примере показана конфигурация BGP IPv6 для R1, R2 и R3 (картинка была выше). Пиринг использует глобальную unicast адресацию для установления сессии. BGP RID был установлен в IPv4 loopback формате. R1 анонсирует все свои сети через редистрибьюцию, а R2 и R3 используют команду network для анонсирования всех своих connected сетей.
NOTE Возможность IPv4 unicast маршрутизации объявляется по умолчанию в IOS, если только neighbor вручную не отключен в IPv4 address family или глобально в процессе BGP с помощью команды no bgp default ipv4-unicast.
Маршрутизаторы обмениваются AFI возможностями во время первоначального согласования сессии BGP. Команда show bgp ipv6 unicast neighbors ip-address [detail] отображает подробную информацию об успешном согласовании возможностей IPv6. В примере ниже показаны поля, которые необходимо проверить для установления сессии IPv6 и анонсирования маршрута.
Команда show bgp ipv6 unicast summary отображает состояния сессий, включая количество обмененных маршрутов и время работы сеанса.
В примере ниже показано состояние соседнего узла IPv6 AFI для R2. Обратите внимание на то, что состояние соседства (adjacencies) продолжается около 25 минут. Neighbor 2001:db8:0:12::1 анонсирует три маршрута, и neighbor 2001:db8:0:23::3 анонсирует три маршрута.
В примере ниже показаны IPv6 unicast таблицы BGP для R1, R2 и R3. Обратите внимание, что некоторые маршруты включают в себя неуказанный адрес (: :) next hop. Неуказанный адрес говорит, что префикс генерируется локально. Значение weight 32 768 также указывает, что префикс создан маршрутизатором локально.
BGP path attributes для маршрута IPv6 отображаются с помощью команды show bgp ipv6 unicast prefix/prefix-length. В следующем примере показано, что R3 проверяет loopback адрес R1. Некоторые общие поля, такие как AS_Path, origin и local preference, идентичны полям для маршрутов IPv4.
В примере ниже показаны IPv6 BGP записи маршрутов для R2.
IPv6 Summarization
Процесс для суммирования или агрегирования маршрутов IPv6 такой же, как и маршрутов IPv4. Формат идентичен, за исключением того, что конфигурация помещается в IPv6 address family с помощью команды aggregate-address prefix/prefix-length [summary-only] [as-set].
Давайте вернемся к предыдущему развертыванию IPv6, но теперь хотим суммировать все адреса loopback (2001:db8:0:1/128, 2001:db8:0:2/128 и 2001:db8:0:3/128) вместе с пиринговым линком между R1 и R2 (2001:db8:0:12/64) на R2. Конфигурация будет выглядеть, как показано в примере ниже.
В следующем примере показаны таблицы BGP на R1 и R3. Вы можете видеть, что все более мелкие маршруты были объединены и удалены в 2001:db8::/59, как и ожидалось.
Суммировать IPv6 loopback адреса (2001:db8:0:1/128, 2001:db8:0:2/128 и 2001:db8:0:3/128) довольно просто, поскольку все они попадают в IPv6 диапазон 2001:db8:0:0::/64. Четвертый hextet, начинающийся с десятичного значения 1, 2 или 3, будет занимать только 2 бита; диапазон можно легко суммировать в сетевой диапазон 2001:db8:0:0::/62 (или 2001:db8::/62).
Пиринговый линк между R1 и R2 (2001:db8:0:12::/64) требуется сначала рассмотреть в шестнадцатеричном формате, а не в десятичных значениях. Четвертый hextet несет десятичное значение 18 (не 12), что требует минимум 5 бит. В таблице ниже перечислены биты, необходимые для суммирования, IPv6 summary address и сети-составные части в итоговом диапазоне.
Пока пиринговый линк между R2 и R3 (2001:db8:0:23::/64) не суммировался и не удален, поскольку сеть все еще видна в таблице маршрутизации R1 (в примере выше). Шестнадцатеричное значение 23 (то есть 0x23) преобразуется в десятичное значение 35, для которого требуется 6 бит. Суммированная сеть должна быть изменена на 2001:db8::/58, чтобы произошло суммирование сети 2001:db9:0:23::/64. В примере ниже показано изменение конфигурации R2.
Пример ниже проверяет, что 2001:db8:0:23::/64 теперь находится в агрегированном адресном пространстве и больше не анонсируется R1.