
На данный момент мы реализовали значительную часть нашего парсера на Python в соответствии с указанной ниже схемой:
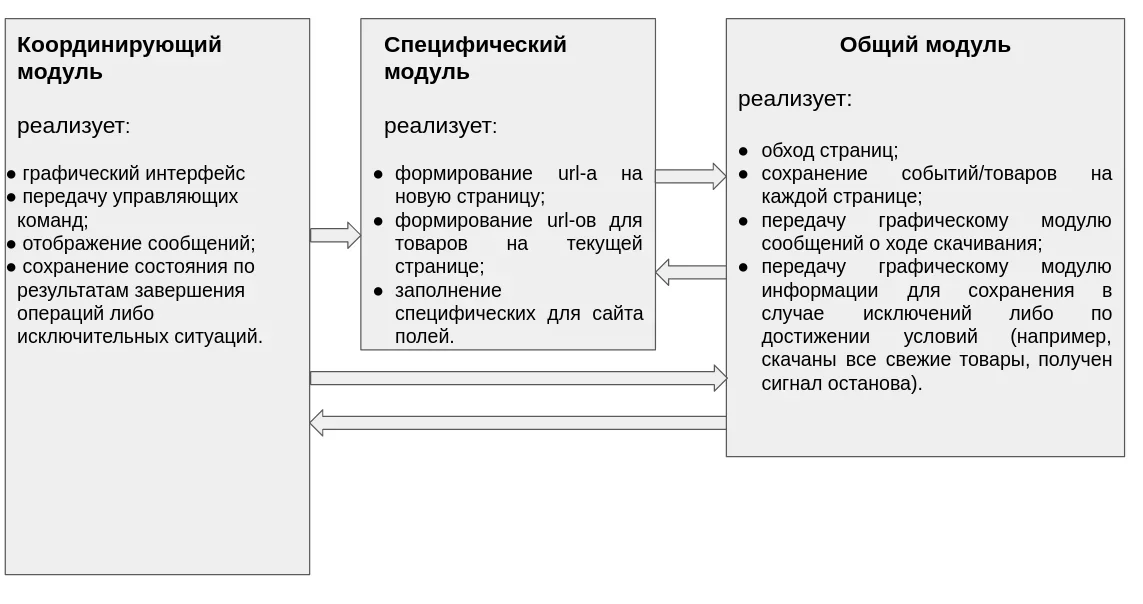
В частности, написали функции обхода страниц (подробнее здесь), перебора ссылок на записи на одной странице (подробнее здесь) и сбора данных по каждой ссылке на примере конкретного сайта (подробнее здесь). Также реализовали метод передачи адреса новой страницы в нестандартных ситуациях (подробнее здесь).
Принципиальным этапом является сохранение состояния в случае возникновения исключений, так как сайты, опасаясь проведения DDoS атак, защищаются, периодически разрывая соединение. Поэтому на этот случай необходимо все блоки программы, отвечающие за скачивание данных заключать в try/except с сохранением всех промежуточных результатов. При этом новый запуск программы должен также сопровождаться поиском сохраненного состояния для старта с места прерывания.
Например, для случая парсинга данных о проведенных поединках по смешанным единоборствам в рамках UFC, методы сохранения (save_class_params) и загрузки состояния (load_class_params) могли выглядеть следующим образом (реализованы в классе UFCFightsParser, привожу с конструктором для понимания значений полей):
class UFCFightsParser(ItemsParser):
def __init__(self,cur_url, events_url, delay, page_param, tag_container_events,tag_event, tag_container_el, tag_el, rec_ign_bef_stop_max=REC_IGN_BEF_STOP_MAX, pages_load_stop_num=PAGES_LOAD_STOP_NUM):
# страница со ссылками на события/турниры
self.events_url = events_url
# строчные описания контейнера и внутренних тегов с ссылками
# на все события на странице events_url
self.tag_container_events = tag_container_events
self.tag_event = tag_event
# параметр, отвечающий в events_url
# за номер страницы, для UFC - 'page'
self.page_param = page_param
# parse_url - метод ItemsParser для разбиения url
# на части: адрес сайта, относительный путь
# по папкам, параметры и их значения
self.url_base, self.url_add, self.params = self.parse_url(events_url)
# задержка при скачивании каждой страницы с сайта
self.delay=delay
# конструктор базового класса ItemsParser
super().__init__(cur_url, tag_container_el,tag_el, rec_ign_bef_stop_max, pages_load_stop_num)
events_hrefs_tags, _ = self.get_items_list_from2tags(self.events_url,self.tag_container_events,self.tag_event, self.delay)
# ссылки на все события на странице events_url
self.events_hrefs = [item.attrs['href'] for item in events_hrefs_tags]
self.events_num = len(self.events_hrefs)
# self.event_ind - индекс текущего события,
# которое ищем путем поиска
# его url в списке. Последний символ отсекаем, так как
# в настройках cur_url адрес задается с ? на конце
# для простоты отделения частей адреса
# от параметров в методе self.parse_url
self.event_ind = self.events_hrefs.index(self.cur_url[:-1])
# дата, место события, число зрителей
self.event_date, self.event_place, self.event_attendence = self.get_event_inf(cur_url,'i,class,b-list__box-item-title')
def save_class_params(self):
class_params_init = {}
class_params_init['cur_url'] = self.cur_url
class_params_init['cur_page'] = self.params[self.page_param]
class_params_init['records_pass_in_page_num'] = self.records_pass_in_page_num
class_params_init['events_url'] = self.events_url
class_params_init['event_ind'] = self.event_ind
class_params_init['events_hrefs'] = self.events_hrefs
class_params_init['event_date'] = self.event_date
class_params_init['event_place'] = self.event_place
class_params_init['event_attendence'] = self.event_attendence
# last_date - время самой старой записи
class_params_init['last_date'] = self.items_list[-1]['Date'] if not len(self.items_list)==0 else ''
return class_params_init
def load_class_params(self, params):
self.cur_url = params['cur_url']
self.params[self.page_param] = params['cur_page']
self.records_pass_in_page_num = params['records_pass_in_page_num']
self.events_url = params['events_url']
self.event_ind = params['event_ind']
self.events_hrefs = params['events_hrefs']
self.event_date = params['event_date']
self.event_place = params['event_place']
self.event_attendence = params['event_attendence']