
Источник: Nuances of Programming
Логистическая регрессия — это алгоритм классификации машинного обучения, используемый для прогнозирования вероятности категориальной зависимой переменной. В логистической регрессии зависимая переменная является бинарной переменной, содержащей данные, закодированные как 1 (да, успех и т.п.) или 0 (нет, провал и т.п.). Другими словами, модель логистической регрессии предсказывает P(Y=1) как функцию X.
Условия логистической регрессии
- Бинарная логистическая регрессия требует, чтобы зависимая переменная также была бинарной.
- Для бинарной регрессии фактор уровня 1 зависимой переменной должен представлять желаемый вывод.
- Использоваться должны только значимые переменные.
- Независимые переменные должны быть независимы друг от друга. Это значит, что модель должна иметь малую мультиколлинеарность или не иметь её вовсе.
- Независимые переменные связаны линейно с логарифмическими коэффициентами.
- Логистическая регрессия требует больших размеров выборки.
Держа в уме все перечисленные условия, давайте взглянем на наш набор данных.
Данные
Набор данных взят с репозитория машинного обучения UCI и относится к прямым маркетинговым кампаниям (телефонный обзвон) португальского банковского учреждения. Цель классификации в прогнозировании успеха подписки клиента (1/0) на срочный депозит (переменная y). Загрузить этот набор данных можно здесь.
Эти данные предоставляют информацию о клиентах банка, которая включает 41,188 записей и 21 поле.
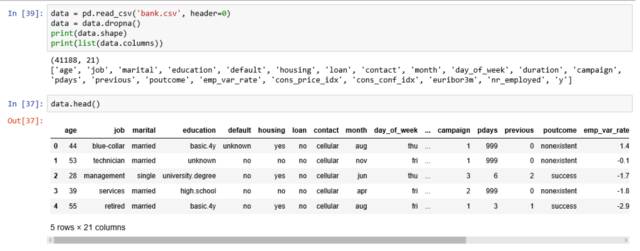
Вводные переменные
- age — возраст (число);
- job — вид должности (категории: “admin” (администратор), “blue-collar” (рабочий), “entrepreneur” (мелкий предприниматель), “housemaid” (горничная), “management” (руководитель), “retired” (на пенсии), “self-employed” (самозанятый), “services” (сфера услуг), “student” (учащийся), “technician” (техник), “unemployed” (не трудоустроен), “unknown” (неизвестно));
- marital — семейное положение (категории: “divorced” (разведён), “married” (замужем/женат), “single” (холост/не замужем), “unknown” (неизвестно));
- education — образование (категории: “basic.4y”, “basic.6y”, “basic.9y” (базовое), “high.school” (высшая школа), “illiterate” (без образования), “professional.course” (профессиональные курсы), “university.degree” (университетская степень), “unknown” (неизвестно));
- default — имеет ли просроченные кредиты (категории: “no” (нет), “yes” (да), “unknown” (неизвестно));
- housing — имеет ли жилищный кредит (категории: “no” (нет), “yes” (да), “unknown” (неизвестно));
- loan — имеет ли личный кредит (категории: “no” (нет), “yes” (да), “unknown” (неизвестно));
- contact — вид связи (категории: “cellular” (мобильный), “telephone” (стационарный));
- month — месяц последнего обращения (категории: “jan” (январь), “feb” (февраль), “mar” (март), …, “nov” (ноябрь), “dec” (декабрь));
- day_of_week — день недели последнего обращения (категории: “mon” (понедельник), “tue” (вторник), “wed” (среда), “thu” (четверг), “fri” (пятница));
- duration — продолжительность последнего обращения в секундах (число). Важно: этот атрибут оказывает сильное влияние на вывод (например, если продолжительность=0, тогда y=’no’). Продолжительность не известна до момента совершения звонка, а по его завершению y будет, очевидно, известна. Следовательно этот вводный параметр должен включаться только в целях эталонного тестирования, для получения же реалистичной модели прогноза его следует исключать.
- campaign — число обращений, установленных в процессе этой кампании и для этого клиента (представлено числом и включает последнее обращение);
- pdays — число дней, прошедших с момента последнего обращения к клиенту во время предыдущей кампании (число; 999 означает, что ранее обращений не было);
- previous — число обращений, совершённых до этой кампании (число);
- poutcome — итоги предыдущей маркетинговой кампании (категории: “failure” (провал), “nonexistent” (несуществующий), “success” (успех));
- emp.var.rate — коэффициент изменения занятости (число);
- cons.price.idx — индекс потребительских цен (число);
- cons.conf.idx — индекс потребительского доверия (число);
- euribor3m — 3-х месячная европейская межбанковская ставка (число);
- nr.employed — количество сотрудников (число).
Прогнозируемая переменная (желаемая цель):
y —подписался ли клиент на срочный вклад (двоично: “1” означает “Да”, “0” означает “Нет”).
Колонка образования в наборе данных имеет очень много категорий, и нам нужно сократить их для оптимизации моделирования. В этой колонке представлены следующие категории:
Давайте сгруппируем “basic.4y”, “basic.9y” и “basic.6y” и назовём их “basic” (базовое).
После группировки мы получим следующие колонки:
Изучение данных
- Процент не подписавшихся — 88,73458288821988;
- Процент подписавшихся — 11,265417111780131.
Наши классы не сбалансированы, и соотношение не подписавшихся к подписавшимся составляет 89:11. Прежде чем мы перейдём к балансировке, давайте проведём дополнительное исследование.
Наблюдения:
- Средний возраст потребителей, купивших срочный депозит, выше, чем тех, кто его не купил.
- pdays (дни, прошедшие с момента последнего обращения к клиенту) по понятным причинам ниже для тех, кто купил депозит. Чем меньше показатель pdays, тем лучше память о последнем звонке и выше шансы успешной продажи.
- На удивление, показатель campaigns (число обращений или звонков, сделанных во время текущей кампании) меньше для потребителей, купивших срочный депозит.
Мы можем вычислить средние категориальные значения для других категориальных переменных, вроде образования и семейного положения, чтобы получить более точное представление о данных.
Визуализации
Частота покупки депозита во многом зависит от должности клиента. Следовательно этот показатель может послужить хорошим фактором прогноза итоговой переменной.
Семейное же положение не является существенным прогнозирующим фактором.
Образование выглядит хорошим фактором для прогноза итоговой переменной.
День недели может не являться хорошим прогнозирующим фактором.
Месяц может оказаться хорошим прогнозирующим фактором.
Большинство клиентов банка в этом наборе данных находятся в возрасте от 30 до 40 лет.
Poutcome (итоги предыдущей маркетинговой кампании) кажется хорошим прогнозирующим фактором.
Создание индикаторных переменных
Это переменные со всего двумя значениями — ноль и единица.
Наши итоговые колонки данных будут:
data_final=data[to_keep]
data_final.columns.values
Over-Sampling при помощи SMOTE
После создания наших обучающих данных я увеличу частоту выборки не подписавшихся, используя алгоритм SMOTE (синтетическая техника дублирования примеров миноритарного класса). На высоком уровне SMOTE:
- создаёт синтетические образцы на основе выборок минорного класса (не подписавшихся) вместо создания их копий;
- случайно выбирает одного из ближайших k-соседей и использует его для создания схожих, но случайно изменённых новых сведений.
Мы будем реализовывать SMOTE в Python.
Теперь у нас есть идеально сбалансированные данные. Вы могли заметить, что я выполнил over-sampling только для обучающих данных, поскольку в таком случае информация из тестовых данных не используется для создания синтетических сведений, и, следовательно, не произойдёт её утечки в обучающую модель.
Рекурсивное устранение признаков
Рекурсивное устранение признаков (RFE) основывается на повторяющемся конструировании модели и выборе лучше всех или хуже всех выполняемого признака, отделения этого признака и повторения цикла с оставшимися. Этот процесс применяется, пока в наборе данных не закончатся признаки. Цель RFE заключается в отборе признаков посредством рекурсивного рассмотрения всё меньшего и меньшего их набора.
При помощи RFE мы выбрали следующие признаки: “euribor3m”, “job_blue-collar”, “job_housemaid”, “marital_unknown”, “education_illiterate”, “default_no”, “default_unknown”, “contact_cellular”, “contact_telephone”, “month_apr”, “month_aug”, “month_dec”, “month_jul”, “month_jun”, “month_mar”, “month_may”, “month_nov”, “month_oct”, “poutcome_failure”, “poutcome_success”.
Реализация модели
p-значения для большинства переменных меньше 0.05, за исключением всего четырёх, следовательно мы их удалим.
Подгонка модели логистической регрессии
Прогнозирование результатов тестового набора и вычисление точности.
Точность классификатора логистической регрессии для тестового набора: 0,74.
Матрица ошибок
[[6124 1542]
[2505 5170]]
Результат показывает, что у нас 6124+5170 верных прогнозов и 2505+1542 ошибочных.
Вычисление точности, полноты, F-меры и поддержки
Приведу цитату из Scikit Learn:
Точность является соотношением tp/(tp + fp), где tp является числом верно-положительных, а fp — числом ложно-положительных. Точность — это интуитивно понятная способность классификатора не помечать выборку как положительную, если она отрицательна.
Полнота— это пропорция tp/(tp +fn), где tp представляет число верно-положительных результатов, а fn — число ложно-отрицательных. Полнота является интуитивно понятной способностью классификатора находить все положительные выборки.
Показатель F-бета можно интерпретировать как взвешенное гармоническое среднее точности и полноты, где лучшим значением этого показателя будет 1, а худшим 0.
Показатель F-бета определяет, насколько значимость полноты больше, чем точности, опираясь на фактор бета. Например, beta = 1.0 означает, что полнота и точность равно важны.
Поддержка — это число вхождений каждого класса в y_test.
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))
Интерпретация: из всего тестового набора 74% рекламируемых срочных депозитов понравились клиентам. Из всего тестового набора 74% клиентов предпочли рекламируемые срочные депозиты.
ROC-кривая
Кривая рабочей характеристики приёмника (ROC) является ещё одним популярным инструментом, используемым с бинарными классификаторами. Пунктирная линия представляет ROC-кривую полностью случайного классификатора. Хороший классификатор остаётся от неё максимально далеко (по направлению к верхнему левому углу).
Jupyter notebook, использованный для написания этой статьи, доступен здесь.
Читайте также:
Читайте нас в телеграмме и vk
Перевод статьи Susan Li: Building A Logistic Regression in Python, Step by Step.