
NVIDIA представила новое поколение игровых видеокарт Ampere 1 сентября, однако первоначальная презентация почти не содержала технических подробностей. Теперь, спустя несколько дней, компания обнародовала документацию, которая проясняет, откуда берётся то впечатляющее преимущество в производительности, которым выделяются на фоне предшественников видеокарты GeForce RTX 30-й серии.
Многие сразу обратили внимание, что в официальных характеристиках GeForce RTX 3090, GeForce RTX 3080 и GeForce RTX 3070 на сайте NVIDIA было указано ошеломляюще большое число CUDA-процессоров.
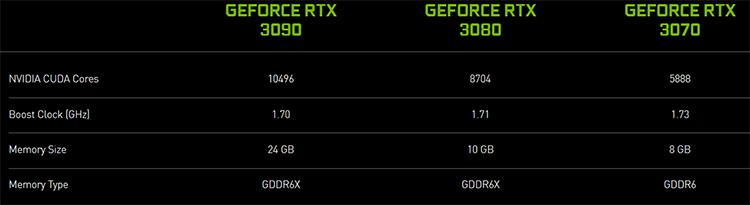
Как оказалось, удвоение FP32-производительности игровых процессоров Ampere по сравнению с Turing действительно имеет место, и связано оно с изменением архитектуры базовых строительных блоков GPU – потоковых процессоров (SM).
В то время как SM в GPU поколения Turing имели один вычислительный тракт для операций с плавающей точкой, в Ampere каждый потоковый процессор получил по два тракта, которые в сумме могут выполнить до 128 FMA-операций за такт против 64 у Turing. При этом половина из имеющихся исполнительных устройств Ampere способна исполнять как целочисленные (INT) операции, так и 32-битные операции с плавающей точкой (FP32), в то время как вторая половина устройств предназначена исключительно для FP32-операций. Такой подход применён ради экономии транзисторного бюджета, исходя из того, что игровая нагрузка порождает значительно больше FP32-, чем INT-операций. Впрочем, в Turing комбинированных исполнительных устройств не было вообще.
Одновременно для того, чтобы обеспечить усиленные потоковые процессоры необходимым объёмом данных, NVIDIA на треть увеличила объём L1-кеша в SM (с 96 до 128 Кбайт), а также вдвое увеличила его пропускную способность.
Другое важное усовершенствование в Ampere касается того, что CUDA-, RT- и тензорные ядра теперь могут работать полностью параллельно. Это позволяет графическому движку, например, использовать DLSS для масштабирования одного кадра, и в то же время на CUDA- и RT-ядрах рассчитывать следующий кадр, сокращая простои функциональных узлов и поднимая общую производительность.
К этому нужно добавить, что RT-ядра второго поколения, которые реализованы в Amрere, могут вычислять пересечения треугольников лучами в два раза быстрее, чем это происходило в Turing. А новые тензорные ядра третьего поколения в два раза улучшили математическую производительность при работе с разреженными матрицами.
Удвоение скорости расчёта пересечений треугольников в Ampere должно существенно повлиять на производительность ускорителей GeForce RTX 30-й серии в играх с поддержкой трассировки лучей. По утверждению NVIDIA, именно эта характеристика выступала узким местом в архитектуре Turing, в то время как показатели скорости расчётов пересечений лучей ограничивающих параллелепипедов нареканий не вызывали. Теперь же баланс производительности в трассировке оптимизирован, и более того, в Ampere оба типа операций с лучами (с треугольниками и параллелепипедами) могут выполняться параллельно.
В дополнение к этому для RT-ядер в Ampere была добавлена новая функциональность, позволяющая интерполировать положение треугольников. Это может быть использовано для размытия объектов в движении, когда не все треугольники в сцене находятся в постоянной позиции.
Для иллюстрации всего перечисленного, NVIDIA показала прямое сравнение, как распределяется нагрузка на графические процессоры Turing и Ampere в трассировке лучей в Wolfenstein Youngblood в разрешении 4K. Как следует из представленной иллюстрации, Ampere заметно выигрывает в скорости построения кадра как за счёт более быстрых математических FP32-вычислений, так благодаря RT-ядрам второго поколения, а также параллельной работе разнородных ресурсов GPU.