
В Pandas имеется большой набор групповых операций, позволяющих извлекать различные полезные сводные показатели. Для группировки значений таблицы по одному или нескольким меткам/индексам у объектов DataFrame существует метод groupby.
Группировка по одной метке/индексу
Предположим вы работаете с таблицей со сведениями о героях игры Dota2 следующего вида (сведения загружены в DataFrame df):
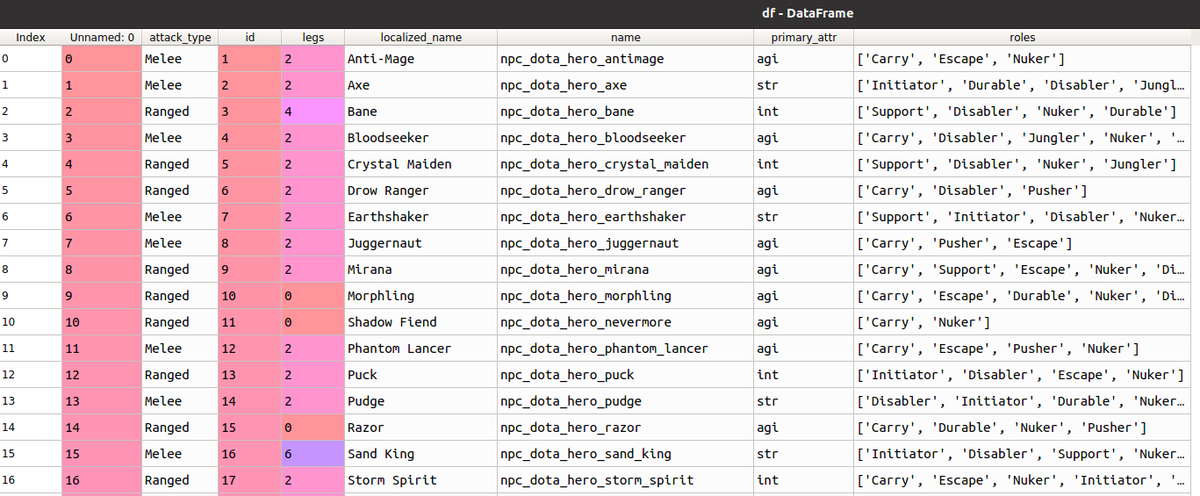
Ваша задача - разделить героев по количеству ног (legs) с выводом числа объектов, попавших в каждую группу. Для этого потребуется набрать команду:
df.groupby('legs')['localized_name'].nunique()
если уверены, что герои не повторяются в строках, то можно и так:
df.groupby('legs')['localized_name'].count()
Выборка определенных столбцов в группах
В сгруппированном по некоторой метке/индексу объекте вам может понадобится описательная статистика не всех, а заданных столбцов. В этом случае их можно перечислить явно. Например, пусть у нас имеется следующая таблица о растениях и концентрации в них некоторых веществ (concentrations):
Вы хотите найти среднюю концентрацию веществ в каждом из родов растений (genus). Для этого можно набрать следующую команду: concentrations.groupby(['genus'])[['sucrose', 'alanin', 'citrate', 'glucose', 'oleic_acid']].mean()
Применение нескольких сводных статистик
Пользуясь предыдущими данными, покажем, как применить к формированным группам сразу несколько функций. Например, вы хотите вычислить минимальную, среднюю и максимальную концентрации аланина (alanin) среди видов рода Fucus.
Сначала достигнем промежуточный результат - сгруппируем по родам и вызовем метод aggregate для применения списка функций:
concentrations.groupby(['genus']).aggregate(['mean','min', 'max'])
Все, что нужно сделать для нашей выборки это извлечь нужные значения из строки и столбца:
concentrations.groupby(['genus']).aggregate(['mean','min', 'max']).loc['Fucus','alanin']
Применение произвольных функций к группам
Допустим, мы хотим посчитать размах (максимум - минимум) сахарозы в бурых, зелёных и красных растениях (колонка - group). Для этого нам потребуется метод apply:
concentrations.groupby('group')['sucrose'].apply(lambda g:g.max() - g.min())
Группировка по нескольким меткам/индексам
Вернемся к вышеуказанной таблице с характеристиками героев Dota2. Сгруппируем данные по колонкам attack_type и primary_attr и выберем самый распространённый набор характеристик (roles). Для этого воспользуемся следующей командой:
df.groupby(['attack_type','primary_attr'])['roles'].count()
Группировка по двум меткам может понадобится при решении вопроса вывода данных о средних заработках людей (например, Лупы и Пупы) за задачи из разных категорий. Рассмотрим следующую таблицу:
Для получения необходимых данных воспользуемся следующей командой:
df.groupby(['Executor', 'Type'], as_index=False).mean()
Кстати параметр as_index регулирует будут ли значения группировки интерпретироваться в результирующем объекте как индекс или как новые столбцы. По умолчанию значение равно True и метки группировки формируют индекс: