
Знание математической статистики помогает в быту, в частности позволяет осуществлять покупки эффективнее. Смоделируем ситуацию - вы только открыли свое кафе и собираетесь приобрести крупную партию (n единиц) товара, например, помидоров. При этом известно, что вы можете заказать продукцию у ряда поставщиков, каждый из которых в большинстве случаев поставляет товар по одинаковой цене и качества, в соответствии со следующим нормальным распределением:
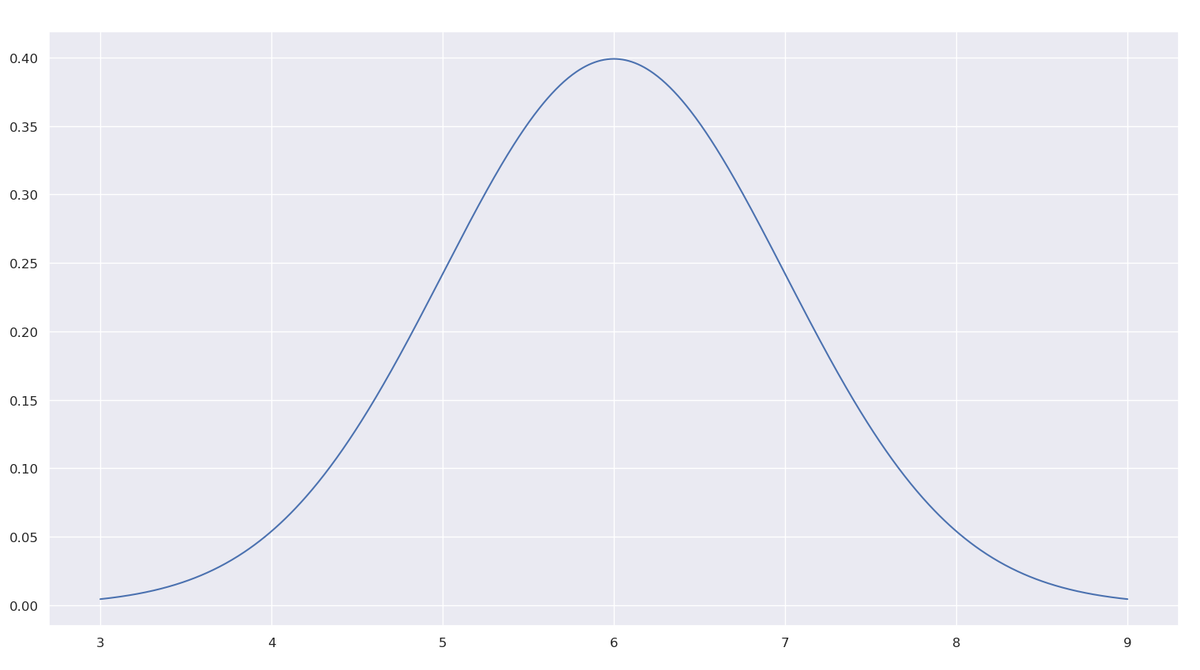
То есть качество оценивается по 10-бальной шкале и находится чаще всего в области 6. Это нормальное распределение, о котором подробнее я писал ранее. В демонстрационных целях среднее положено равным 6, а стандартное отклонение - 1.
Качество 5 и выше вас устраивает, в то время как ниже может нанести имиджевый ущерб популярности кафе. Как поступить, чтобы минимизировать шансы снижения авторитета вашего заведения? Купить все n партий товара у одного поставщика или по одной у разных?
Как видно из графика, при покупке у одного поставщика значительный процент продукции будет качества ниже 5. В то же время при покупке у каждого поставщика по одной партии в соответствии с законами теории вероятности и математической статистики (распределение среднего n независимых случайных величин имеет то же математическое ожидание, как и у каждого и в n раз меньшую дисперсию) общее качество будет подчиняться следующему распределению (в демонстрационных целях n положено равным 100):
Таким образом, средняя величина качества при покупке по одной партии у 100 поставщиков останется прежней, в то время как существенно снизится разброс значений (стандартное отклонение станет равным 1/10) и шансы, что вся продукция окажется качеством ниже пяти будут практически равными нулю.
Следует отметить, что схожие рассуждения применимы при покупке ценных бумаг, валюты, недвижимости (если вы крупный инвестор). Фактически данная теория лежит в основе финансовой диверсификации, вложения средств в индексные фонды и биржевые инвестиционные фонды (ETF). Основная цель этого - гарантировать стабильный доход с минимальными рисками. В то же время отмечу, что тем самым минимизируются как риски убытков, так и прибыли. В нашем же примере, купив продукцию у n поставщиков, мы одновременно снизили свои шансы получить высококачественную товар.
Ниже привожу код построения графика распределения качества продукции у одного поставщика (на Python):
import scipy.stats as stats
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
SMALL_SIZE = 12
MEDIUM_SIZE = 14
BIGGER_SIZE = 18
plt.rc('font', size=MEDIUM_SIZE) # controls default text sizes
plt.rc('axes', titlesize=SMALL_SIZE) # fontsize of the axes title
plt.rc('axes', labelsize=MEDIUM_SIZE) # fontsize of the x and y labels
plt.rc('xtick', labelsize=SMALL_SIZE) # fontsize of the tick labels
plt.rc('ytick', labelsize=SMALL_SIZE) # fontsize of the tick labels
plt.rc('legend', fontsize=SMALL_SIZE) # legend fontsize
plt.rc('figure', titlesize=BIGGER_SIZE) # fontsize of the figure title
if __name__=='__main__':
x = np.linspace(3,9,1000)
norm = stats.norm(6,1)
plt.plot(x,norm.pdf(x))
и качества всей продукции при покупке каждой отдельной партии у 100 поставщиков:
import scipy.stats as stats
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
SMALL_SIZE = 12
MEDIUM_SIZE = 14
BIGGER_SIZE = 18
plt.rc('font', size=MEDIUM_SIZE) # controls default text sizes
plt.rc('axes', titlesize=SMALL_SIZE) # fontsize of the axes title
plt.rc('axes', labelsize=MEDIUM_SIZE) # fontsize of the x and y labels
plt.rc('xtick', labelsize=SMALL_SIZE) # fontsize of the tick labels
plt.rc('ytick', labelsize=SMALL_SIZE) # fontsize of the tick labels
plt.rc('legend', fontsize=SMALL_SIZE) # legend fontsize
plt.rc('figure', titlesize=BIGGER_SIZE) # fontsize of the figure title
if __name__=='__main__':
n_distr = 100
n_point_new = 1000
distr = stats.norm(6,1)
distr_whole = [[distr.rvs() for _ in range(n_point_new)] for _ in range(n_distr)]
df = pd.DataFrame(distr_whole)
means = df.mean(axis=0)
sns.kdeplot(means)