
Источник: Nuances of Programming
Команда HarperDB построила первую и единственную написанную на Node.js БД, которая уникальным образом применяет SocketCluster для распределенных вычислений. Кайл Бернарди, технический директор и сооснователь HarperDB, недавно выступил с докладом, в котором рассказал о внутренних процессах SocketCluster, а также произвел обзор кода, подчеркнув принципы функционирования SocketCluster в рамках структуры базы данных. Можете полноценно ознакомиться с этим докладом по прикрепленной ссылке (англ.), я же в этой статье просто обобщу все основные акценты, собрав их в единую картину.
HarperDB — это новая база данных, а именно структурированное объектное хранилище с возможностями SQL. В нашей архитектуре присутствует множество компонентов, а в качестве протокола связи мы реализовали интерфейс WebSocket, который используется для обмена данными и метаданными схемы между разными узлами. В дальнейшем он будет расширен на выполнение таких распределенных операций, как SQL и NoSQL, что увеличит возможности запросов. Вместо простого распределения и детерминированного обмена данными он также получит возможность выполнять запросы внутри кластера.
Распределенное вычисление
- Каждый узел обрабатывает транзакции и хранилище в соответствии с требованиями ACID локально и независимо от других узлов.
- Каждый узел может подключаться (или нет) к любому другому узлу и отправлять и/или получать транзакции для любой таблицы.
- Передача в реальном времени метаданных схемы и транзакций основаны на определяемой клиентом топологии и выполняются детерминированным образом.
- Все узлы имеют возможность дополнять недополученные в связи со сбоями сети/сервера данные, что исключает утрату транзакций.
Распределенные вычисления могут иметь очень сложные топологии, следовательно для их обработки нам было нужно нечто простое и одновременно гибкое. Мы исходим из предположения, что узел может оказаться офлайн в любой момент времени и при возвращении в строй должен иметь возможность наверстать упущенное. Мы рассматривали варианты, которые были слишком тяжеловесны или не позволяли узлам общаться с брокером сообщений, что, естественно, противоречило изначальной идее, подразумевающей удобство нашей технологии для пользователей.
Топологии
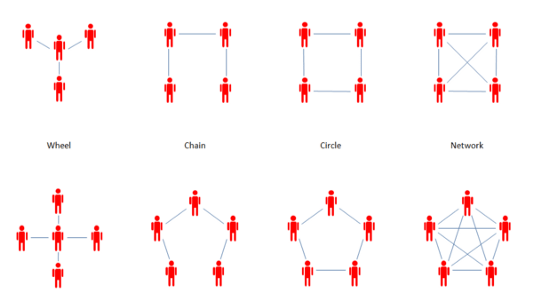
Здесь мы видим несколько примеров топологии. Слева представлен наиболее простой вариант, где внешние узлы связаны подключаются к центральному. Это типичная топология периферийных вычислений. Вы также можете встретить цепные, линейные, круговые и др. варианты. Мы же старались учесть все возможные их виды. В данном случае преодолеть ограничения нам помогает технология WebSockets, предоставляющая дуплексное соединение, потому что если нам понадобится двусторонняя связь, но сервер не сможет подключиться к узлам за брандмауэром, то желаемого мы не добьемся.
Первая попытка
- Socket.io;
- внедрение логики Socket.io в родительский процесс;
- дублирование данных для каждого подключенного узла;
- тесная связь распределенной логики с основной.
Мы попробовали внедрить Socket.io в родительский процесс, используя библиотеку кластера, чтобы параллельные процессы выполнялись “до неприличия параллельно”, позволяя нам производить масштабирование, но тогда мы думали, что все узлы смогут сообщаться с родителем, который будет распределять данные по кластеру. У нас также были сложности со способом хранения данных, так как изначально мы использовали отдельное хранилище для каждого узла, чтобы он имел возможность при необходимости дополнять данные после отключения. Кроме того, распределенная логика была тесно интегрирована в нашу основную логику БД.
Усвоенные уроки
- Socket.io сложно масштабировать;
- необходимо улучшенное хранилище транзакций;
- необходим шаблон Pub / Sub (издатель-подписчик);
- нужны сторонние наблюдатели для получения ими данных в реальном времени и публикации этих данных в потоке;
- нужны безопасные соединения между узлами.
Мы поняли, что Socket.io сложно масштабировать. Для этого нам пришлось внедрять, к примеру, Redis или использовать другие библиотеки, что существенно усложняло процесс обработкой множества зависимостей. Кроме того, мы выполняли загрузку и отправку данных между узлами напрямую, после чего поняли, что модель pub/sub для каждой таблицы была бы гораздо уместнее. Мы также хотели разрешить сторонним наблюдателям получать потоки данных в реальном времени и публиковать их (аналогично Kafka). Еще нам была нужна повышенная безопасность.
Что такое SocketCluster
- Быстрый, легковесный, хорошо масштабируемый движок для сервера, работающего в реальном времени;
- гибкий фреймворк;
- встроенная JWT аутентификация;
- встроенная обработка подключений/агентов/каналов/передачи сообщений.
Спустя нескольких неудачных попыток мы остановились на SocketCluster. Нашей команде этот инструмент был неизвестен, но после недолгого ознакомления все по достоинству оценили его легковесность, масштабируемость, гибкость, а также способность устанавливать детерминированные соединения между узлами (настройкой процесса занимались администраторы). Помимо прочего, в нем имеется встроенная обработка сообщений, каналов, агентов и пр., что избавляет вас от необходимости ее самостоятельной реализации. SocketCluster также без проблем урегулирует ситуацию, в которой вы создаете несколько экземпляров сервера, так как в нем реализован агент, отвечающий за обеспечение получения каждым подписчиком ожидаемых данных.
Случаи применения SocketCluster: чаты, блокчейн, онлайн игры, а также наш случай с распределенной базой данных.
Почему SocketCluster
- Node.js;
- скорость, производительность и масштабируемость;
- встроенная JWT аутентификация;
- управление агентами/подключениями/каналами/сообщениями;
- доставка сообщений в порядке их отправления;
- полностью основан на промисах;
- удобное добавление пользовательской логики;
- легкое изменение/добавление данных сообщений.
Джон Гро-Дюбуа, создатель и управляющий SocketCluster, постоянно обновляет и дорабатывает этот проект. За последний год он существенно улучшил свою технологию, полностью перейдя от использования обратных вызовов к промисам, в добавок сделав всех слушателей асинхронными итераторами, которые, основываясь на событиях, позволяют вам получать сообщения в том порядке, в каком они были отправлены, сохраняя тем самым целостность транзакций.
Как мы используем SocketCluster
- распределенное дублирование данных;
- каждый узел является агентом, обрабатывающим сообщения;
- HarperDB использует простую модель pub/sub, поэтому мы дублируем данные, публикуя их на разных каналах, на которые подписываются разные узлы, и которые могут распределяться горизонтально;
- поддерживаем безопасность между узлами;
- в дальнейшем планируем расширить структуру для распределения всех операций Core HarperDB.
Мы используем его в качестве распределенного фреймворка для распределения данных. Логика Socket.io была тесно привязана к логике нашей базы данных, поэтому мы хотели выполнять его как вспомогательное средство, что оказалось легко сделать при помощи SocketCluster. Этот инструмент имеет встроенную JWT аутентификацию, обеспечивая тем самым высокий уровень безопасности, а также поддерживает SSL между узлами, давая нам возможность убеждаться в отсутствии неавторизованных подключений к нашей сети.
Обзор кода
Этот образец кода поможет вам понять, чего мы старались добиться и как нам это удалось. Еще раз скажу, что подробный обзор кода вы можете просмотреть в выступлении Кайла, о котором упоминалось в начале, я же приведу лишь несколько ключевых моментов. Данный проект показывает, как создать сервер SocketCluster с интегрированным REST API и SocketCluster-клиент для подключения к экземпляру этого сервера.
У нас есть директория classes, где размещается основная логика, а также директория Postman и пр. Суть проекта — создание сервера SocketCluster, для чего нам достаточно просто импортировать его библиотеку, инстанцировать HTTP-сервер и прикрепить его к серверу SocketCluster. Так мы получаем работоспособные серверы с минимумом настроек, которые можно будет добавить позднее. Далее интересный момент с обработкой слушателей и промежуточного ПО. Вот асинхронная функциональность итератора:
Затем мы создаем слушателя подключений. Мы можем прослушивать удаленные вызовы процедуры, что мы и делаем для активации аутентификации между клиентом и сервером. Подключение будет установлено, и при соединении мы сможем вызвать этого слушателя события авторизации. Для этого нам нужно только прослушивать и активировать промисы в клиенте SocketCluster. Сервер прослушивает попытки активировать это событие авторизации, после чего производится простая проверка. Пройдя аутентификацию, мы можем установить токен, отметить его как успешный и продолжить — поскольку процесс осуществляется итератором, нам необходимо сообщить ему о необходимости продолжить, иначе он просто остановится.
Помимо этого, мы создаем на сервере промежуточную обработку входящих подключений, исходящих подключений, необработанных входящих подключений, а также подтверждения подключений. В данном случае у нас происходит поток промежуточной обработки, каждый тип которой содержит свои присвоенные к его действиям данные. Далее происходит проверка аутентификации сокета, на основе которой запрашиваемые им действия либо принимаются, либо отклоняются. После этого идет пользовательская инструкция if, которая при публикации данных по всему кластеру вызывает функцию для записи этих данных на диск. Далее мы блокируем попадание этих данных в обмен, чтобы гарантировать их передачу на сервер и избежать получения подписчиками двойных сообщений.
У нас есть слушатели, промежуточная обработка, и мы дополнительно создаем REST сервер. Мы передаем в него ссылку на SocketCluster сервер, а также на повторно используемый здесь HTTP-сервер, задействуя для REST сервера тот же порт, что и Websocket сервер.
Теперь мы запускаем сервер, подключаемся и проходим аутентификацию.
Итак, мы можем записывать в базу данных, определять, с какого канала хотим считывать данные и видеть, что клиент эти данные получает. Мы можем добавить еще один сервер, после чего все их подключить и производить дублирование данных, а также определять издателя/подписчика. Поскольку наши сервера REST и SocketCluster связаны, мы также можем ссылаться на функции классов в обоих, что очень удобно. Кроме того, мы отслеживаем исходящие подключения, перебирая определенный в теле массив subcriptions. Если мы делаем публикацию, то нам нужно проследить за локальным обменом, потому что клиент сокета должен наблюдать за данным каналом и передавать эти данные другому узлу.
Теперь у нас есть подключение, которое полноценно дублирует данные между узлом 1 и узлом 2, гарантируя именно детерминированный их обмен, при котором мы решаем какие данные и куда нужно направить. Такой случай применения актуален для наших клиентов особенно в сценарии периферийных вычислений (англ.): предположим, у вас на производстве установлены устройства, отслеживающие данные о температуре. Вас же интересует только, когда эти данные пересекут определенный порог. Поэтому при превышении указанного порога данные отправляются с устройства в отдельную таблицу и далее в командный центр, остальные же необработанные данные находятся только на периферийном узле, который их накапливает и со временем удаляет. Таким образом мы передаем пользователям только необходимые им данные.
Давайте добавим еще один сервер, чтобы продемонстрировать кое-что интересное. Мы можем создать вызов процедуры для всех узлов, подключенных к нашему узлу, что позволит нам выполнить чтение с них по персональному каналу. Для этого нужно просто отправить вызов удаленной процедуры каждому отдельному узлу, чтобы просмотреть каждый хранящийся в директории данных файл и получить из них недостающую информацию. Это может пригодиться, когда вы некоторое время были офлайн и хотите обновить данные прежде, чем начать передавать транзакции.
Этот процесс примечателен тем, что я совершаю вызов к узлу 1 для получения его данных, а узлы 2 и 3 при этом выполняются параллельно, на что в целом уходит 7 мс (в то время, как на вызов одного только узла 3 уходит также 7 мс). Здесь становится понятно преимущество параллельного получения данных. Обратите также внимание, что фрагментация данных по нескольким узлам позволяет использовать более дешевое оборудование без утраты производительности, избавляя вас от необходимости задействовать громоздкие монолиты мощных серверов. SocketCluster предоставляет и многие другие возможности, но здесь перечислены основные, которые мы оценили, применяя этот инструмент для распределенных вычислений.
Читайте также:
Перевод статьи Margo McCabe: Using SocketCluster for Distributed Computing in a Unique Way