
Со всеми статьями можно ознакомитя по ссылке.
В прошлой статье мы настроили совместный доступ к общим папкам и прва доступа разных пользователей к этим папкам.
Теперь давайте разберёмся, что такое датасеты (datasets) в zfs и какие возможности они нам пердоставляют. А возможности есть и, поверьте мне, они довольно "вкусные".
Повторю здесь часть предыдущей статьи, в которой я описывал, что же такое датасеты.
Что такое Dataset?
Для конечного пользователя Dataset это обычная папка, в которой он может хранить свои файлы и создавать другие папки. Но на самом деле Dataset в файловой системе ZFS обладает дополнительными возможностями, такими как:
- сжатие хранимых данных;
- установка ограничения предельного размера dataset'a;
- резервирование гарантированного размера дискового пространства;
- дедупликация;
- создание снимков состояния (snapshot);
- доступ к предыдущим версиям файлов, сохранённых в snapshot'ах, при помощи обычного проводника Windows.
Рассмотрим подробнее каждый из этих пунктов.
Сжатие хранимых данных
Файловая система ZFS поддерживает несколько подключаемх модулей сжатия данных:
- lz4 - алгоритм сжатия данных без потерь, ориентированный на высокую скорость сжатия и распаковки. Используется в ZFS по-умолчанию.
- zstd - это быстрый алгоритм сжатия, обеспечивающий высокую степень сжатия. Он также предлагает специальный режим для небольших данных, называемый сжатием с использованием словаря;
- zle - это кодирование нулевого уровня - оно не сжимает обычные данные, но сжимает большие последовательности нулей. Полезно для полностью несжимаемых наборов данных (например, JPEG, MP4 или других уже сжатых форматов), поскольку он игнорирует несжимаемые данные, но сжимает свободное пространство в окончательных записях;
- lzjb - алгоритм сжатия данных без потерь, изобретённый в 1998 году для сжатия аварийных дампов программ и данных в файловой системе ZFS. Ранее использовался в ZFS по-умолчанию, но сейчас уступил место более быстрому и эффективному lz4.
Для домашнего использования рекомендуется использовать алгоритм по-умолчанию lz4.
Ограничение предельного размера и резервирование дискового пространства
Датасет позволяет установить квоту на свой максимальный размер. Это полезно когда необходимо ограничить максимальный размер датасета выделенного для данных конкретного пользователя или, например, максимальный размер датасета, в котором хранятся файлы бэкапа. Т.е. можно ограничить размер, например, в 100Гб или в 1Tб, при том, что в пуле (pool) гораздо больше свобдного места.
В связи с тем, что датасеты используют общее пространство пула, в котором они созданы, то может оказаться, что общая квота на все датасеты превышает размер пула. Т.е. при размере пула в 2Tб вполне возможно создать 3 датасета с квотой 1Тб каждый. В результате, если на двух датасетах будет занято по 750Гб, то на третьем, даже при заданной квоте в 1Тб, получится разместить не более 500Гб.
Что же делать, если нам необходимо гарантированно предоставить пользователю или программе, использующей датасет, некоторый объём дискового простарнства?
Для предоставления пользователю датасета с гарантированным дисковым пространством необходимо зарезервировать место в датасете. Фактически, после резервирования, в датасете может и не быть никаких данных, но свободное пространсво пула уменьшится на величину зарезервированного пространства и вы всегда будете иметь возможность записать в датасет объём данных не меньше чем зарезервировали в нём места. Возвращаятсь к предыдущем примеру с общим пространством пула в 2Тб, можно зарезервировать в одном пуле 1 Тб, а в двух других выставить квоту в 1Тб. И тогда в первом датасете вы точно сможете записать 1 Тб данных, а суммарный объём двух других датасетов не сможет превысить 2Тб пула минус 1Тб резерва первого дтасета.
Дедупликация
Данный подраздел представлен в информационных целях. И не рекомендуется к применению для домашних NAS, если вы не точно не знаете, что делаете, т.к. включение опции дедупликации ведёт к значительному потребелнию ресурсов центральноо процессора и оперативной памяти.
Файловая система ZFS записывает данные поступающие на диск блоками размером по-умолчанию 128Кб. В зависимости от типа хранимых данных есть вероятность хранения на дисках одних и тех же повторяющихся блоков. Дедупликация позволяет, при записи на диск, определять дублирует ли записываемый блок уже существующий и, если такой блок ранее уже записан на диск, то повторная запись блока не происходит, а вместо этого устанавливается ссылка на уже существующий идентичный блок, тем самым экономя место на диске. Информация о блоках хранится в оперативной памяти в специальной таблице DDT.
В связи с тем, что при записи данных на диск при включённой дедупликации, по-мимо вычисления контрольной суммы блока, которую проводит ZFS, необходимо дополнительно проверить является ли данный блок дубликатом, то возрастает нагрузка на центральный процессор сетевого хранилища.
Таблица DDT занимает в памяти объем равный количеству дедуплицированных блоков умноженный на 320, т.к. каждая запись в таблице занимает 320 байт. В связи с этим повышаются требования к объёму оперативной памяти необходимой для функционирования NAS.
Определить объём дополнительной оперативной памяти штатными средствами графической оболочки предоставляемой <подставить на выбор: TrueNAS, OpenMediaVault, XigmaNAS> не представляется возможным. По различным данным, для нормального функционирования хранилища с включенной дедупликацией потребуется от 1,25 до 5Гб свободной памяти на 1 Тб хранимых данных.
Для продвинтуых пользователей есть возможность выполнить команду "sudo zdb -S pool_name", которая подсчитает количество блоков, и умножить количество блоков на 320. Тем самым получить объём таблицы DDT в байтах. Для примера в моём хранилище сейчас 0,85Тб данных и количество блоков равняется 6,74 миллиона. Т.е. размер таблицы дедупликации будет составлять 6,74М * 320 байт = 2,1 Гб. Итого: 2,1/0,85=2,5 Гб на 1 Тб данных.
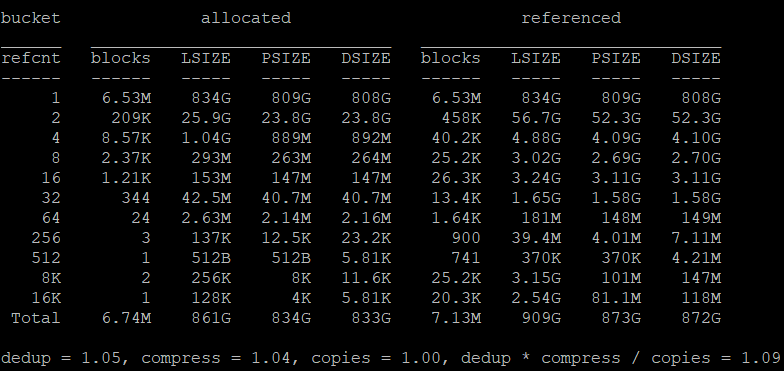
Так какое же место экономит дедупликация для обычного пользователя?
Опять же на примере моего NAS - по результатам выполнения команды "sudo zdb -S pool_name" можно увидеть, что дедупликация моих данных уменьшает их всео на 5% (dedup = 1.05).
При стоимости 4 терабайтного HDD в 4500 рублей проще заранее купить лишний диск в хранилище, чем использовать дедуплицаию и для её функционирования покупать 12-16 Гб дополнительной оперативной памяти для освобождения 5% от того же самого 4 терабайтного диска. Т.к. планка памяти на 16 Гб будет равна стоимости HDD, но вместо полноценных 4 Тб вы получите только 4*5%=200Гб при тех же затратах. Пусть даже 4Тб в режиме зеркалирования превратятся в 2Тб - это в 10 раз больше дискового пространства при тех же финансовых затратах.
Снапшоты (Snapshots)
Снимки состояния (snapshots) позволяют практически моментально (вне зависимости от объёма данных) создавать "слепок" состояния dataset'a, а затем открывать его по мере необходимости и доставать от туда удалённые файлы или вообще возвращаться к состоянию снимка полностью.
А что с размером этих самых снимков спросите вы? Снимок занимает места столько сколько занимают места изменённые файлы после создания снимка. Т.е. если вы создали снимок на 1 ТБ, а затем изменили файл размером 1 МБ, то снимок будет весить 1 МБ.
Снимки можно создавать по расписанию, например каждый день или каждый час. И если вдруг вы случайно удалили какой-то файл на сетевом хранилище, то его можно будет вернуть из предыдущего снимка.
Доступ к файлам в снапшотах можно осуществлять штатными средствами Проводника Windows через Контекстное меню -> Свойства -> Предыдущие версии.
В следющей статье перейдём от теории к практике и поговорим о том как создать датасет, установить квоты, настроить сжатие, регулярные снапшоты и доступ к предыдущим версиям файлов через проводник Windows.
Спасибо, что дочитали до конца! Обязательно подписывайтесь на канал!