Здравствуйте. В прошлом году мы отсняли серию передач по теме цифровой трансформации. На наш Youtube-канал можно и нужно подписаться вот тут. Делая эти передачи, мы поняли, что есть большое количество технологических вещей, которые являются мотором, позволяющим делать новые эффективные бизнесы. Это интересно, поэтому мы решили снять серию передач DZ Online: TECH, которая посвящена тому, что именно находится «под капотом» у современных бизнес-машин.
В этой серии мы будем разговаривать и с компаниями, которые применяют новые решения, и с компаниями, которые их создают. Первым гостем передачи стал Иван Панченко, заместитель генерального директора Postgres Professional.
Добрый день, Иван. Postgres массово воспринимается как инструмент импортозамещения. И самым известным драйвером его применения является идея «давайте заменим какую-нибудь западную СУБД на Postgres». При этом известно, что у него есть достаточно много собственных ценностей. Я бы хотел по ним кратко пройтись. Если мы выбираем, не глядя «импорт - не импорт», а с чистого листа - почему так?
Добрый день. Во-первых, большинство выбирает Postgres не из-за импортозамещения. Понятно, что действительно есть государственные меры, ограничения импорта иностранного софта. Postgres Pro есть в реестре, поэтому он пригоден для импортозамещения. На самом деле, это мировая тенденция все больше выбирать Postgres. Мы видим только ее отражение. Возможно то, что у нас выразилось в импортозамещении, на самом деле, следствие каких-то более глубинных, фундаментальных процессов.
Postgres созрел. Это хорошая альтернатива более старым коммерческим базам данных. Во всем мире сейчас понимают, что Postgres — это продукт такого же класса, как киты: Oracle, Microsoft SQL Server и DB2, про последний из которых уже почти забыли, но тем не менее, это хороший продукт.
Но, так или иначе, DB2 постепенно куда-то уплывает из рынка, а Oracle, Microsoft SQL на нем есть. И Postgres — это что-то третье, что сейчас в мировом масштабе вплывает в рынок. Надо сказать, что вплывает достаточно давно — 10 лет назад, когда в Postgres появилась хорошая поддержка Windows. Когда в нем появилась репликация, его начали воспринимать; о нем начали говорить как о базе данных для бизнеса, промышленности и чего-то серьезного.
Ты сейчас все равно говоришь в картине «были два хороших, есть еще один неплохой». Но наверняка есть вещи, которые его ставят вперед и заставляют предпочитать его остальным.
Да, таких вещей несколько. Во-первых, это то, что Postgres является опенсорсным (open source) продуктом со специфической лицензией. При этом у него есть коммерческие клоны. Один из них наш. Но то, что он происходит от опенсорсного продукта — это само по себе является большим преимуществом.
Вторая тема, что Postgres — это база данных с высокой степенью расширяемости. Это тоже было драйвером его развития.
Надо сказать, что степень расширяемости Postgres — это как раз то место, где наш русский вклад наиболее заметен. Последние 15-17 лет наша команда занимается в основном механизмами расширяемости.
Например, в Rambler в 2000 году, где я впервые работал вместе с моими нынешними коллегами по компании, мы использовали расширяемость Postgres для того, чтобы поднять производительность новостной службы Rambler в 30 раз. Как? Мы —программисты, владеющие языком C и умеющие читать документацию. Эти две вещи позволили нам создать новый тип индексов для быстрого поиска по массивам, что выходит за рамки классической реляционной модели, но полезно.
В частности, в Rambler замена лишнего джоина (join) на массив, в котором можно искать по хитрому индексу, в 30 раз повысила производительность. Надо понимать, что тогда все контентные проекты Rambler крутились на машинках, чья мощность не превышала мощности современного смартфона: Pentium 2, 400 МГц, 500 Мб памяти. Если повезет, то Pentium 3 (он тогда появился) до 800 МГц. Таких Pentium 3 могло быть 2 штуки в сервере. И на всем этом обслуживались миллионы запросов.
Понятно, что тогда приходилось весьма серьезно оптимизировать код, иначе это все бы не работало. Помогла расширяемость Postgres. Посидели, подумали, и в приемлемые сроки, можно сказать за месяц, сделали то, что потом легло в основу всего, что сейчас есть в Postgres, связанного с JSON, с полнотекстовым поиском.
Благодаря этому в Postgres достаточно быстро появилась поддержка слабоструктурированных данных. Что это такое? Это ключ-значения, грубо говоря. В 2004 году нами было сделано в Postgres расширение Hstore для хранения внутри одного поля базы данных информации типа ключ-значения. Тогда это был еще не JSON, он зашел в моду потом. А тогда был Hstore. Почему Hstore? Мы смотрели на Perl, в котором есть хэш (hash), и вот мы хэш с практически таким же синтаксисом сделали в Postgres.
Вначале эта штука существовала как отдельный экстеншн (extension), потом была закоммичена (commit) в основной набор того, что входит в Postgres. И она была столько же популярна. То есть JSON обогнул ее по популярности совсем недавно.
Получается, что вы в некотором смысле поставили точку в этом дурацком обсуждении SQL и noSQL, создав СУБД, которая обладает свойствами и того и другого одновременно.
В каком-то смысле, да. Из noSQL мы взяли хорошее, а именно сравнительную гибкость, при этом без потери транзакционности, без потери целостности данных и всего, что бывает обычно в нормальных СУБД.
Итак, Hstore. Но Hstore был одноуровневым. То есть хэш одноуровневый. Это не JSON, просто хэш. И плюс массивы в Postgres были до нас. Мы сделали поддержку индексов, то есть можно было достаточно быстро искать по тому, что входит в массивы, и по тому, что лежит внутри Hstore, как по ключам, так и по значениям. Вот это полезная вещь. Народ ей начал пользоваться по всему миру. Потом появился JSON. Он появились недавно, году в 2011-2012 в Postgres. Было три разных попытки его реализовать. Потом все эти попытки выкинули, и сделали другим способом. Вначале JSON просто был текстом, который лежит в специальном поле.
Это ваша команда делала JSON?
Нет, наша команда сделала для JSON важную вещь. Когда JSON появился в Postgres, это было просто текстовое поле, и для того чтобы извлечь оттуда что-нибудь, какое-нибудь значение поиска приходилось каждый раз парсить JSON. Конечно, это работало медленно, но позволяло хранить многоуровневые данные.
Но в таком текстовом поле смысла немного. Я, например, в своих проектах и так хранил в текстовых полях слабоструктурированные данные, просто не называя это полем специального типа. Но вопрос в том, что с этим JSON надо было еще и эффективно работать. И то, что мы сделали уже своей командой в 2014 году - это JSON-B.
Он быстрее за счет того, что уже разложен и распаршен (parsing). Распаршен так, чтобы быстро можно было по ключу достать значение. Когда мы сделали JSON-B, прикрутили к нему возможность искать по индексам, тогда он стал действительно популярным.
Окей. Возвращаясь к специфическим свойствам: что еще есть такого, что отличает Postgres от других СУБД и является причиной применять его?
Все, что мы так долго говорили про JSON — все это проявление гибкости Postgres. В нем есть много мест, в которых его можно расширять. Другая сторона гибкости — это поддержка геоданных. Ровно так же, как были сделаны специальные индексы, например, для поиска по JSON, по массивам и по текстам, примерно через то же самое место было сделаны индексы для быстрого поиска по геоинформации, по пространственным данным. Там мы тоже приложили свою достаточно большую русскую руку к этому делу.
В результате - PostGIS, это такой очень распространенный в мире способ работы с геоинформационными данными.
Пользователи разрабатывают для Postgres экстеншены под свои проекты? Это существенный объем его применения?
Нет, естественно, это какие-то «сливки» сверху. Есть люди, которым это становится нужно, потому что их задача дорастает до этого. Это, прежде всего, универсальная база данных, которая очень хорошо поддерживает все стандарты и которая уж точно подойдет практически для любой задачи.
Если вы начинаете стартап, например - возьмите Postgres, не ошибетесь. Потому что, во-первых, он функционально расширяем. А во-вторых, если вы используете его опенсорсную версию, то не становитесь заложником лицензии, которую надо приобретать.
Тебе как сотруднику коммерческой копании говорить это, наверное, не очень радостно?
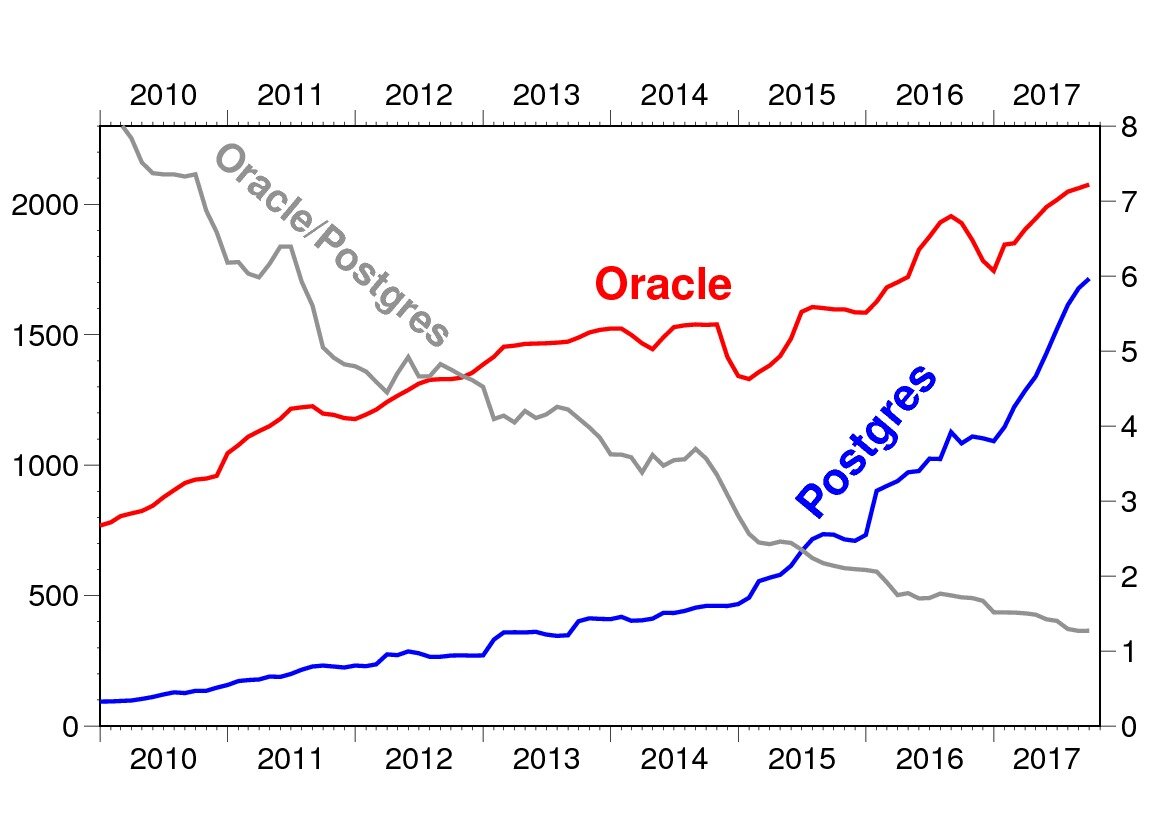
Это законы природы, против которых не попрешь. Есть open source, и есть бизнес на open source. И это достаточно необычная вещь, отличающаяся от обычного бизнеса. Но в будущем роль open source, судя по всему, будет расти. По крайней мере, это видно по успеху Postgres и по надоевшему всем графику Gartner, что опенсорсная база данных все чаще и чаще используется, и никуда от этого не деться.
Вы как компания, зачем вы нужны? Вот он опенсорс: пошел, скачал и все хорошо же?
На самом деле, пошел, скачал, но уткнулся в проблему. Рано или поздно люди утыкаются в проблему. Понятно, что большинству пользователей подойдет опенсорсная версия. У них не будет проблем, у них небольшие базы, они не вырастут. Но в некоторых случаях нужна помощь профессионала.
Раньше модель была простой. В данном случае я говорю о Postgres, потому что разные продукты находятся на разных стадиях этого эволюционного пути. Postgres изначально был просто университетским проектом. Люди не думали о деньгах; им было интересно решить задачу. Потом он был добровольческим проектом: люди делали для себя. При этом они работали в каких-то компаниях, как наша.
Ну, как вы в Rambler сделали решение.
Rambler — хороший пример. Мы сделали, потому что нам это было надо. Нас совершенно не волновали бизнес-пользователи. Нужно ли это кому-то еще или нет.
Postgres-компании вначале стали возникать не в России, а в других странах. Впервые такая компания возникла в Японии, правда, на деньги Fujitsu. Там было инвестировано достаточно много. И она начала заниматься разработкой в Postgres и около-Postgres вещей. Потом в достаточно короткий срок после этого появился второй квадрант (2nd Quadrant) в Англии, и в Америке Enterprise DB. Это все компании, которые зарабатывают на Postgres. Все эти компании начинают с того, что они исполняют заказы. Они занимаются...
Заказной разработкой.
Заказной разработкой на уровне СУБД. Мы тоже этим занимаемся, и занимались такими вещами, когда еще не были компанией, потому что Postgres расширяем. «Нам надо, чтобы полнотекстовый поиск искал не только вот так, но еще и правильным образом игнорировал наши французские акценты, или наши немецкие умлауты. Доделайте это — мы вам заплатим». Или: «JSON - очень хорошая штука. Вот бы к нему приделать индекс. И тогда наш портал бесплатных объявлений будет летать чуточку быстрее, чем все остальные».
Вот такие ребята действительно финансировали разработку, платя отдельным разработчикам или в некоторых случаях заказывая молодым, только что появившимся компаниям какие-то фичи, которые хотелось получить. А потом постепенно начала возникать потребность в коммерческих версиях Postgres.
Почему, и вообще, откуда взялись эти коммерческие форки (fork)? Прежде всего, надо сказать, что у Postgres такая хитрая лицензия, которая легально позволяет делать из него коммерческий продукт. BSD-подобная лицензия. Это никакой не GPL. Вы можете взять хотя бы тот же код, хоть даже не внося в него никаких изменений, оставить там две строчки из лицензионного соглашения, дописать к нему еще что-нибудь свое, и написать, что это мой «Вася Пупкин DB» и я ее продаю. Пойти на базар и продавать хоть за миллиарды - пожалуйста, не важно. Купит хоть кто-нибудь у Васи Пупкина «Вася Пупкин DB» или нет — это отдельный вопрос. Скорее всего, нет. А если он туда привнесет что-то свое? И этим начали заниматься.
У нас есть такая картинка, где зелеными и красными флажочками обозначены коммерческие и некоммерческие форки Postgres. Их достаточно много. Мы насчитали 40-50 штук. Большинство из них, естественно, не успешные: они загибаются, о них забывают. Какие-то большие организации, типа Amazon или Salesforce, могут сделать форк для себя, например. Самые известные коммерческие форки — это, конечно, Greenplum, EnterpriseDB. В том числе, наш Postgres Pro, японский Fujitsu Enterprise Postgres.
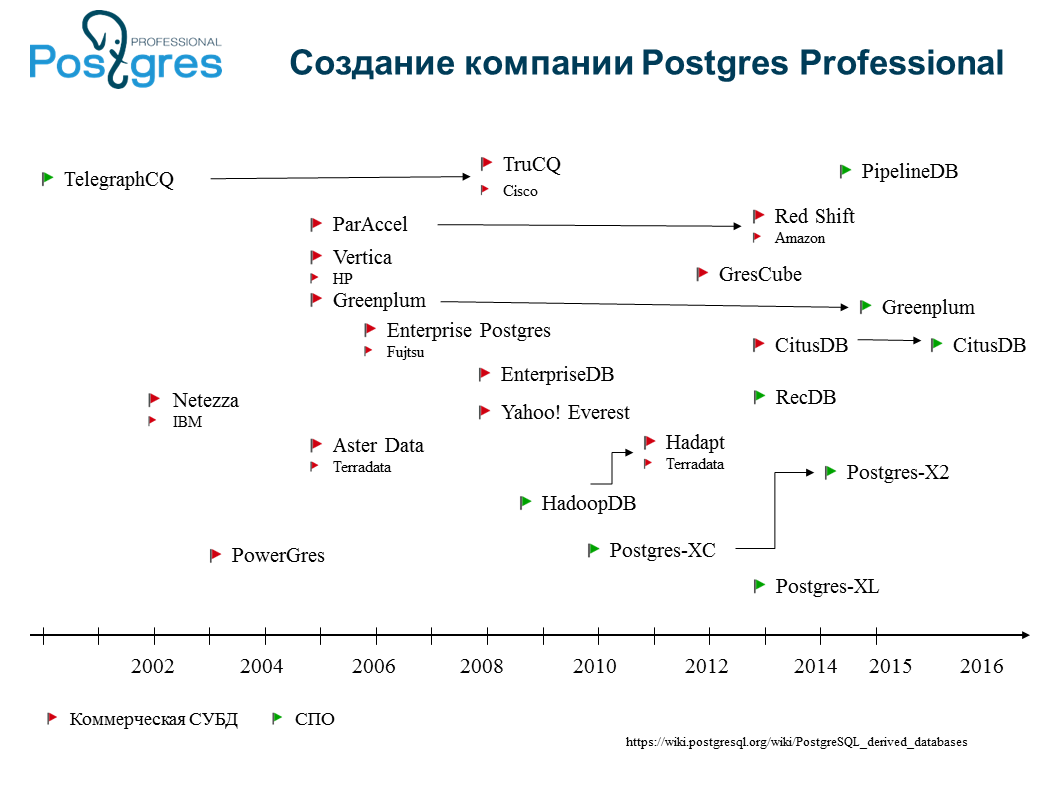
Англичане тоже совсем недавно enterprise-версию Postgres сделали. Для чего? Есть специализированные форки, например, Greenplum — это база данных для массивных аналитических расчетов с большим параллелизмом. Они взяли Postgres примерно десятилетней давности, очень сильно изменили планировщик, дописали туда работу с распределенными запросами, правда, потеряв при этом транзакционную целостность. Но для аналитических баз это неважно: там все уже лежит, и надо собрать и правильным образом распределить запрос по серверам. Они сделали Greenplum.
Эта штука используется, в том числе, и у нас в России. В частности, «Тинькофф Банк» хвастался, что у них это есть. Хорошая вещь, которая имела определенный коммерческий успех, но отстала от open source, потому что имела большой уровень несовместимости. Они очень сильно поменяли планировщик, сделали много хорошего, конечно, за это их можно похвалить, но развитие open source ушло в другую сторону. А тут главное не отойти далеко. Чем дальше отходишь, тем труднее потом мерджить.
Первый пример — это когда сделали версии Postgres, которые обладают некоторой специфической функциональностью. Это один из примеров, почему коммерческие компании возникают. А какие еще есть?
Greenplum сделали действительно крупную функциональную вещь, которая отодвигает Postgres сильно вбок. При этом это уже не универсальный продукт, но хорошо решающий важную востребованную задачу.
Другая группа форков — это к которой как раз относится наш Postgres Pro и Enterprise DB. Последние, как ни странно, несмотря на всю свою американскую природу, занимаются миграцией с Oracle.
В Америке тоже переходят с Oracle, потому что дорого платить за каждый «чих». Не все хотят так, и не у всех есть чем платить. Поэтому Enterprise DB предлагает по всему миру услуги по миграции с Oracle. И для того, чтобы проще переползать, они пошли по пути реализации в Enterprise DB каких-то фичей, которые есть в Oracle.
А что такое наш Postgres Pro? Мы решили не идти по этому пути, хотя какие-то фичи из Oracle, например, асинхронные автономные транзакции, мы тоже сделали. Но в большой перспективе мы не видим путь следования за Oracle. Потому что «следовать за» значит, что вы всегда будете отставать, и все равно никогда не будете 100% совместимыми, и все равно придется постоянно доказывать свою хотя бы частичную совместимость. Это сложная проблема.
Несмотря на то, что вы можете написать парсер Oracle'ового языка PSQL; слава богу, он документирован синтаксически, но очень строгой документации на его семантику вы не найдете. Более того, для полной совместимости вам придется воспроизводить «баг в баг». Вот попробуйте сделать это, и потом докажите, что это действительно так. Мы поняли, что на самом деле это полностью не решает проблему миграции. Мы решили, что лучше двигаться вперед. Лучше просто делать лучший продукт.
С другой стороны, обязательно ли в такой картине делать совместимость на уровне полного покрытия, я уж не говорю про «баг в баг»? Задача заключается в том, чтобы закрыть условные 80% расходов при миграции.
Это действительно так кажется, но на практике окажется, что когда вы мигрируете систему, это выглядит следующим образом: вам дают готовую систему. Это черный ящик, завернутый в черную бумагу, перевязанный черной веревочкой. Вы не знаете, что внутри. Есть ли там эти 80% или она чуть-чуть вылезает? Очень часто бывает так, что разработано методом «тяп-ляп» в 3 этажа, и строители первого этажа уже давно канули куда-то.
И поэтому, чтобы мигрировать в эту штуку, вам приходится делать reverse engineering - даже не для того, чтобы переписать, а для того, чтобы понять, работает она или нет. То есть, если у вас есть идеальное тестовое покрытие - тогда да, вы можете говорить...
Чего не бывает никогда, конечно же..
…Вы можете говорить: «Заменяем движок, запускаем тесты. 100% прошло, все верифицировано. Поехали». В реальности так не бывает. Это идеальный случай. И поэтому оказывается, что вы реализуете на 80%, а остальным все равно будете мучиться, причем заранее вы не знаете с чем. У миграции есть другие, гораздо более весомые проблемы.
У каждого продукта, у каждой СУБД есть достоинства. У Postgres, например, это работа с JSON и с массивами, о которых мы говорили. Многие вещи, которые на Oracle оптимально пишутся вот так, на Postgres оптимально пишутся по-другому. Поэтому, если вы будете мигрировать «в тупую», то вы получите минимально работающее подмножество, совместимое и с тем, и с другим. Вы не будете использовать преимущества ни старой базы данных, ни новой.
Давай два слова о будущем. Куда все это идет? Убьете ли вы всех конкурентов?
Я не думаю, что мы убьем всех конкурентов. В принципе, у нас такие хорошие, «ласковые» цели. Мы пришли не убивать, а строить. Наша задача - создать очень хорошую базу данных. Желательно лучшую.
А что это такое? Каков критерий этой хорошести? Я сомневаюсь в том, что у Microsoft задача сделать очень плохую базу данных.
Да, естественно, все к этому идут. Поэтому в мире баз данных сейчас есть какие-то тенденции. А поскольку объемы данных растут быстрее, чем все остальное, соответственно, основная тенденция баз данных сейчас — это распределенность. Те, кто лучше будут решать задачу распределенной базы данных — те будут молодцы.
С нами был Иван Панченко. Спасибо, Иван.
Спасибо.