Начало третьего занятия в newprolab началось с теста. Тест был на знание MapReduce. После которого мы разобрали эту модель подробнее:

Еще нашел интересные примеры на хабре по теме.
После теста мы вдарились в практику. Решали задачки. Добавлю их сюда, чтобы в будущем была возможность к ним вернуться и вспомнить алгоритмы решения:
Первая: В огромном тексте необходимо подсчитать сколько раз в нем встречается каждое слово.
Эту мы сделали быстро, потому что большинство уже сталкивалось с подобными задачами при работе с меньшим по размеру текстом, и знает алгоритм.
Вторая задача была уже сложнее и для того, чтобы ее решить я выходил к доске.
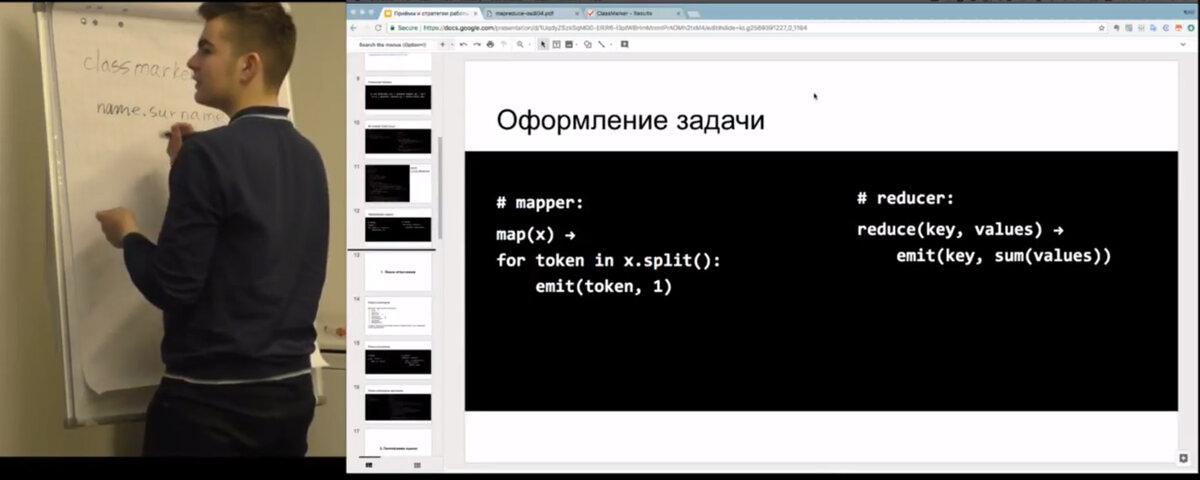
Вторая: Даны студенты и их оценки, нужно вывести людей, у которых средняя оценка по всем предметам > 4,5.
А после получения результатов задачи мы построили гистограмму и запустили решение на кластере.
И третья задачка: Есть два файла, в одном ученики и их оценка, а в другом ученики и их любимые предметы, и нужно было выяснить какой средний балл у учеников по их любимому предмету.
Вот как раз эту задачку мы не успели решить, но разобрали подробно. Поэтому будет легко её закончить.
И да, конечно же, все задачи, которые я описал выше решались по принципу MapReduce.