
Недавно была опубликована новость об обнаруженных в процессорах (ЦП) производства Intel уязвимостей, которые получили названия Spectre и Meltdown, как оказалось уязвимости частично затрагивают так же ЦП производства AMD и даже ARM.
В срочном порядке разработчики выпускают обновления для операционных систем, закрывающих описанные уязвимости, но у обновлений имеется существенный недостаток, так как производительность ЦП может снизиться на 30%, обусловлено это тем, что в качестве меры защиты осуществляется изоляция памяти ядра (Kernel Page Table Isolation), которая делает ядро «невидимым» для текущих процессов. Это не идеальное решение проблемы, но патчи для Windows, Linux и macOS используют именно этот подход.
Как оказалось, исправляющий патч для ОС Windows (KB4056892) приводит к сбоям в работе систем на базе AMD, проявляется это тем, что система не загружается, просто отображается логотип Windows без анимации. После несколько неудачных попыток загрузки система откатывает патч и отображает ошибку 0x800f0845. Инженеры Microsoft пока не прокомментировали ситуацию.
Так что же из себя представляют уязвимости Spectre и Meltdown?
Для специалистов эта проблема оборудования известна давно, она «втихую» эксплуатировалась и все были довольны…
По какой то неизвестной причине о ней было решено раздуть шумиху, причем дилетантским способом, те кто выпускал официальные пресс-релизы (https://spectreattack.com/spectre.pdf и https://meltdownattack.com/meltdown.pdf) явно плохо представляли как все это работает и где проблема.
А поставщики исходной информации не удосужились подробно объяснить проблему, видимо передали работающий эксплоит и краткое описание для дилетантов…
Итак, на схеме ниже уязвимость в аппаратуре выделена красным кружком
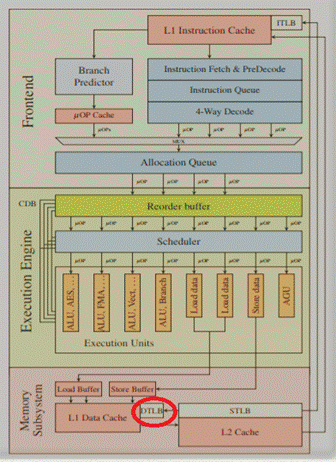
Проблема в блоке TLB, который используется в пейджинговой адресации оперативной памяти. Он является ассоциативным буфером хранящим пары значений виртуальный-физический адрес используемой приложением в оперативной памяти.
Блок TLB нужен для того чтобы сократить время обращения к ОП за счет исключения процедуры трансляции адресов памяти. Такая трансляция производится единственный раз для всей страницы (размером как раз 4К в случае современных ОС). Все остальные обращения программы к памяти в этой странице уже происходят форсированно, с использованием сохраненного значения в этом буфере. Эти блоки есть во всех современных процессорах, собственно из-за этого все они и подвержены уязвимостям называемым теперь Spectre и Meltdown.
И кстати, спекулятивное выполнение команд не единственная возможность эксплуатации этих уязвимостей, можно задействовать механизм форвардной загрузки данных из ОП.
Блок TLB не имеет программного (микропрограммного) управления, как обычный кеш. Из него невозможно удалить запись, либо принудительно внести/модифицировать какую либо запись.
В сухом остатке получается, что все произведенные трансляции адресов сохраняются в этом ассоциативном буфере, в этом и заключается аппаратная уязвимость.
Соответственно произведенная спекулятивно операция тоже оставит в блоке TLB cлед в виде записи, нужно только эту запись обнаружить и иденфицировать. А это уже «дело техники», технология давно известна и применяется, она называется «Исследование состояния аппаратуры методом временного прозвона». Не ищите этого названия в Интернете, метод был известен в очень узких кругах совершенно не публичных специалистов.
Только теперь с ним будут знакомы все.
Единственная возможность программного воздействия на блок TLB - это полный сброс всех его значений (если несколько упростить для понимания). Все патчи уязвимостей Spectre и Meltdown предложенные производителями ПО это и делают, перезагружая в обработчике исключения GP регистр CR3.
После сброса TLB процессору приходится заново выполнять трансляции всех используемых страниц виртуальной памяти, это и снижает производительность системы.
Так как все это эксплуатируется в реальности?
Первым делом нужно в программе создать буфер размером 2 мегабайта, причем в этот буфер нельзя писать/читать до проведения атаки и он должен располагаться на границе 4К блока. Этот размер принципиален, в буфере должны разместиться ровно 256 страниц по 4К (специфика пейджинговой адресации).
Затем выполняются команды типа:
Xor eax, eax; еах обнуляется регистр для правильной адресации
Lea ebx, Буфер размером 2М; евх принимает значение адреса буфера 2М
Mov al, [адрес ядра ОС]; аl читается значение их ядра ОС, байт!!!
Shl eax, 12; принятый байт становится адресом 4К страницы
Mov al, [ebx+eax]; чтение из конкретной страницы буфера 2М
В программе после команды Mov al, [адрес ядра ОС]; произойдет прерывание и значение регистра al не изменится (останется нулевым).
А вот в буфере TLB из-за форвардного запроса выполнения операции произойдет запоминание вычисленого соответствия виртуального адреса и физического адреса [ebx+eax].
Сбросить эту конкретную запись, как это делается в обычном Кеше, в блоке TLB невозможно и она останется.
Соответственно если мы узнаем адрес страницы размером 4К в буфере размером 2М, запомненный в блоке TLB, то мы узнаем и значение прочитанное из ядра ОС в регистр al.
Это уже дело техники, «прозвоним» блок TLB. Для этого нужно по одному разу прочитать все его страницы по 4К, их ровно 256, выполним 256 операций чтения (одну на каждый 4К блок). При этом будем измерять время выполнения операции чтения. Та страница, которая будет читаться быстрее остальных, и будет иметь номер в буфере размером 2М соответствующий прочитанному значению байта из ядра ОС.
Это произойдет потому, что в буфере TLB для этой страницы уже вычислено соответствие между виртуальным и физическим адресом, а для всех остальных страниц этой операции выполнено еще не было.
В «прозвоне» конечно не все так просто, там много нюансов, но это вполне возможно. Вот собственно и все.
Часть информации позаимствована из данной статьи.