Наверное многие из вас сталкивались с такой проблемой, когда есть отсканированный документ (в виде картинки), но вам нужно этот самый документ получить в редактируемом виде.

Что тут такого, спросите вы, просто необходимо распознать текст и все. Ок, текст вы распознаете без проблем, но что если в документе есть таблицы и картинки? Ведь, во многих программах, таблицы игнорируются и вы на руки получаете просто кучу текста, который вам совсем не сдался.
Конечно, можно потратить время, чтобы самому создать таблицы и потом просто скопировать текст, но зачем танцевать с бубном, когда есть хорошее, готовое решение.
Я это к тому, что сегодня я как-раз столкнулся с необходимостью точно распознать картинку (скан документа) в формат docx и после долгого поиска наткнулся на замечательный сервис https://convertio.co/ru/ocr/
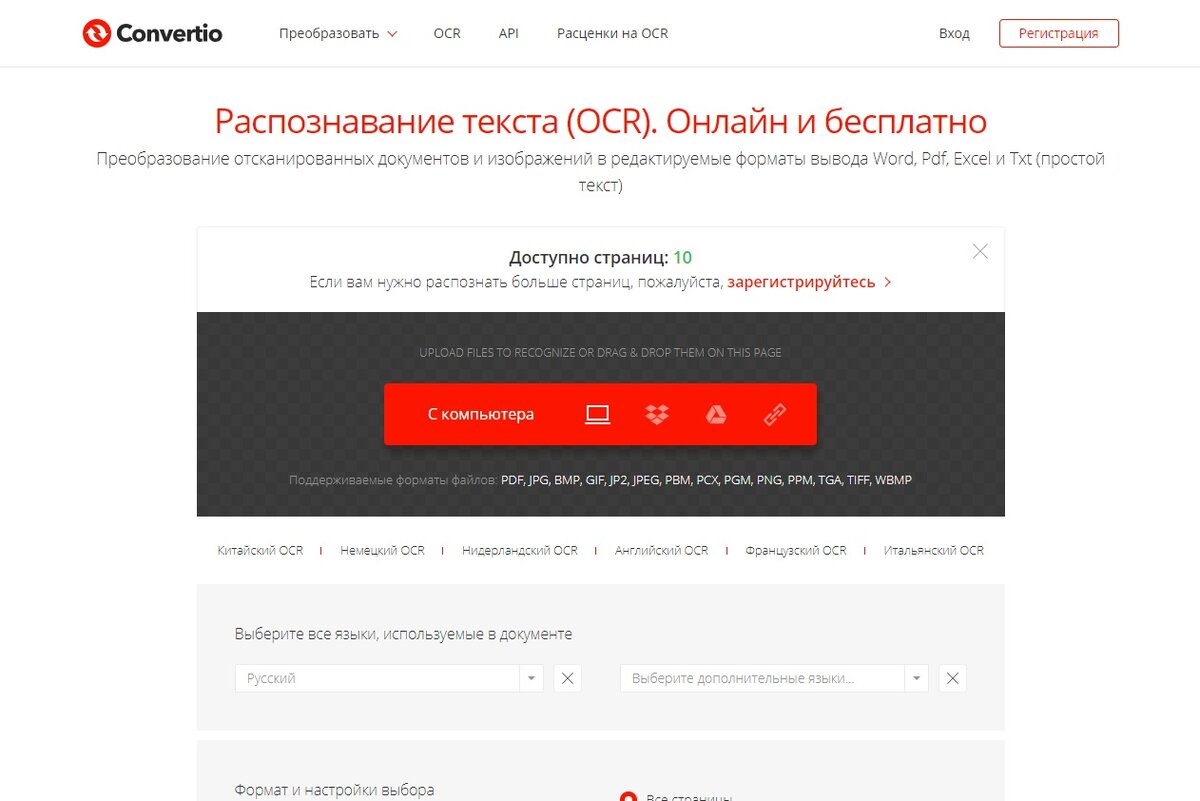
Нет это не реклама, просто сервис действительно очень меня выручил. Просто загружаете картинку в форму, выбираете языки, которые присутствуют на картинке и нажимаете Распознать. Спустя некоторое время получаете на руки готовый к редактированию документ.
Конечно, присутствуют ограничение на 10 страниц в день (способы обойти ограничение есть, но не буду об этом сейчас), но пока не могу представить ситуацию, когда 10 страниц не хватит.
Нужно также добавить, что документ редактируется очень легко, не возникает каких-либо проблем с форматированием текста или таблиц, все четко.
В общем, рекомендую данный сервис если вам нужно срочно рапознать документ и времени не особо много - реально выручит.
Если же я слоупок и есть рабочая программа, которая с такой же точностью распознает отсканированные документы, то дайте мне знать.