Продолжаем цикл статей на тему автоматизации разработки рекламных кампаний для интернет-магазина: составляем заголовки!
Темы статей:
В последней статье мы рассчитали ставки для всех слов, в этой будем создавать заголовки.
Когда у нас 11 000 объявлений, то разработка заголовков вручную может потребовать неоправданно много ресурсов, поэтому заголовки составляем из мета-тегов Title или H1 URL, на которые ссылаются ключевые слова.
Итак, что у нас есть? URL страниц, с которых мы можем спарсить мета-теги и из них составить заголовки, а для высокочастотных слов (в точном соответствии) пишем заголовки руками.
Здесь есть 3 варианта:
Выгрузить Titles по URL из Google Analytics - охват URL будет 90%
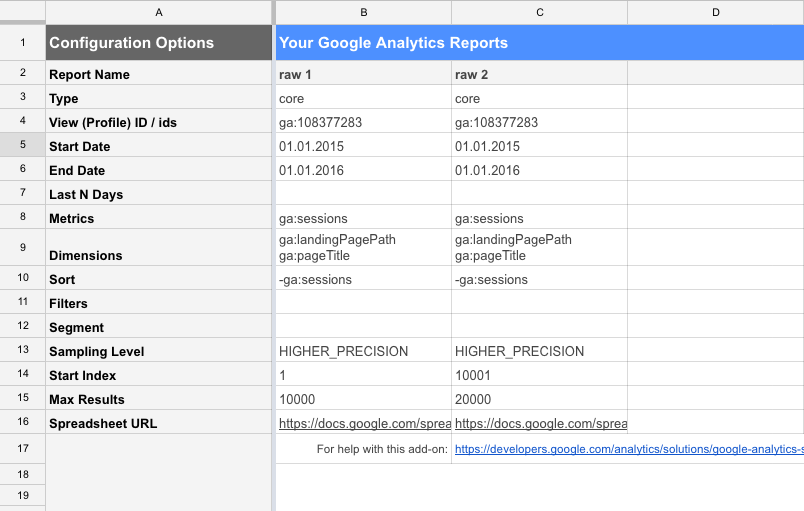
В предыдущих частях мы уже использовали API GA, поэтому показываю только запрос. Вы могли заметить, что в поле Start index и Max results у нас стоят значения 0-10000 и 10001-20000. Суть в том, что GA позволяет выгрузить только 10000 строк на один запрос и мы как бы делаем два запроса, но указываем, что в первому нужно с 1-ой по 10000-ую строку, а во втором точно такой-же запрос, но строки с 10001 по 20000.
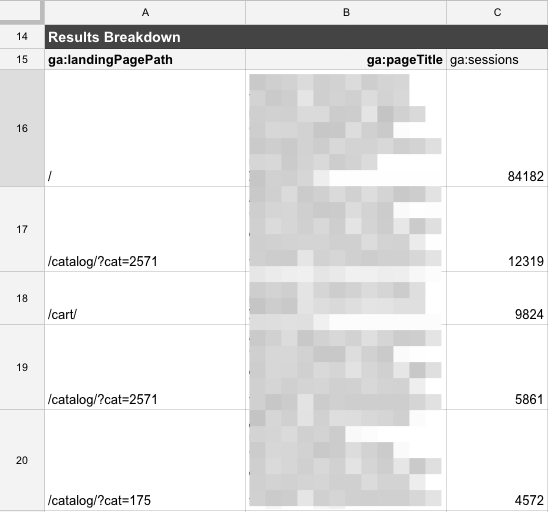
На выходе имеем URL и Title, которые сможем подставить вместо заголовков.
Написать скрипт запроса к базе данных
Попросить клиента сделать скрипт, где на входе URL, а на выходе теги - самый оптимальный вариант! Вы можете попросить клиента сделать скрипт на секретном URL адресе.
Использовать парсеры, например Datacol. Это вариант в лоб, демонстрирую.
Создаем кампанию
Вставляем URL, которые нужно парсить
Выбираем пункт Все, это значит, что без лишних заморочек :)
Добавляем поле H1
Нажимаем селектор
Загружается одна из наших ссылок и нам нужно тыкнуть на текст, который нужно сохранить, он выделятся красным. Потом нажимаем «Сохранить» в левом верхнем углу.
Готово! Появится новая кампания - запускаем ее!
Внизу сразу появятся результаты, которые по завершении сохранятся в папку «Мои документы»
Таким же образом можно парсить titles, которые мы так и не спарсили, цены, описание, характеристики и так далее. А далее из этих строк можно генерировать рекламные кампании и автоматически обновлять, но об это в другой статье.
В нашем кейсе у нас есть скрипт на стороне заказчика, поэтому проблем по-убавится.
Теперь нужно придать заголовка вид, уместить их в 33 символа, использовать добавку к заголовку 23 символа, восклицательные знаки и так далее.
У нас для этого есть скрипт в питоне. Итак на входе мы имеем:
Применяем код
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import pandas as pd
import re
df = pd.read_excel('Headlines.xlsx', header=0)
# очищаем
df.dropna(inplace=True)
df.reset_index(drop=True, inplace=True)
# считаем символы в колонке с текстом
df.loc[:,'Len'] = df.loc[:,'Title'].str.len()
# очищаем от ненужных символов с помощью регулярного выражения
df.loc[:,'Title'] = df.loc[:,'Title'].str.replace(r'\/|\(|\)', '')
# создаем колонки для заголовков и первой строки
df.loc[:,'headline'] = ''
df.loc[:,'text1'] = ''
# экспортируем данные из исходного текста в колонки заголовка и первой строки
for i in range(len(df)):
if df.loc[i,'Len'] > 33:
for word in df.loc[i,'Title'].split(' '):
if (len(df.loc[i,'headline']) + len(word) + 1) <= 33:
df.loc[i,'headline'] += word + ' '
else:
if (len(df.loc[i,'text1']) + len(word) + 1) <= 23:
df.loc[i,'text1'] += word + ' '
else:
df.loc[i,'text1'] = df.loc[i,'text1'][0].upper() + df.loc[i,'text1'][1:]
df.loc[i,'text1'] = df.loc[i,'text1'][0:(len(df.loc[i,'text1'])-1)] + '!'
break
else:
if len(df.loc[i,'text1']) > 0:
df.loc[i,'text1'] = df.loc[i,'text1'][0].upper() + df.loc[i,'text1'][1:]
df.loc[i,'text1'] = df.loc[i,'text1'][0:(len(df.loc[i,'text1'])-1)] + '!'
else:
df.loc[i,'headline'] = df.loc[i,'Title']
continue
# пишем добавки
d = [u' в Москве', u' в МСК', u'!']
# скрипт добавления
for i in range(len(df)):
if df.loc[i,'text1'] == '' and len(df.loc[i,'headline']) <33:
for add in d:
if len(add) <= (33 - len(df.loc[i,'headline'])):
df.loc[i,'headline'] += add
break
else:
continue
# добавляем текст в пустые добавки
for i in range(len(df)):
if df.loc[i,'text1'] == '':
df.loc[i,'text1'] = u'В наличии!'
df.to_excel('headlines.xlsx')
И получаем
Так же есть возможность применить применить подобный подход в Excel
Прикрепляю ссылку на файл
Теперь копируем заголовки в главный Excel и подтягиваем в основную таблицу с помощью VLOOKUP
Все!
Пишите вопросы в комментариях, какие темы было бы интересно раскрыть подробнее? Если у вас есть идеи или советы, то делитесь!