Статья продолжает цикл по криптографии, и это наше четвёртое занятие. После изучения шифров простой замены, N-граммных шифров и шифров многоалфавитной замены пришло время рассмотреть пропорциональный шифр. Этот способ шифрования не поддавался дешифровке очень и очень долго, и даже сегодня при наличии мощных вычислительных устройств дешифровать скрытые пропорциональным шифром секреты очень и очень сложно, если нет никаких подсказок.
Если вы тщательно выполняли все упражнения, даваемые в предыдущих статьях цикла по криптографии, то с шифром пропорциональной замены вы уже познакомились в книге «Криптографические приключения. Таинственные шифры и математические задачи». Здесь же давайте более подробно рассмотрим технические аспекты этой системы шифрования и обсудим, почему она настолько более стойкая к взлому, чем все предыдущие криптографические методы, которые мы уже изучили.
Перед этим же немного погрузимся в теорию криптографии и продолжим строить классификацию шифров, начатую в прошлых статьях цикла. С изучением каждой новой криптографической системы мы будем достраивать классификатор, и к концу цикла у вас будет полноценное понимание того, сколько и какие системы шифрования вообще существуют. Так что давайте сегодня поднимемся на уровень выше и рассмотрим два новых термина:
1. Поточный шифр — это такой шифр, в котором каждый символ открытого текста зашифровывается в зависимости от используемого ключа и позиции символа в открытом тексте.
2. Блочный шифр — это шифр, в котором функция шифрования применяется к блокам открытого текста фиксированной длины, а результат зависит от ключа и результата для предыдущего блока.
При помощи двух данных определений дополним классификацию систем шифрования, диаграмма которой была дана в предыдущей статье:
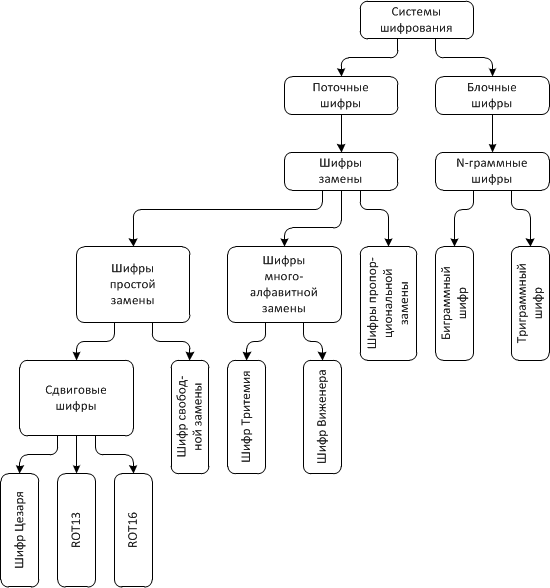
На диаграмме показаны те системы шифрования, с которыми мы уже познакомились. В процессе развития этого цикла статей эта диаграмма будет дополняться и развиваться.
Метод шифрования
Теперь же перейдём к рассмотрению шифра пропорциональной замены. Если вы вспомните три предыдущих шифра, которые мы уже изучили, то есть шифры одноалфавитной и многоалфавитной замены, а также N-граммные шифры, то мы увидим, что все они подвержены одной и той же атаке — частотному анализу. А сам частотный анализ основан на том, что частота проявления разных символов шифротекста в той или иной мере соответствует частотам символов открытого текста, а потому на основе этого можно делать гипотезы.
А что если атаку криптографа направить на эту особенность текстов на естественном языке? Ведь чем меньше у крипотаналитика зацепок, тем сложнее ему дешифровать скрытый текст. А различающиеся частоты символов шифрограммы — это очень сильная зацепка. Каким образом можно нивелировать её? Ответ напрашивается сам собой: «Постараться сделать частоты всех символов шифрограммы примерно одинаковыми».
Шифр многоалфавитной замены в случае, если в разных алфавитах используются одинаковые символы (например, сдвиговый шифр, величина сдвига в котором определяется соответствующей буквой ключевого слова), частично решают эту задачу. Чем длиннее ключ, при том, что в самом ключе не повторяются буквы или повторяются слабо, тем более плоской становится гистограмма распределения частот в шифрограмме. Но она всё равно неравномерна, и на такой неравномерности можно сделать определённые выводы и получить кое-какие зацепки в процессе дешифровки. Поэтому было бы более интересным сделать такой шифр, чтобы в нём гистограмма частот символов шифротекста была бы ровной — то есть для всех символов значение частоты было бы примерно одинаковым.
Как можно было бы это сделать? Для ответа на этот вопрос давайте рассмотрим более простой пример. Пусть в открытом тексте используются три разных символа, при этом у них такие частоты использования: А — 50 %, Б — 30 % и В — 20 %. Всего у нас 100 %, и доли каждого символа можно рассмотреть как 5/10, 3/10 и 2/10. Если для этих трёх символов сделать одноалфавитную замену, то как мы уже поняли, частоты сохранятся. А что если каждому символу поставить в соответствие столько новых символов для шифрования, сколько соответствует доле этого символа в общем числе. В нашем примере всего 10 долей, так что символу А надо сопоставить 5 символов, символу Б — 3 символа и символу В — 2 символа. Что-то типа такого:
· А = 0, 1, 2, 3, 4
· Б = 5, 6, 7
· В = 8, 9
И если произвести зашифровку при помощи такого соответствия, стараясь в шифрограмме использовать символы случайно и равномерно, то частоты символов от 0 до 9 будут примерно одинаковыми. Другими словами, если у нас есть необходимость зашифровать открытый текст:
А А Б А В В А А Б Б А АА Б В Б А В Б А,
то в результате можно сделать такую шифрограмму:
4 0 6 3 9 8 2 1 5 7 2 3 4 6 9 7 0 8 5 1,
и в этой шифрограмме все символы от 0 до 9 встречаются ровно по два раза, что полностью выровняло их частоты. Вместе с тем при наличии ключа расшифровка однозначна, а вот провести атаку частотным анализов просто невозможно.
Итак, суть шифра пропорциональной замены в том, чтобы сделать частоты всех символов, встречающихся в шифрограммах, примерно одинаковыми. Если брать тексты на естественном языке, то очевидно, что абсолютно одинаковыми такие частоты можно сделать лишь в исключительно редких случаях. Но если частоты всех символов будут отличаться друг от друга в пределах 1 % или того меньше, работа у криптоаналитика будет практически невыполнимой.
Давайте снова рассмотрим таблицу частот для букв русского языка (она приведена в первой статье цикла):
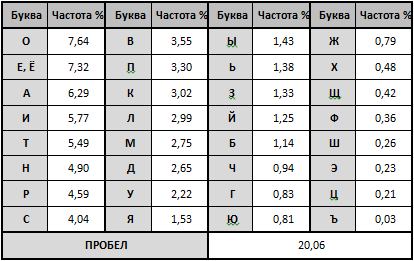
Собственно, по этой таблице понятно, сколько закрытых символов необходимо сопоставить с каждой буквой. Пусть всего требуется иметь 100 символов закрытого текста. Тогда пробелу будет поставлено 20 символов, букве «О» — 8 символов, букве «Е» — 7 символов и т. д. до букв Ы, Ь, …, Ъ, которым надо сопоставить по 1 символу. Всего получится 105 символов, и в этом случае для выравнивания до 100 необходимо вычесть по 1 символу из числа тех букв, у которых больше всего символов. То есть пробел получает 19 символов, буква «О» — 7 символов и т. д.
Другими словами, при общем количестве символов N для получения количества закрытых символов для буквы с частотой необходимо воспользоваться формулой:
Nf = [N * f].
После выполнения всех округлений если общая сумма количеств для всех букв меньше числа , то по одному символу надо добавлять к буквам, имеющим самые высокие частоты. Если же сумма количеств всех букв больше числа N, то, соответственно, надо удалить необходимое количество символов.
Из этого объяснения видно, что чем больше значение N, тем больше частоты букв соответствуют количеству закрытых символов. И общая ошибка округления тем меньше. И обычно в качестве символов закрытого текста используются числа от 0 до N – 1. Но, само собой разумеется, перед назначением соответствий таких чисел буквам, сами числа надо хорошенько перемешать.
Метод атаки
Дешифровка текста, сокрытого шифром пропорциональной замены, — дело очень непростое, долгое и затратное. Как должно быть уже понятно, частотный анализ к таким шифрограммам применить практически невозможно. Даже если накопить огромный массив шифрованных текстов, то дело может не сдвинуться с мёртвой точки, так как частоты символов в шифрограммах никак не будут соответствовать частотам символов открытого текста.
Обычно используется два метода дешифровки:
1. Обнаружение подсказок.
2. Подбор ключа шифрования.
Само собой разумеется, что чем больше подсказок обнаружит криптоаналитик, тем проще ему будет дешифровать шифр пропорциональной замены. Это относится практически к любому типу шифров. Но добыть такие подсказки обычно непросто, так что такой метод дешифровки всегда используется в качестве вспомогательного. Остаётся подбор. Однако даже если шифр пропорциональной замены содержит 100 символов, пропорционально распределённых по частотам букв русского языка, то полный перебор всех вариантов займёт время больше, чем время жизни многих вселенныхдаже если выполнять это на всех имеющихся на Земле суперкомпьютерах. Простой перебор вариантов тут никак не поможет, необходимо что-то другое.
Сегодня я хочу познакомить тебя с одним очень важным методом подбора. Он основан на процессах, которые наблюдаются в природе. И этот метод сегодня используется в таких областях, как искусственный интеллект. Это метод оптимизации, известный как «генетический алгоритм». Генетические алгоритмы входят в состав более широкого класса алгоритмов, называемых эволюционными. Эти алгоритмы были разработаны по аналогии с процессом естественного отбора, в соответствии с которым эволюционирует жизнь на нашей планете.
Генетический алгоритм — это метод поиска при помощи случайного подбора по аналогии, как уже сказано, с естественным отбором живых организмов в природе. Генетический алгоритм позволяет найти оптимальное решение задачи с требуемой точностью в тех случаях, когда существует возможность представить входные данные в виде вектора значений, а критерий останова выразить в виде предиката, возвращающего истину на тех входных параметрах, которые достаточны для решения.Предикат зависит от так называемой фитнесс-функции, которая возвращает степень соответствия входного вектора целевому значению. Ну и, само собой разумеется, искомое значение должно существовать, иначе алгоритм никогда не остановится.
При помощи генетического алгоритма можно отобрать подходящее значение в пространстве поиска. При этом значения, среди которых отбирается подходящее, должны быть представимы в виде вектора или списка:
X = <xi>, i=1,N, xi in Di,
где Di — область определения значения xi. Это может быть интервал целых или действительных чисел, классификатор значений, множество и т. д.
Генетический алгоритм состоит из следующих шагов:
1. Генерация начальной популяции. Это значит, что необходимо подготовить некоторое количество «начальных» значений в пространстве поиска, с которых алгоритм начнёт свою работу. Начать можно с произвольных значений, но если такие значения будут как можно более близки к целевому, то алгоритм отработает намного быстрее.
2. Запуск цикличного процесса рождения новых поколений и отбора. Фактически, это и есть сам генетический алгоритм, который раз за разом запускает процесс порождения новых поколений, изучения новых особей и отбора наиболее интересных. Этот процесс состоит из следующих шагов и операций:
· Скрещивание (или перекрёст, англ. crossingover) — это операция, при которой берутся две особи текущего поколения, и их генотип перемешивается друг с другом. Чаще всего два генотипа разрезаются в одинаковом случайном месте, и после этого вторые части переставляются друг с другом. Так получаются два новых потомка. Фактически, скрещивание делается каждой особи с каждой, да ещё и по нескольку раз, чтобы разрезание генотипа происходило в разных местах. Так получается набор особей следующего поколения.
· Мутация — это операция по внесению случайных изменений в генотип потомства. С установленной частотой в каждый новый генотип после скрещивания вносятся случайные изменения. Если частота мутаций высокая, то наблюдается «подвижность» поиска, если же частота мутаций слишком низкая, то часто это приводит к «залипанию» алгоритма в локальном экстремуме, из которого он не может выбраться и, соответственно, остановиться. Величину частоты мутаций часто подбирают при помощи экспериментов для каждой конкретной задачи.
· Отбор — это операция по выбору наиболее приспособленных особей. Обычно выбирается какая-то доля (например, 10 %) тех особей нового поколения, для которых фитнесс-функция возвращает наилучшие результаты. Иногда в отобранное множество особей нового поколения добавляются наименее приспособленные особи, для которых фитнесс-функция возвращает наихудшие результаты. Это делается для получения генетического разнообразия и является инструментов борьбы с залипанием в локальных экстремумах. Также иногда в состав нового поколения включаются некоторые представители предыдущего поколения, которые в данном случае называются «элитой». Вообще, операция отбора также подбирается на основе экспериментов для каждой конкретной задачи.
3. Возвращение результатов, которые привели к остановке цикла.Завершение алгоритма происходит тогда, когда фитнесс-функция для какой-либо особи находится в окрестности целевого значения с заданной точностью. Собственно, предикат проверки условия для остановки алгоритма проверяет для каждой особи значение фитнесс-функции, и если абсолютное значение разницы между ним и целевым значением меньше заданной точности, то предикат возвращает истину, и алгоритм останавливается. Необходимая точность является входным параметром алгоритма.
Схематически генетический алгоритм может быть изображён при помощи следующей диаграммы:
Теперь предлагаю подумать, как эту общую схему поиска решений можно применить к поставленной ранее задачи взлома шифра пропорциональной замены. Рекомендую читателю сейчас приостановить чтение и попытаться самостоятельно придумать конкретные решения для использования техники генетических алгоритмов для атаки на изучаемый шифр. После обдумывания можно продолжить чтение и сравнить с тем, как это можно сделать.
Что ж, продолжим… Давайте посмотрим, как будут выглядеть особи для дешифровки шифра пропорциональной замены. Фактически, для этого требуется знать только количество различных символов в шифрограмме и количество символов в открытом тексте. Частоты символов открытого текста известны. Соответственно, хромосомой для генетического алгоритма будет являться список чисел от 1 до количества различных символов в шифрограмме, перемешанных в случайном порядке.
Например, пусть для русского языка создан шифр пропорциональной замены, в котором используется 100 символов, из которых 20 пробелов, 8 букв «О» и т. д., как это описано в предыдущем разделе. Все символы представляют собой числа от 1 до 100. Фактически, если сначала расположить все символы для пробела, потом все символы для буквы «А», потом все символы для буквы «Б» и т. д. до конца алфавита, то как раз и получится та идеальная особь, которую надо найти. То есть это и будет хромосома — список числе от 1 до 100, перемешанных в некотором порядке, как раз для шифрограммы неслучайном.
Как в таком случае выглядит фитнесс-функция? Если расставить числа в правильном порядке, а потом рассчитать частоты символов шифрограммы, то в результате получатся частоты, необычайно близкие к частотам букв в русском языке. Чем дальше особь от правильной расстановки, тем дальше будут располагаться частоты символов в шифрограмме. Так что для получения значения фитнесс-функции необходимо подсчитать частоты символом в шифрограмме для заданной перестановки, а потом определить расстояние от обычного распределения частот в русском языке. Такое расстояние можно считать по формуле Евклида.
Соответственно, для остановки алгоритма необходимо, чтобы для найденной особи расстояние от эталонной частотности было меньше, чем некоторая установленная точность.
Здесь есть тонкий момент. Точность, являясь входным параметром генетического алгоритма, должна подбираться таким образом, чтобы алгоритм остановился в приемлемое время. Остановка может произойти и тогда, когда найдена особь, не полностью соответствующая эталонной частотности — это не страшно, если для некоторых символов шифрограммы произойдёт путаница, то есть близкие по частоте буквы будут переставлены местами (например, буквы «Х» и «Щ» будут переставлены на места друг друга по всему дешифрованному тексту). Это всё равно позволит прочитать зашифрованное послание.
Теперь необходимо рассмотреть три операции генетического алгоритма в применении к поставленной задаче:
1. Кроссинговер. В кроссинговере участвуют две особи. У первой особи берутся случайное количество первых чисел, при этом такое случайное количество должно быть от 1 до 99. Эти первые числа первой особи становятся первыми числами новой особи-потомка. Оставшиеся числа получаются из списка чисел второй особи — из него просто удаляются отобранные числа, где бы они ни стояли в списке, после чего оставшийся список добавляется в конец списка особи-потомка. Это можно пояснить при помощи следующей диаграммы (на примере 10 чисел):
Особь 1: 9 3 7 8 2 0 1 5 4 6
Особь 2: 783 6 0 9 2 1 4 5
Особь-потомок: 9 3 7 8 6 0 2 1 4 5
2. Мутация. В качестве мутации производится следующая операция. В составе гена особи выбираются два числа, которые меняются местами. Само собой разумеется, что операция мутации применяется не к каждой особи потомку, а только в соответствии с частотой мутаций, значение которой является входным параметром в генетический алгоритм и должно подбираться на основе экспериментов. Например, для полученной на предыдущем шаге особи-потомка мутация может выглядеть так:
Особь-потомок: 9 3 7 86 0 2 1 4 5
Выбор двух чисел: 9 3 7 8 6 0 2 1 4 5
Особь-потомок с мутацией: 9 3 7 1 6 0 2 8 4 5
3. Отбор. Операция отбора осуществляется следующим образом. Все особи-потомки сортируются в соответствии со значением фитнесс-функции, и на следующий круг эволюции проходят только 10 % особей, имеющих самые лучшие значения. Из предыдущего поколения остаётся лучшая особь, но также в состав нового поколения включается худшая особь из потомков. Всё это позволит сделать алгоритм более гибким так, чтобы он не зацикливался в локальных экстремумах. Число «10 %» взято произвольно, и, на самом деле, оно также должно подбираться в ходе экспериментов.
Такая конкретизация операций генетического алгоритма позволит, скорее всего, за приемлемое время найти решение.
Заключение
В принципе, генетический алгоритм рано или поздно может взломать шифрограмму пропорциональной замены. Чем больше объём шифрограммы, тем быстрее это может произойти, этот принцип выполняется и для этой схемы шифрования. Однако для шифрограмм малого объёма может потребоваться огромный объём вычислений, что снизит практическую ценность, так как время взлома будет слишком длительным и информация в шифрограмме к этому времени может устареть и потерять свою актуальность.
Но, вообще говоря, предложенная общая схема взлома шифра пропорциональной замены говорит о том, что при использовании генетических алгоритмов лучше всего подходит автоматизированный режим работы, то есть когда криптоаналитик изучает промежуточные результаты дешифровки и иногда вмешивается в процесс, чтобы повысить значимость отдельных особей. Такой режим требуется для того, чтобы человек распознавал в промежуточных результатах некие паттерны, напоминающие естественный язык, и в этом случае направлял алгоритм в их сторону. Впрочем, если скрестить генетический алгоритм с сопоставлением со словарём (хотя бы ограниченным — только наиболее часто встречающиеся буквосочетания и слова), то и эта задача может производиться автоматически.
Упражнения
В качестве домашнего задания и самостоятельных упражнений рекомендую выполнить следующее:
1. Прочитайте следующие художественные произведения:
· Чёрчхаус Роберт. Коды и шифры. Юлий Цезарь, «Энигма» и Интернет.
· Жельников Владимир. Криптография от папируса до компьютера.
2. Дешифруйте следующую шифрограмму, про которую известно, что она зашифрована шифром пропорциональной замены:
24 58 71 39 12 44 81 01 57 73 18 87 14 40 71 38 10 56 74 97 16 87 70 35 01 52 33 56 93 37 92 54 20 60 31 44 82 07 94 45 18 10 57 23 18 85 99 91 28 50 37 26 07 44 23 08 94 43 21 0017 86 26 47 82 10 83 76 18 51 17 62 18 98 12 50 29 08 68 30 89 75 17 74 78 98 06 66 15 76 76 30 79 42 57 80 05 93 41 92 53 04 64 52 17 65 99 17 54 95 39 23 47 32 71 82 49 19 84 1483 34 74 28 48 81 02 59 65 51 18 86 26 73 07 29 55 70 37 03 94 44 21 06 49 25 97 00 78 75 30 70 17 57 82 03 45 20 10 43 99 81 04 50 25 05 55 73 20 89 28 93 99 82 00 63 52 15 86 3642 35 45 82 07 94 46 23 04 58 22 17 85 91 28 49 41 28 06 42 33 69 03 86 42 19 09 94 46 21 12 63 52 17 58 44 22 06 87 99 70 77 66 17 14 66 40 56 30 43 82 05 43 77 42 08 42 34 69 9940 26 09 62 25 91 99 36 07 43 25 74 03 50 25 13 74 25 49 26 28 00 83 48 33 84 09 86 45 16 01 69 72 88 86 24 59 16 24 06 58 72 20 61 15 02 86 28 45 59 79 52 46 16 84 13 56 45 34 4382 40 06 94 43 19 05 67 97 70 23 48 38 51 21 59 34 50 40 28 10 83 31 65 40 93 38 11 24 87 20 02 36 06 90 52 31 50 39 06 61 74 25 57 46 24 01 56 20 03 61 55 29 74 36 11 63 53 24 7581 76 78 91 36 73 36 01 67 72 88 86 24 60 81 73 37 13 57 70 18 62 30 74 38 02 60 05 69 17 49 95 26 13 60 55 27 90 04 45 24 90 12 68 45 22 11 58 74 19 87 09 57 19 85 51 35 44 82 02 67 71 88 86 24 60 81 27 09 58 72 23 61 35 13 39 83 06 61 57 27 90 07 83 31 87 33 76 20 69 03 89 76 79 42 06 65 52 39 98 83 12 75 27 53 83 30 84
Это практически невозможная задача, но есть несколько важных подсказок:
· В шифрограмме используются числа от 00 до 99.
· Если расположить буквы русского языка в порядке убывания их частот (от пробела до буквы «Ъ»), то соответствующие им числа из шифрограммы идут по порядку от 00 до 99.
· В этом ряду буква «Ё» имеет одно число и стоит сразу после буквы «У».
· Три последних числа (97, 98, 99) являются пустышками.
· Весь вопрос только в правильном подсчёте процентов и пропорций. Эти пропорции немного отличаются от тех, что были использованы в таблице частот в этой статье, но не намного.
Этих подсказок должно хватить. Дерзайте.
3. На своём любимом языке программирования напишите программу для автоматизированной дешифровки шифрограмм, зашифрованных пропорциональным шифром.
4. Также напишите программу для шифрования текстов при помощи пропорционального шифра, причём в качестве входных данных должны указываться только входной алфавит с частотами символов, количество символов закрытого текста и текст для шифрования. На выходе должны отдаваться шифроалфавит и шифрограмма.