Системный дизайн — это итеративный процесс поиска оптимального баланса. Эти 10 вопросов — не просто контрольный список, а структурированный образ мышления. Они помогут вам систематически подходить к проектированию, начиная с требований и заканчивая обеспечением надежности и безопасности. Используйте их как основу, чтобы строить системы, готовые к будущему. Знание есть, но стресс мешает?
Бесплатное сообщество для прокачки карьеры в IT Подпишись на https://t.me/IT_Interview_Partner_Bot
Подпишись на https://t.me/LyakhovEugene
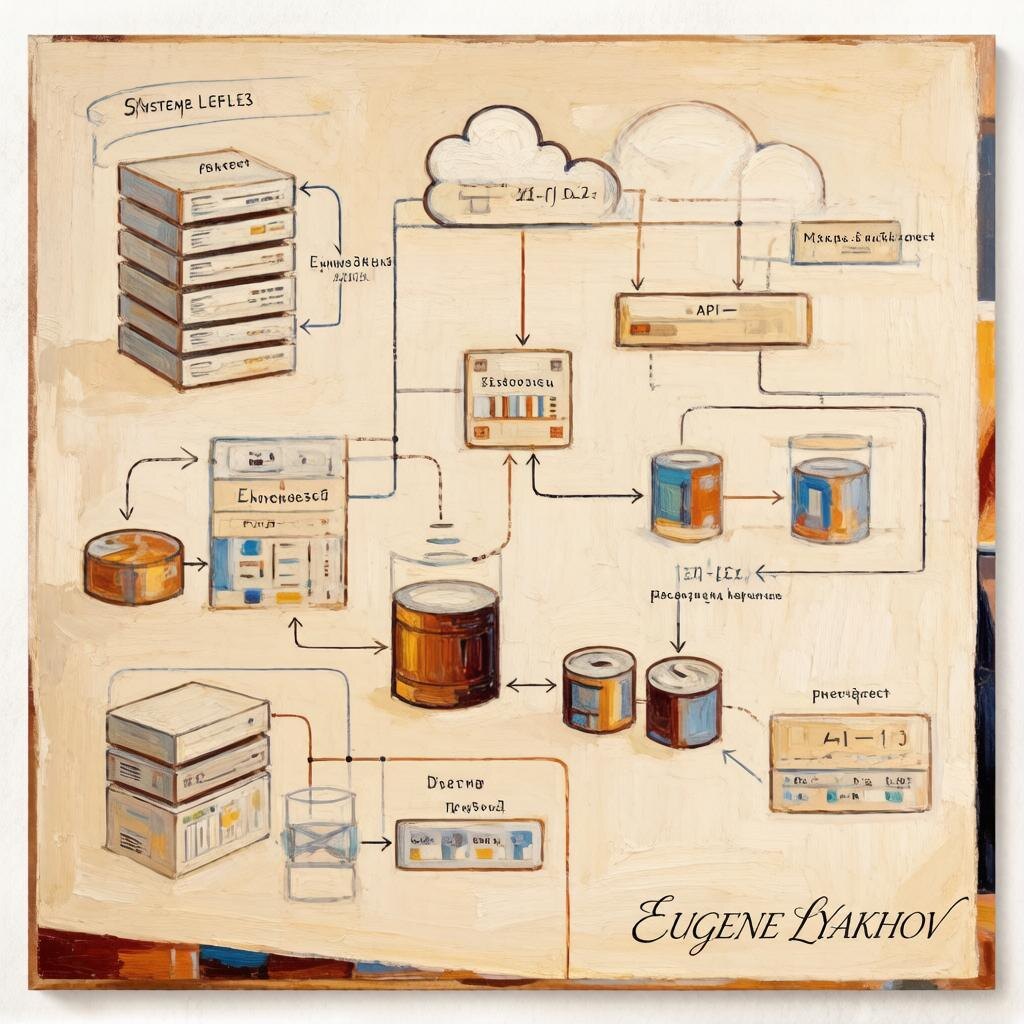
🏛️ 1. Каковы функциональные и нефункциональные требования?
- Что это: Первый и важнейший шаг — четко определить, что должна делать система (функциональные требования) и как она должна это делать (нефункциональные требования).
- Функциональные требования: Это конкретные возможности системы. Примеры: регистрация пользователя, создание поста, генерация короткой ссылки, загрузка файла. Важно не просто перечислить их, а уточнить детали (входные/выходные данные) и учесть граничные случаи (например, неверный ввод).
- Нефункциональные требования: Это "качества" системы: производительность, масштабируемость, надежность, безопасность и т. д.. Вы должны определить конкретные, измеримые метрики, например:
Задержка (Latency): Время ответа системы (например, < 200 мс).
Пропускная способность (Throughput): Сколько запросов система обрабатывает в секунду (например, 10K req/s).
Доступность (Availability): Процент времени, когда система работает (например, 99.9% или 99.99%). - Почему это важно: Без четких требований вы рискуете спроектировать систему, которая не соответствует бизнес-целям или потребностям пользователей. Это фундамент для всех последующих решений.
📈 2. Какова оценка нагрузки и объема данных?
- Что это: Оценка будущей нагрузки на систему на основе предположений о количестве пользователей, паттернах запросов и объемах данных.
- Как оценивать:
Трафик (QPS): Подсчитайте количество запросов в секунду. Например, 1 млн пользователей в день, совершающих 10 действий, дают ~115 запросов в секунду (QPS).
Хранилище: Оцените требуемый объем памяти. Например, 1 млн пользователей с профилем по 1 КБ — это 1 ГБ данных.
Пропускная способность сети: Например, сайт новостей с 5 млн пользователей, просматривающих 5 страниц по 100 КБ, генерирует ~2.5 ТБ трафика в день. - Почему это важно: Оценка позволяет обосновать архитектурные решения и понять, где будут узкие места. Это критически важно для масштабируемости.
🗺️ 3. Какова высокоуровневая архитектура?
- Что это: Схематичное изображение основных компонентов системы и того, как они взаимодействуют друг с другом.
- Что входит: На высокоуровневой диаграмме обычно показывают клиентов (браузеры, мобильные приложения), балансировщики нагрузки (Load Balancers), серверы приложений (App Servers), кэши (Caches), базы данных (Databases), очереди сообщений (Message Queues) и CDN.
- Почему это важно: Это "карта" вашей системы. Она позволяет увидеть общую картину, обсудить архитектурные решения и выбрать правильные компоненты.
📡 4. Каким будет дизайн API?
- Что это: Определение контракта взаимодействия с системой — как внешние клиенты будут обмениваться с ней данными.
- Что нужно определить:
Метод: REST (GET, POST, PUT, DELETE) или GraphQL.
Эндпоинты (Endpoint): URL-адреса для доступа к ресурсам (например, /api/v1/users/{id}).
Форматы данных: Обычно JSON или XML.
Статус-коды: Для индикации успеха (200 OK), ошибки (400 Bad Request) или необходимости авторизации (401 Unauthorized). - Почему это важно: API — это фасад вашей системы. От его продуманности зависит простота использования и возможность будущих изменений без нарушения работы существующих клиентов.
🗄️ 5. Какую базу данных выбрать?
- Что это: Выбор между реляционными (SQL) и нереляционными (NoSQL) базами данных на основе требований к данным.
- Критерии выбора:
Структура данных: SQL подходит для строго структурированных данных и сложных запросов, NoSQL — для гибких, полуструктурированных или неструктурированных данных.
Масштабируемость: SQL традиционно масштабируется вертикально (увеличением мощности одной машины), NoSQL — горизонтально (добавлением новых узлов).
Консистентность (Consistency) vs. Доступность (Availability): SQL обычно обеспечивает сильную консистентность (ACID), в то время как NoSQL часто жертвует ею ради более высокой доступности и производительности (BASE). - Почему это важно: База данных — это сердце системы. Неправильный выбор может привести к проблемам с производительностью, масштабированием и надежностью в будущем. Часто используют комбинацию (например, SQL для пользователей и транзакций, NoSQL — для логов и событий).
🚀 6. Как обеспечить масштабируемость?
- Что это: Способность системы справляться с растущей нагрузкой (пользователи, запросы, данные) без потери производительности.
- Стратегии масштабирования:
Вертикальное (Vertical Scaling): Увеличение мощности существующего сервера (CPU, RAM). Просто, но имеет аппаратные ограничения и создает единую точку отказа.
Горизонтальное (Horizontal Scaling): Добавление большего количества серверов в пул. Более гибко, надежно и является стандартом для крупных систем.
Другие важные техники: Балансировка нагрузки (Load Balancing), шардирование (Sharding) баз данных, кэширование (Caching), проектирование "stateless" сервисов. - Почему это важно: Хорошо масштабируемая система может пережить внезапный взрыв популярности, в то время как плохо спроектированная — "упадет" под нагрузкой.
🛡️ 7. Как обеспечить отказоустойчивость и надежность?
- Что это: Способность системы продолжать работать при сбоях отдельных компонентов (серверов, баз данных, сетей) и быстро восстанавливаться.
- Ключевые методы:
Резервирование (Redundancy): Наличие нескольких копий критически важных компонентов (например, "горячий" резерв для базы данных или сервера).
Автоматическое переключение (Failover): Автоматическая замена отказавшего компонента на резервный.
Репликация (Replication): Создание и синхронизация копий данных на разных серверах.
Мониторинг и оповещение (Monitoring and Alerting): Системы, которые отслеживают здоровье сервисов и сигнализируют об отклонениях. - Почему это важно: Сбои неизбежны. Надежная система спроектирована так, чтобы минимизировать их влияние на пользователей и быстро восстанавливаться.
🔒 8. Каковы меры безопасности?
- Что это: Комплекс мер для защиты системы, данных и пользователей от несанкционированного доступа, атак и утечек.
- Ключевые области:
Аутентификация (Authentication) и Авторизация (Authorization): Проверка личности пользователя и предоставление ему прав на выполнение определенных действий (например, с помощью JWT, OAuth).
Шифрование (Encryption): Защита данных при передаче по сети (TLS/SSL) и в состоянии покоя (например, AES-256).
Защита от атак: Внедрение защиты от DDoS, SQL-инъекций, подбора паролей (Rate Limiting), использование Web Application Firewall (WAF). - Почему это важно: Безопасность нельзя "прикрутить" в конце. Она должна быть заложена в архитектуру с самого начала, чтобы защитить как бизнес, так и пользователей от огромных рисков.
🧪 9. Как тестировать и оптимизировать систему?
- Что это: Процесс проверки, что система соответствует требованиям, и поиска узких мест для улучшения производительности.
- Виды тестирования:
Нагрузочное тестирование (Load Testing): Проверка поведения системы под ожидаемой нагрузкой.
Тестирование производительности (Performance Testing): Оценка ключевых метрик (задержка, пропускная способность) в контролируемых условиях.
Стресс-тестирование (Stress Testing): Проверка системы за пределами нормальной нагрузки, чтобы выявить точку отказа. - Стратегии оптимизации: Кэширование, индексация баз данных, оптимизация запросов, асинхронная обработка через очереди сообщений.
- Почему это важно: Только через измерения и тестирование вы можете понять реальную производительность системы и обоснованно улучшать ее.
👁️ 10. Как обеспечить наблюдаемость (Observability)?
- Что это: Способность понимать внутреннее состояние системы по ее внешним проявлениям (логам, метрикам, трейсам).
- Три столпа наблюдаемости:
Метрики (Metrics): Числовые показатели (например, количество запросов в секунду, задержка p99, использование CPU/памяти). Часто визуализируются в дашбордах (Grafana).
Логи (Logs): Структурированные записи о конкретных событиях (например, "User 123 logged in from IP 1.2.3.4").
Трассировка (Tracing): Позволяет отследить путь одного запроса через все микросервисы и компоненты системы. - Почему это важно: Наблюдаемость позволяет инженерам активно находить и решать проблемы до того, как они повлияют на пользователей. Это незаменимый инструмент для поддержания надежности и производительности сложных распределенных систем.
💎 Заключение
Системный дизайн — это итеративный процесс поиска оптимального баланса. Эти 10 вопросов — не просто контрольный список, а структурированный образ мышления. Они помогут вам систематически подходить к проектированию, начиная с требований и заканчивая обеспечением надежности и безопасности. Используйте их как основу, чтобы строить системы, готовые к будущему.
Страховка на собеседовании
Знание есть, но стресс мешает?
Бесплатное сообщество для прокачки карьеры в IT
Подпишись на https://t.me/IT_Interview_Partner_Bot
Подпишись на https://t.me/LyakhovEugene