Искусственный интеллект уже давно перестал быть темой только для исследователей и крупных IT-компаний. Сегодня он встроен в повседневные сервисы, бизнес-процессы, инструменты разработки, поиск, обучение и клиентскую поддержку. Одним из самых заметных направлений в этой сфере стали большие языковые модели — LLM. Именно они лежат в основе современных чат-ассистентов, интеллектуальных помощников, генераторов текста и многих систем автоматизации.
LLM способны работать с естественным языком почти так, как это делает человек: понимать вопрос, учитывать контекст, формулировать ответ, пересказывать, переводить, анализировать, структурировать и даже помогать с кодом. Но за внешней простотой скрывается довольно сложная технология, которая уже серьезно влияет на то, как устроены современные цифровые продукты.
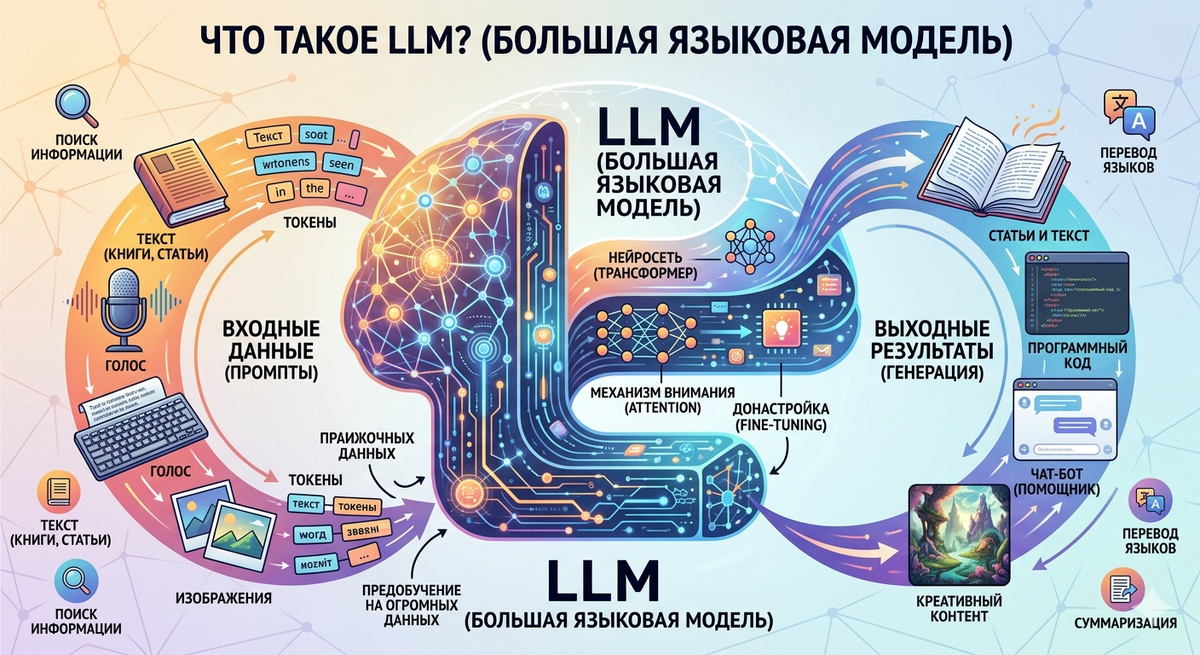
Что такое LLM
LLM — это large language model, то есть большая языковая модель. Под этим термином понимают нейросетевую систему, обученную на огромных массивах текстов. Во время обучения такая модель выявляет статистические и смысловые закономерности языка, учится распознавать связи между словами, фразами и контекстом, а затем использует эти знания для генерации ответа.
Если говорить проще, языковая модель получает текст на вход, анализирует его и строит наиболее вероятное продолжение или наиболее уместный ответ. Но современные LLM — это уже не просто “угадывание следующего слова”. Они умеют удерживать контекст, менять стиль, следовать инструкции, извлекать главное из текста, сравнивать формулировки и подстраиваться под задачу.
Именно поэтому большие языковые модели применяются не только для общения в формате чата. Они используются для суммаризации документов, классификации данных, генерации кода, перевода, поиска информации, анализа отзывов, обработки обращений клиентов и десятков других сценариев.
На чем основана работа языковых моделей
Технологической базой современных LLM обычно служит архитектура трансформеров. Именно она позволила сделать качественный скачок в обработке языка и вывести нейросетевые системы на новый уровень. Трансформер анализирует текст не последовательно, слово за словом в простейшем смысле, а учитывает взаимосвязи между элементами фразы через механизм внимания — attention. Благодаря этому модель понимает не только отдельные слова, но и их роль в общем контексте.
Во время обучения модель обрабатывает колоссальные объемы данных: книги, статьи, диалоги, документацию, программный код и другие тексты. Она разбивает их на токены — фрагменты слов, символы или короткие единицы текста — и учится предсказывать, какой токен логично появится следующим. На первый взгляд принцип кажется простым, но за счет огромного объема данных и числа параметров модель приобретает способность выполнять очень сложные языковые задачи.
Для создания и работы LLM нужны несколько обязательных компонентов:
- большие массивы обучающих данных;
- мощные вычислительные ресурсы;
- алгоритмы оптимизации;
- инфраструктура для хранения и запуска модели;
- интерфейсы для взаимодействия с пользователем.
Именно сочетание этих факторов делает языковые модели доступными не только в лабораториях, но и в реальных продуктах — от веб-сервисов до мобильных приложений и корпоративных платформ.
Почему LLM стали настолько востребованными
Интерес к большим языковым моделям связан с тем, что они снимают с человека огромное количество рутинной текстовой работы. Там, где раньше требовались часы на ручную обработку писем, документов, инструкций, кодовой базы или клиентских обращений, теперь значительную часть задач можно автоматизировать.
LLM востребованы по нескольким причинам. Во-первых, они универсальны: одна модель может решать разные задачи без разработки отдельного алгоритма под каждую из них. Во-вторых, они легко интегрируются в существующие цифровые системы через API, плагины и интерфейсы. В-третьих, они заметно ускоряют рабочие процессы, особенно там, где основным материалом является текст.
Для бизнеса это означает сокращение времени на повторяющиеся операции, для разработчиков — ускорение создания продуктов, для пользователей — более удобное взаимодействие с сервисами.
Где применяются большие языковые модели
Сфера применения LLM уже давно вышла за рамки экспериментальных проектов. Сегодня они используются в самых разных отраслях, и список кейсов продолжает расти.
Разработка программного обеспечения
В программировании языковые модели стали особенно заметным инструментом. Они помогают писать код, подсказывать синтаксис, объяснять сложные участки, находить ошибки и предлагать исправления. Это полезно как для начинающих разработчиков, так и для опытных специалистов, которые хотят быстрее решать типовые задачи.
LLM умеют работать с разными языками программирования, анализировать структуру проекта и выдавать варианты решений на основе запроса. Они не заменяют разработчика, но заметно ускоряют работу, особенно на этапах прототипирования, отладки, рефакторинга и написания вспомогательного кода.
Обработка естественного языка
Это одно из самых очевидных направлений применения. Языковые модели умеют переводить тексты, делать краткие выжимки, классифицировать сообщения, определять настроение автора, извлекать сущности и структурировать неформализованные данные.
Именно поэтому LLM активно применяют в чат-ботах, службах поддержки, системах поиска, почтовых помощниках, инструментах для анализа отзывов и внутренних корпоративных базах знаний. Там, где есть большой поток текстовой информации, языковая модель может заметно упростить работу.
Образование и наука
В образовательной среде LLM помогают объяснять сложные темы более простым языком, подбирать материалы по теме, структурировать информацию, переводить научные тексты и помогать в подготовке учебных работ. Они могут стать дополнительным инструментом для студентов, преподавателей и исследователей.
В научной среде модели применяются для поиска публикаций, первичного анализа текстов, структурирования данных, составления кратких обзоров и поддержки исследовательской работы. При этом особенно важно помнить, что LLM не должны подменять критическую проверку источников.
Бизнес и маркетинг
В коммерческой среде большие языковые модели используются для генерации текстов, подготовки писем, обработки заявок, автоматизации клиентской коммуникации, анализа обратной связи и поиска новых маркетинговых идей.
Они помогают быстрее создавать контент для сайтов, рассылок, рекламных кампаний и социальных сетей. Кроме того, LLM можно встроить в CRM, формы обратной связи, внутренние сервисы продаж и поддержки. Это снижает нагрузку на команды и позволяет быстрее масштабировать процессы.
Медицина
В медицине языковые модели применяются осторожно, но интерес к ним очень высокий. Они могут помогать в обработке медицинских записей, подготовке выписок, структурировании истории болезни, расшифровке текстовой информации и переводе сложных терминов на более понятный язык.
При этом медицинская сфера остается одной из самых чувствительных к ошибкам, поэтому здесь LLM должны рассматриваться как вспомогательный инструмент, а не как самостоятельный источник окончательных решений.
Какие возможности дают LLM
Большие языковые модели ценят не только за эффект новизны, но и за очень конкретные практические возможности. Они умеют:
- генерировать тексты разных жанров и форматов;
- отвечать на вопросы в диалоговом режиме;
- переводить и переформулировать материалы;
- находить смысловые связи;
- классифицировать и сортировать данные;
- помогать с написанием и проверкой кода;
- создавать черновики документов;
- упрощать сложные формулировки;
- работать с большими объемами информации быстрее человека.
Для компаний это означает повышение эффективности, для команд — меньше ручной работы, для пользователей — быстрее получаемый результат. Именно за счет этой универсальности LLM становятся частью все большего числа цифровых продуктов.
Ограничения больших языковых моделей
Несмотря на впечатляющие возможности, LLM не стоит воспринимать как безошибочную интеллектуальную систему, которая всегда права. У таких моделей есть вполне конкретные ограничения.
Одна из главных проблем в том, что языковая модель не “знает” факты в человеческом смысле и не проверяет их автоматически. Она генерирует ответ на основе обучающих данных, структуры запроса и вероятностной логики. Поэтому модель может выдавать правдоподобный, но неверный ответ.
Среди других ограничений обычно выделяют:
- склонность к фактическим ошибкам;
- зависимость от качества обучающих данных;
- сложности с узкоспециализированными темами;
- риск повторения предвзятых формулировок;
- шаблонность в части ответов;
- слабость в задачах, где нужен строгий причинно-следственный анализ;
- высокие требования к вычислительным ресурсам.
Именно поэтому в медицине, праве, финансах, безопасности и других чувствительных областях результат работы LLM обязательно должен проходить проверку человеком.
Этические и практические вызовы
Отдельного внимания заслуживает не только точность, но и вопрос ответственности. Языковые модели обучаются на больших массивах данных, а значит, могут унаследовать ошибки, предубеждения, токсичные формулировки или сомнительные паттерны, присутствующие в этих источниках.
Поэтому сегодня развитие LLM связано не только с гонкой за качеством генерации, но и с работой над безопасностью, фильтрацией нежелательных ответов, контролем качества, прозрачностью использования и настройкой моделей под конкретные сценарии.
Чем глубже такие системы входят в повседневные и корпоративные процессы, тем важнее становится вопрос: не просто что модель умеет, а насколько надежно, корректно и безопасно она это делает.
Куда движется развитие LLM
Большие языковые модели развиваются очень быстро. Если вначале акцент делался на размере и количестве параметров, то сейчас все больше внимания уделяют качеству, специализации, снижению затрат и удобству внедрения.
Можно выделить несколько заметных направлений развития.
- Во-первых, это персонализация. Модели все чаще настраивают под конкретного пользователя, компанию или сценарий использования.
- Во-вторых, растет интерес к более компактным моделям, которые можно запускать локально или использовать в устройствах с ограниченными ресурсами.
- В-третьих, развивается подход, при котором LLM становятся частью более сложных систем: работают вместе с поиском, базами данных, корпоративными хранилищами знаний, инструментами проверки фактов и внешними сервисами.
Кроме того, усиливается интерес к гибридным системам, где генерация текста сочетается с более строгой логикой, проверкой данных и инструментами контроля качества. Это особенно важно для программирования, аналитики и корпоративных решений.
Почему LLM уже меняют технологии
На практике влияние больших языковых моделей уже заметно. Они изменили пользовательские интерфейсы, сделали разговорный формат взаимодействия с системами привычным, упростили доступ к сложным функциям и позволили быстрее автоматизировать текстовые задачи.
Раньше многие цифровые процессы требовали отдельного интерфейса, сложной логики и долгого ручного взаимодействия. Теперь пользователь может просто сформулировать задачу обычным языком. Это меняет сам подход к работе с программами: от набора кнопок и команд — к естественному диалогу.
Для бизнеса это означает новые способы взаимодействия с клиентами и сотрудниками. Для разработчиков — новые форматы продуктов. Для пользователей — более простой доступ к технологиям, которые раньше казались слишком сложными.
Главное
LLM — это не просто модный термин из мира искусственного интеллекта, а одна из ключевых технологий текущего этапа цифровой трансформации. Большие языковые модели уже применяются в разработке, образовании, бизнесе, маркетинге, поддержке, аналитике и медицине. Они помогают автоматизировать работу с текстом, ускоряют процессы и делают взаимодействие с цифровыми системами более естественным.
При этом относиться к ним как к магическому инструменту не стоит. Их эффективность зависит от качества модели, сценария использования, данных, настройки и человеческого контроля. Но одно можно сказать точно: LLM уже меняют технологический ландшафт, и в ближайшие годы их роль будет только расти.