Рассказываем, как с помощью нестандартных подходов и самописных инструментов мы увеличили трафик более чем в 230 раз за 10 месяцев в нише транскрибации за рубежом.

Данный кейс занял три первых места в кейс-чемпионате Топвизора, делимся опытом в сфере зарубежного продвижения.
О проекте: Any2Text — сервис по транскрибации аудио и видео в текстовый формат. У проекта глобальная география и 40 языковых версий, включая английскую.
Ниша: SaaS‑сервисы.
Задача: SEO‑продвижение на бурж для привлечения новой аудитории и клиентов.
Инструменты: Screaming Frog, Google Search Console, Топвизор, Ahrefs, Semrush, Moz, Arsenkin Tools.
Срок работ над проектом: 01.10.2024 — по настоящее время.
Проблемы и точки роста:
- У клиентского сайта была всего 1 страница. У конкурентов — 1 страница под отдельный кластер запросов, которых в нише несколько сотен для разных языков.
- Практически нулевая ссылочная масса. Наличие и объём качественных ссылок в Google, особенно в бурже — один из основных факторов успешного SEO‑продвижения.
- Отсутствие мультиязычности. Спрос в нише есть не только у англоязычных запросов. У конкурентов реализованы структуры на подпапках для каждого языка.
Позиции сайта на начало работ:
Всего мы мониторили 861 ключевой запрос по 5 ГЕО и языкам:
- Английский — Лондон
- Немецкий — Берлин
- Испанский — Мадрид
- Французский — Париж
- Итальянский — Рим
На старте работ по позициям в Google была следующая картина:
- ТОП 1‑3: 0 запросов;
- ТОП 1‑10: 8 запросов;
- ТОП 11‑30: 10 запросов
Позиции на текущий момент:
- ТОП 1‑3: 184 запроса;
- ТОП 1‑10: 433 запроса;
- ТОП 11‑30: 133 запроса
Этап 1
Семантическое ядро и структура сайта
Сбор семантики — это как присед в качалке. Не делаешь — не растешь. Алгоритм сбора семантического ядра для зарубежных проектов не такой, как для сайтов в Рунете. Там нет возможности взять запросы из Яндекс.Вордстата, поэтому пришлось адаптироваться.
Да, есть официальный инструмент от Google — Keyword Planner, однако, его функционал оставляет желать лучшего, так что это не наш вариант.
В итоге семантику собирали так:
- Анализировали структуры сайтов конкурентов
- Semrush
- Google Search Console
- Поисковые подсказки
- Кастомный парсер
Далее в игру вступает креатив.
На момент начала работы с проектом, у нас не было платного аккаунта в Semrush, нужно было придумывать, как выкручиваться из данной ситуации.
Вооружившись несколькими аккаунтами с триалками тарифа GURU и верным товарищем‑разработчиком, мы создали первый парсер Semrush с функционалом, аналогичным сервису Word Keeper.
Парсер в асинхронном режиме собирал выгрузки ключевых фраз по каждой маске с нескольких аккаунтов и вычищал дублирующиеся запросы, а также выгружал информацию по частоте и сложности продвижения.
Чтобы максимально охватить семантику, ГЕО для парсинга в Semrush выбрали США, так как это самое конкурентное в данной нише.
Парсер был реализован в формате телеграм‑бота, чтобы не было необходимости устанавливать его на устройство.
Интерфейс парсера:
Результат - Excel‑файл:
Так мы собрали список запросов, после чего кластеризовали его в KeyCollector. Получилась структура сайта из основных разделов, которые делятся на сотни кластеров.
Чтобы наглядно представить структуру заказчику, ядро было оформлено в виде Mindmap:
В итоге получилось 7 разделов:
- Аудио в текст;
- Видео в текст;
- Транскрибация файлов определенного формата;
- Транскрибация файлов формата 1 в формат 2;
- Транскрибация определенного языка;
- Транскрибация определенного языка 1 с переводом на язык 2;
- Общие ключи (транскрибация интервью, фильмов, звонков и т.д.).
Однако недостаточно просто собрать ядро, необходимо внедрить его на сайт.
Была подготовлена инструкция по добавлению посадочных страниц для разработчика со стороны заказчика. Она содержала в себе все данные для быстрого добавления новых посадочных страниц, которые были подготовлены при помощи семантики:
- Метатеги;
- H1;
- URL;
- Шаблонный текст под каждый кластер.
Так как у заказчика есть свой разработчик, мы реализовали пакетное добавление страниц для их быстрой публикации.
Табличка с данными преобразовывалась в json‑файлы, содержащие в себе всю необходимую информацию о страницах. С помощью этого функционала на сайте публиковалось по несколько сотен страниц за одну итерацию.
В итоге мы получили структуру, и вот, на сайте уже не 1 страница, а ~1500 на 5 языках (сейчас их уже 40, количество посчитайте сами).
Теперь у нас не единственная страница под все запросы, а каждая под свой кластер, как и должно быть. Все по науке.
С семантикой разобрались, переходим к следующей проблеме.
Этап 2
Мультиязычность
Напоминаем, проект продвигается на зарубежный рынок. Мы изучили поисковую выдачу по целевым запросам и пришли к выводу: языковые версии сайта лучше размещать в подпапках. У конкурентов из ТОП‑10 страницы сделаны именно так. Это не Рунет — в бурже Google чаще отдает предпочтение подпапкам, а не поддоменам.
Чтобы подготовить контент для страниц на другие языки, отличные от английского, нужно быть либо полиглотом, либо SEOшником с API DeepL и Google Переводчиком. Так как мы не относимся к первой группе, выбираем второй вариант.
На этом этапе мы подготовили контент, прописали URL и добавили страницы на сайт. Но необходимо сделать еще 1 шаг, чтобы всё работало как часы.
Этот шаг — настройка атрибутов hreflang для страниц.
После реализации соответствующего тех. задания, в глазах Google, у нас не просто переведенный и дублирующийся контент на страницах, а А‑Д‑А‑П‑Т‑И‑Р‑О‑В‑А‑Н‑Н‑Ы‑Й под каждый языковой регион. Да и пользователям в радость, ведь теперь у них в поиске будут ранжироваться страницы на понятном для них языке.
Этап 3
Ссылочное продвижение
Если вы вдруг подумали, что сервисы онлайн‑транскрибации — легкая ниша для внешнего продвижения, смеем огорчить.
Вот таких конкурентов удалось выделить на этапе первичного аудита проекта:
Да, 0,5 — такой был наш DR по версии Ahrefs на старте. DR называют пузомеркой, которую лично мы считаем достаточно синтетической. Однако в нашем случае, она и количество ссылающихся доменов наглядно отражают плачевность ситуации, которая была в начале ведения проекта.
Чтобы сайт рос в Google, НУЖНЫ ссылки.
Качественные ссылки. У проекта был отдельный бюджет на ссылочное продвижение. Однако для буржа это невеликие деньги, но все же необходимо было как‑то с этим работать.
На проекте используются 3 источника ссылок:
- Покупка статейных ссылок с зарубежных бирж;
- Покупка крауд‑ссылок на Kwork;
- Ручной крауд по нашей агентской базе зарубежных трастовых площадок.
С таким бюджетом, ежемесячно получалось проставлять:
- 4‑5 купленных статейных ссылок;
- 30‑50 купленных крауд‑ссылок;
- 10‑15 крауд‑ссылок руками стажера — бесценно.
Но прежде, чем проставлять ссылки, нужно определить страницы, на которые они будут вести.
Тут на сцену выходит второй разработанный парсер «по кластерам».
В чем его суть:
Парсер агрегирует в себе страницы из ТОП‑10 по необходимому ГЕО (сбор идет через XMLriver) и ссылочные данные по этим страницам в сервисе Ahrefs.
Как выглядит результат работы:
С помощью этого инструмента на старте продвижения удалось определить перспективные и не слишком конкурентные кластеры, в которые не нужно было вливать много бюджета, чтобы занять ТОП.
Например, такой страницей оказалась посадочная под запрос «mp3 to text», которая через два месяца после начала ссылочного продвижения уже заняла ТОП‑1 по самым конкурентным ГЕО (США, Великобритания и т.д.).
После ссылочного продвижения менее конкурентных кластеров, позиции по высокочастотным запросам также начали расти и достигли ТОП‑20–30. Рост доверия к сайту со стороны Google позволил перераспределить бюджет на продвижение этих страниц, что впоследствии обеспечило им закрепление в ТОПе.
Примеры таких запросов:
- «audio to text»;
- «video to text».
Статейные ссылки покупались на PRnews*
*Аналогичная gogetlinks и miralinks площадка, только с фокусом на зарубежные сайты.
База релевантных доменов формировалась поэтапно: из Ahrefs выгружались сайты‑доноры ведущих зарубежных IT и Digital‑компаний. Дополнительно использовался подход Link Gap — приоритет отдавался тем доменам, с которых получают ссылки сразу несколько прямых конкурентов, но которые ещё не ссылаются на наш сайт.
Базу собрали. А что дальше? Объём данных приличный, и проверять каждый домен вручную на бирже займет примерно столько же времени, сколько говорят, что SEO умирает.
Решение было очевидным — разработали третий парсер.
Он автоматически проверял наличие домена на бирже и, если находил, собирал всю необходимую информацию: стоимость размещения, условия, метрики донора, трафик и тематику.
Получаем отчет в виде удобного Excel‑файла:
Это позволяло быстро отбирать релевантных доноров, ценных для проекта и соответствующих бюджету.
Теперь по данным Ahrefs, уже не все так грустно:
Этап 4
Индексация: что делать, когда у тебя более 10 000 страниц?
Добавлять необходимые посадочные страницы — круто.
Когда они не индексируются — не круто.
Когда индексируется то, что не должно — очень плохо.
Когда проект включает не 50, а свыше 10 000 страниц, важно, чтобы каждая из них участвовала в поисковой выдаче — иначе зачем вообще было их создавать?
Работы, которые были проведены:
- Создали автогенерирующийся файл sitemap.xml;
- Закрыли в robots.txt служебные страницы;
- Отправили файл sitemap.xml на обход в вебмастерах Google и Bing;
- Внедрили внутреннюю перелинковку через футер сайта;
- Создали HTML‑карту сайта;
- Индексация через тг‑бота SpeedyIndex.
Вручную отправлять страницы в Google Search Console — не наш вариант, их слишком много.
Почему не использовался Google Indexing API? Ответ простой: после прошлогоднего апдейта процент индексации через API стал крайне низким, поэтому вместо этого использовался SpeedyIndex, который отлично себя показал.
Методика KGR
KGR (Keyword Golden Ratio, пер. «Золотое сечение ключевых слов») — это методика, суть которой заключается в отборе ключей с низким уровнем конкурентности с вычислением параметра KGR.
KGR равен количеству сайтов в выдаче, которые включают слова запроса в title, делённый на месячную частотность ключевой фразы.
Отличными ключевыми фразами считаются те, у которых KGR ниже 0,25.
Те ключи, где этот параметр от 0,25 до 1 — более конкурентные.
Те ключи, где этот параметр от 1 — максимально конкурентные.
Методика использовалась на старте продвижения, чтобы как можно раньше начать привлекать трафик, пусть и по низкочастотным запросам. Благодаря этому на страницы сразу начинали заходить люди, что положительно сказывалось на необходимых поведенческих факторах.
Так мы подошли к четвертому парсеру.
Его задача — собирать количество результатов в Google по каждому ключу с использованием оператора allintitle.
Затем данные сопоставлялись с результатами из парсера Semrush, который, напомню, также фиксировал частотность запросов. Это позволило получить данные для подсчёта KGR.
Используя эту методику на старте продвижения, мы корректировали Title страниц так, чтобы даже без ссылочной массы они могли успешно конкурировать в выдаче.
Результат
Еженедельный трафик вырос на 23 145% или в 232 раза
Пожалуй, мы добились самого главного результата работы над проектом — удовлетворённого и довольного клиента. Он высоко оценил результаты совместной работы, а также коммуникацию и soft skills нашей коллеги — Project‑менеджера Дианы, да так, что завёл к нам на SEO‑продвижение ещё три своих проекта, за что мы ему очень благодарны.
Трафик ДО:
Трафик ПОСЛЕ:
Динамика показов и трафика в Google Search Console:
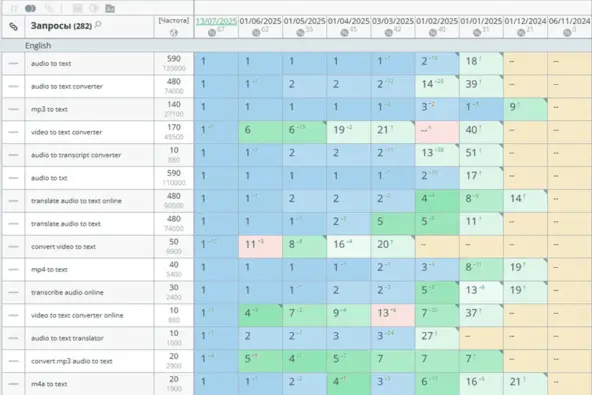
Позиции в Топвизоре по 5 ГЕО:
Помимо роста трафика и позиций, клиент ощутил рост выручки, которую генерирует сайт. За неполные 10 месяцев она выросла в 27 раз — это отличный результат.
В феврале 2025 года проект вышел на окупаемость. Уже в марте ROMI* составил 50,5%, а в мае достиг 103% и продолжает расти. Иными словами, в мае на каждый вложенный рубль, заказчик получал чуть больше двух рублей.
*При расчете ROMI учитывались расходы как на SEO‑услуги, так и на приобретение ссылок.
С этим кейсом рос не только сайт клиента, но и компетенции нашего SEO‑отдела. Инструменты и методы, которые внедрялись и использовались на этом проекте, теперь адаптируются и применяются и на других проектах агентства.