Один из вариантов получения данных на gedmatch.com — это встроенные инструменты «One-to-Many». Выгрузки этого варианта в бесплатной версии ограничены количеством в 3000 записей и к экспорту этих данных я вернусь позже.
Другой вариант — это анализ данных по проектам. Тут списки пользователей будут меньше, но в них находятся те, кто ведёт поиски по определённым регионам, а значит больше шансов найти родственников или коллег по региону.
Сейчас я добавился в 13 проектов и возможно, что в скором времени их станет чуть больше. Для того, чтобы посмотреть данные, на GEDmatch нужно открывать каждый проект отдельно. В некоторых проектах присутствуют одни и те же люди (что тоже даёт почву для размышлений) и эти совпадения нужно как-то отмечать. Чтобы получить данные со всех проектов в одной таблице я использовал надстройку Excel по получению, преобразованию и объединению данных из нескольких источников (Power Query).
На данный момент мои шаги по обновлению данных:
1. Открываю страницу каждого проекта с нужными мне параметрами.
2. Для каждого проекта запускаю в консоли браузера javascript-код для скачивания CSV-файла с данными по проекту, включая адрес электронной почты и информацию о наличии у пользователя gedcom-файла (эти данные не попадают в выгрузку по умолчанию) и с нужным мне именем файла.
3. Заменяю переименованные CSV-файлы в локальной папке с основным Excel-файлом.
4. Отрываю Excel-файл с настроенными подключениями к исходным данным из CSV-файлов.
5. Запускаю обновление источников в Excel.
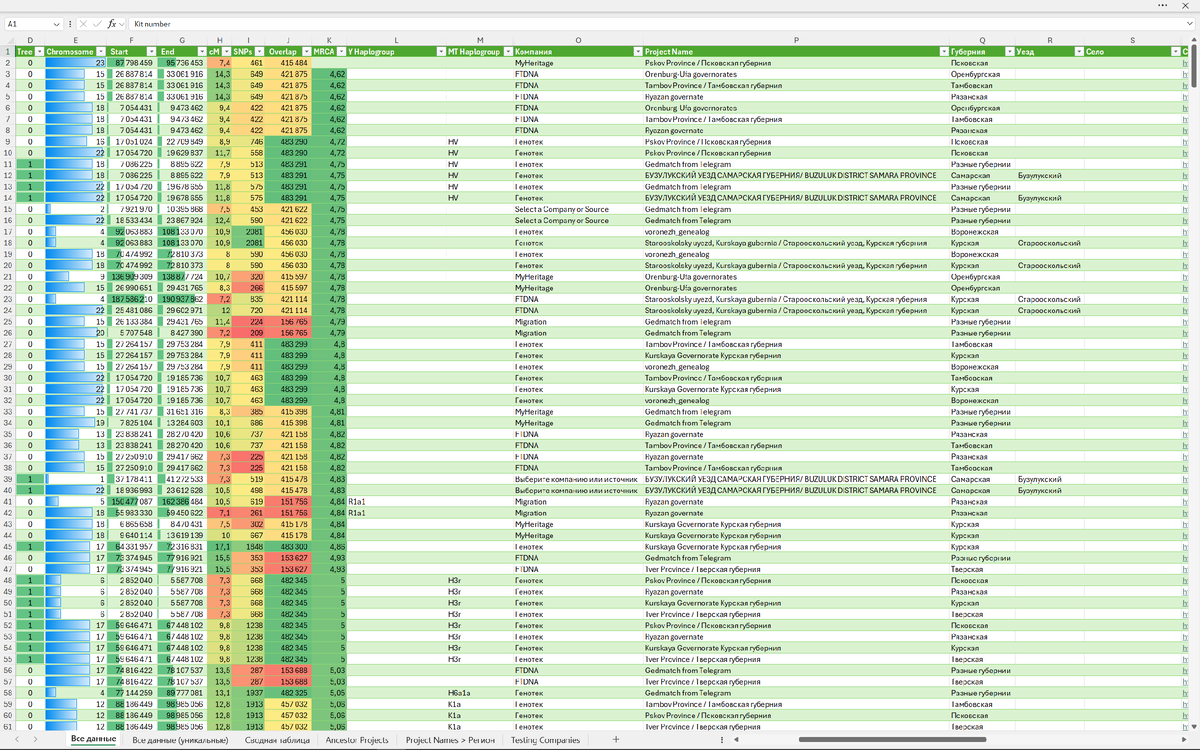
Скачанные выгрузки по проекту (формат файла — CSV) содержат поля с данными:
- Kit number — номер комплекта пользователя.
- Name — имя пользователя (указывается пользователем при загрузке результата теста, «звёздочкой» помечено если вместо имени показан псевдоним).
- Chromosome — хромосома.
- Start — Начало сегмента ДНК, который совпадает между двумя наборами ДНК.
- End — Конец сегмента ДНК, который совпадает между двумя наборами ДНК.
- cM — Наибольший общий сегмент (Largest segment, cM) — это самый длинный участок ДНК, который совпадает между двумя людьми в процессе генетического тестирования. Наибольший общий сегмент может дать более точное представление о степени родства.
- SNPs — Single-nucleotide polymorphism (Однонуклеотидный полиморфизм) Общая длина совпадающих сегментов (Total cM) — чем больше общая длина совпадающих сегментов, тем ближе родственные связи между двумя людьми.
- Overlap — Количество общих SNPs для сравниваемых комплектов. Большее количество общих SNPs обычно указывает на более тесную генетическую связь.
- MRCA — Most recent common ancestor (ближайший общий предок) — примерное количество поколений до общего предка.
- Y Haplogroup — Гаплогруппа по мужской линии (указывается пользователем при загрузке результата теста).
- MT Haplogroup — Гаплогруппа по женской линии (указывается пользователем при загрузке результата теста).
- Source — Название компании, делавшей тест ДНК (указывается пользователем при загрузке результата теста).
- Email — Адрес электронной почты пользователя (отсутствует в выгрузке по умолчанию).
- Tree — информации о наличии у пользователя gedcom-файла (отсутствует в выгрузке по умолчанию).
Средствами редактора Power Query в Excel в каждую выгрузку добавил поле Project Name, чтобы в общей таблице видеть из какого проекта данные. И для данных в общей таблице распределил проекты по губерниям/уездам/сёлам.
Сделал ещё одну общую таблицу с данными, исключив дублирующие значения из разных проектов.
Особенность выгрузки по проекту — это то, что десятичным разделителем у значений полей cM и MRCA является «точка» (у нас это «запятая»). Из-за этого получается текстовый формат столбца, что не всегда удобно при работе с данными. Чтобы не менять настройки Excel — в Power Query заменил в данных «точку» на «запятую» и получил возможность преобразования в числовой тип данных.
23-я хромосома отображается не числом, а текстом (в моих выгрузках такая запись одна из 938). Для поля Chromosome заменил обозначение хромосомы «X» на число «23». Сделал это, что бы можно было сортировать объединённые данные по номеру хромосомы.
Сделал объединение разных вариантов компаний под единым названием. Например, варианты указания компании «Генотек» были: GENOTEC, Genotec, Genotech, Genotek, genotek, GENOTEK, Genotek RF, Genotek V5, Gtek.
Предположил, что может быть указано в названии компании вместо знаков вопросов:
????? — Атлас
?????? — Другой
?????? (??????? ??? ????) — Другое (введите имя ниже)
??????? — Генотек
???????? ???????? ??? ???????? — Выберите компанию или источник
Пока не придумал вариант на 11 букв: ???????????
Возможно, что копируют слово «обязательно».
А вот с именами и псевдонимами так уже не получится. Тут отчасти может помочь адрес электронной почты, но не всегда.
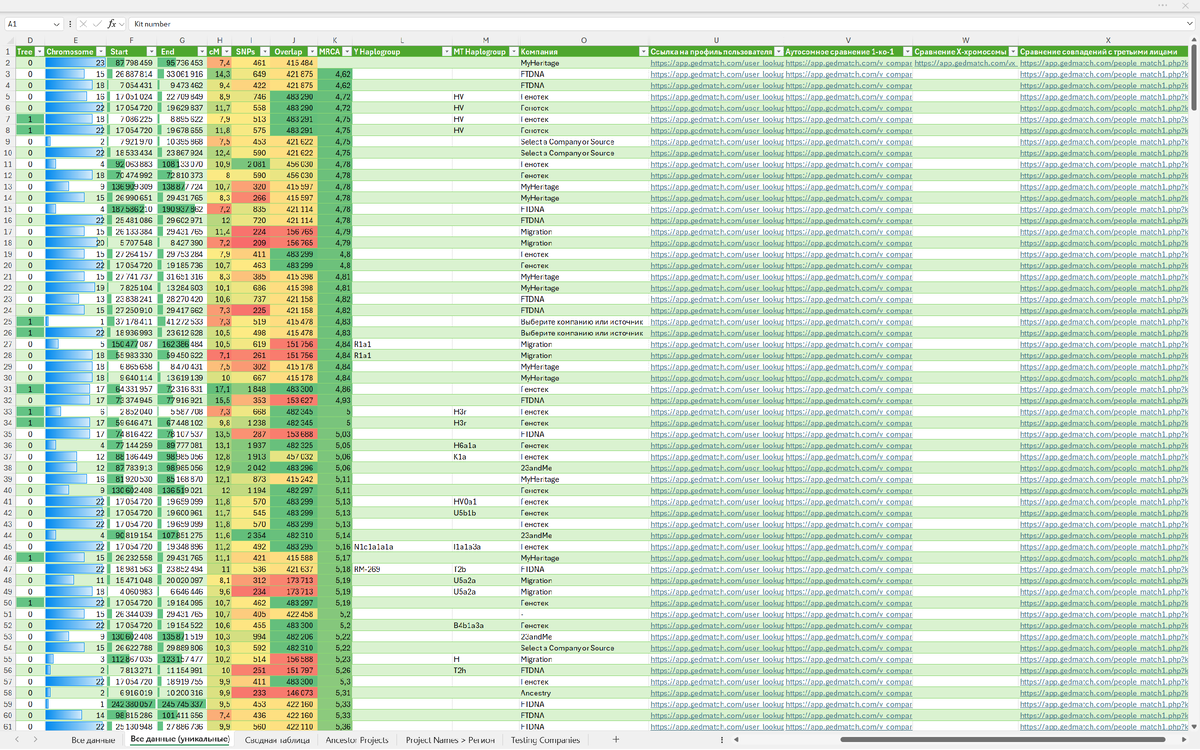
В общую таблицу с данными добавил сформированные по шаблонам ссылки на:
- User Information Page (Страница пользователя).
- Autosomal One-to-one Comparison (Аутосомное сравнение 1 ко 1).
- X-DNA One-to-one Comparison (Сравнение X-хромосомы — только в случае наличия в данных 23-й хромосомы).
- People who match both kits, or 1 of 2 kits (Сравнение совпадений с третьими лицами).
Для полей Tree, cM, SNPs, Overlap и MRCA настроил условное форматирование цветовыми шкалами, а для полей Chromosome, Start и End — гистограммами. Настроил сортировку по полям: MRCA, Kit number, Chromosome, Start. И готово. Можно анализировать данные. Но это уже другая история...
#gedmatch #excel #itгенеалогия