Проблема длинного контекста остаётся одним из главных узких мест больших языковых моделей: чем больше текст, тем выше задержки и тем дороже вычисления. Теперь NVIDIA вместе с исследователями из Astera, Стэнфорда, UC Berkeley и UC San Diego предложила элегантное решение — TTT‑E2E, метод, который ускоряет работу с длинным контекстом без дополнительного кэша и сложной архитектуры.
Ключевая идея TTT‑E2E — сжимать контекст прямо в веса модели. Вместо того чтобы хранить всё прочитанное во внешней памяти или в attention‑кэше, модель в процессе инференса продолжает учиться: она читает текст, делает предсказания и одновременно с помощью градиентного обновления «впитывает» важную информацию в свои параметры. Это и есть так называемое test‑time training — обучение во время тестирования.
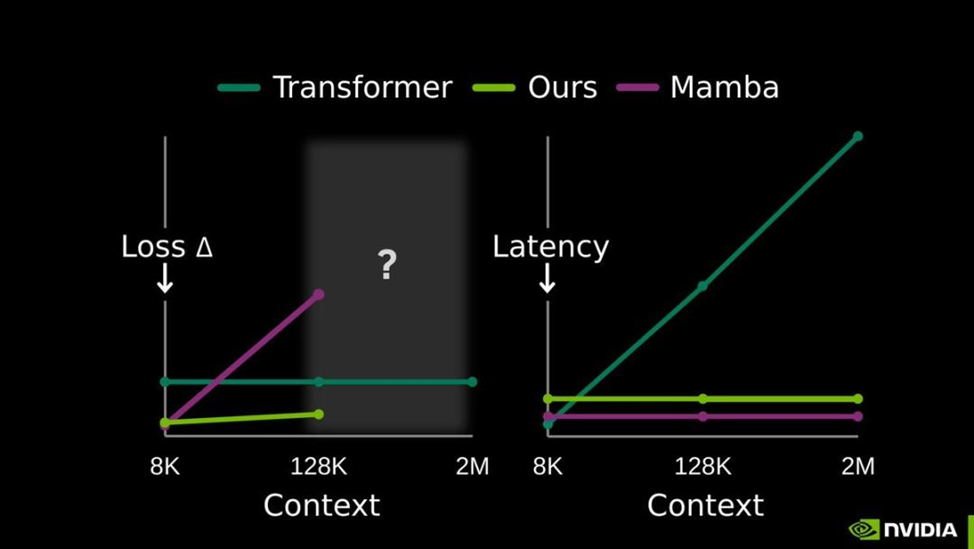
По результатам экспериментов, на контексте 128K токенов TTT‑E2E работает в 2,7 раза быстрее, чем классический Transformer с полным вниманием, а при 2 млн токенов ускорение достигает 35 раз — без потери качества. При этом задержка инференса практически не зависит от длины контекста и ведёт себя как у RNN: одинаково быстро для 8K и 128K.
В отличие от статических решений вроде условной памяти DeepSeek, NVIDIA выбрала динамический путь. TTT‑E2E не требует экзотической архитектуры: он построен на стандартном Transformer со скользящим окном внимания, что упрощает внедрение. Инновация лежит в обучающей логике. На этапе предварительного обучения применяется мета‑обучение: модель заранее «приучают» быстро адаптироваться к режиму тестового обучения, чтобы на инференсе она могла эффективно обновляться без дестабилизации.
Для устойчивости и скорости разработчики ввели несколько ограничений: обновляются только MLP‑слои и лишь последняя четверть блоков, используется мини‑батч с окном внимания, а также двойной MLP — один хранит базовые знания, другой отвечает за впитывание нового контекста. Это снижает вычислительные затраты и защищает модель от «забывания» уже выученного.
Конечно, метод не универсален. В задачах вроде «найди иголку в стоге сена», где важны точные детали, TTT‑E2E уступает полному вниманию: сжатие неизбежно отбрасывает часть информации. Кроме того, мета‑обучение сложнее и медленнее стандартного претрейна. Но для длинных документов, диалогов, кода и аналитических сценариев выигрыш оказывается принципиальным.
Главное же в другом: TTT‑E2E показывает альтернативный путь развития длинного контекста — не за счёт наращивания памяти, а через непрерывное обучение. Если этот подход приживётся, модели смогут работать с огромными объёмами текста так же быстро, как сегодня с короткими, не упираясь в потолок attention.
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
ИИ сегодня — ваше конкурентное преимущество завтра!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru
Сайт https://www.smssystems.ru/razrabotka-ai/