Привет! Сегодня разберём тему, которая звучит скучно — «присваивание и литералы в C». Но на самом деле это фундамент, без которого ты не поймёшь, как работают игровые движки, как шифруются твои сообщения в Telegram и почему твой код иногда ведёт себя как будто у него своя жизнь.
Поехали 🚀
Присваивание — это не то, что ты думаешь
Все знают, что = это присваивание. Написал x = 5; — и переменная получила значение. Элементарно, Ватсон.
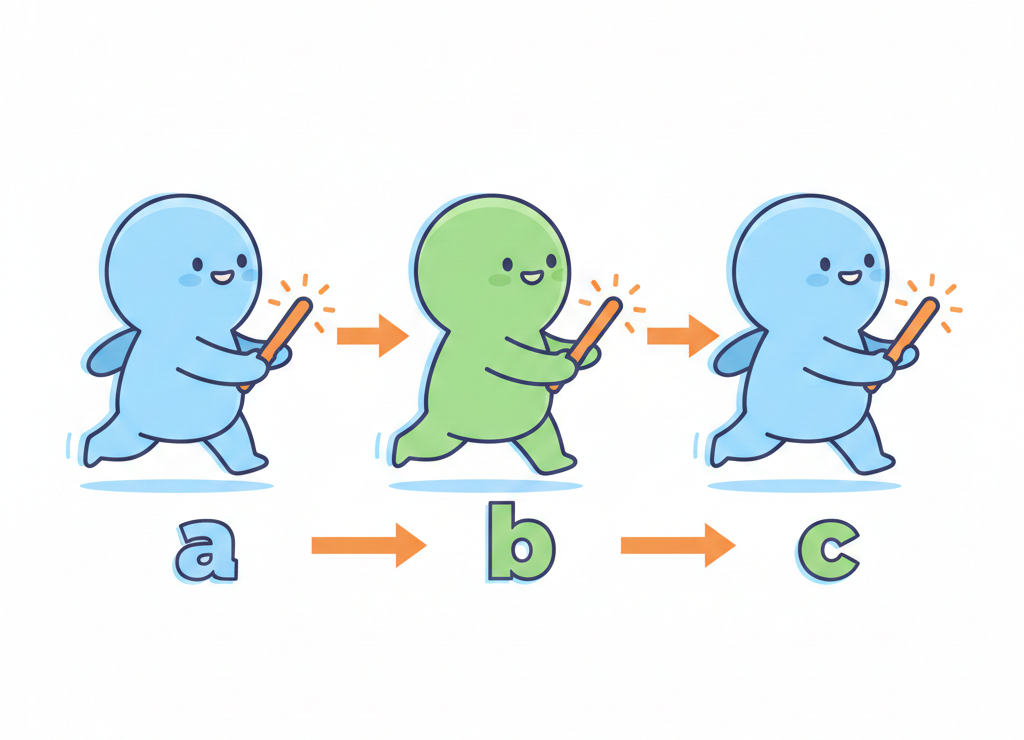
Но вот факт, который взрывает мозг: в C присваивание — это операция, которая возвращает значение. Не просто записывает число в память, а ещё и отдаёт его дальше по цепочке.
Поэтому такой код работает:
int a, b, c;
a = b = c = 42;
Компилятор читает справа налево:
- c = 42 → записывает 42 в c и возвращает 42
- b = 42 → записывает 42 в b и возвращает 42
- a = 42 → и так далее
Это как эстафета 🏃♂️ — каждый участник передаёт палочку дальше, но при этом ещё и пробежал свой этап.
Зачем это знать? Потому что без этого понимания ты не поймёшь, почему можно писать while ((c = getchar()) != EOF) — тут присваивание внутри условия, и оно работает именно благодаря тому, что возвращает значение.
Инициализация ≠ Присваивание (и это важно)
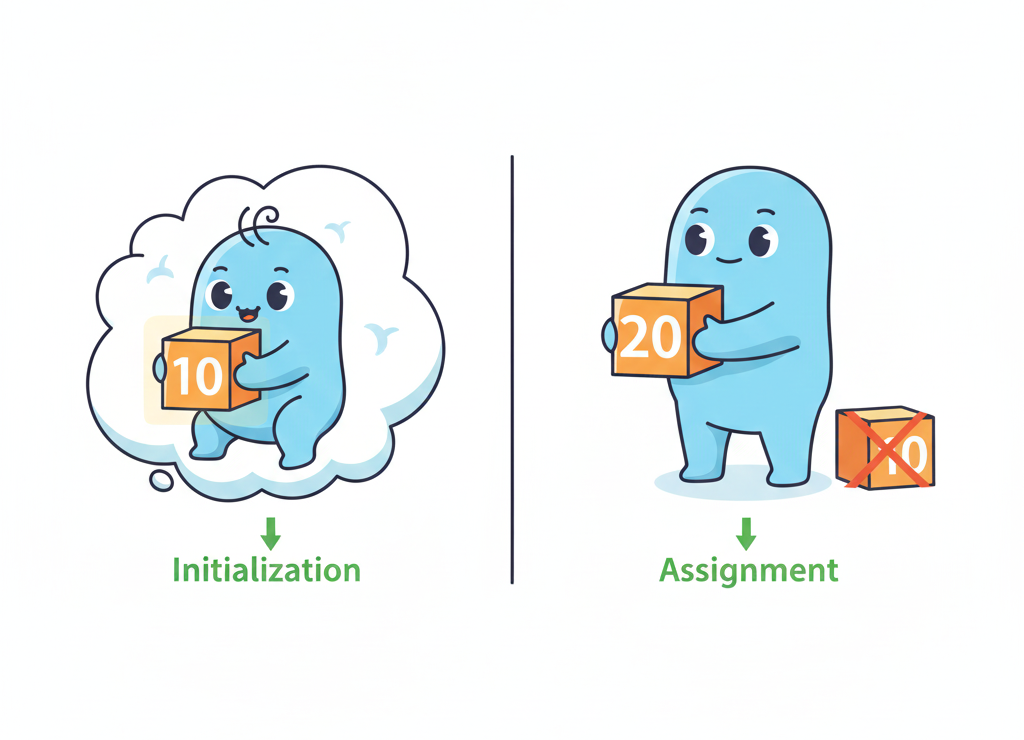
int x = 10; // инициализация
int y;
y = 10; // присваивание
Выглядит одинаково? Для компилятора — две разные вселенные.
Инициализация — это когда переменная получает значение в момент рождения. Присваивание — когда ты меняешь значение уже существующей переменной.
Почему это не просто формальность:
- Инициализация работает для массивов и структур: int arr[] = {1, 2, 3};
- Присваивание так не работает: arr = {4, 5, 6}; ❌ — компилятор пошлёт тебя
Это как разница между «родиться с именем» и «сменить имя через паспортный стол» — формально вроде одно и то же, но процедуры разные 🎭
Литералы: когда 100 это не просто сто
Число 100 в коде — это литерал. Компилятор видит его и думает: «Окей, целое число, значит int, займу под него 4 байта».
Но если напишешь 100000000000 — компилятор подумает: «В int не влезет... Возьму long. Не влезет? Возьму long long». И так, пока не найдёт подходящий тип.
Системы счисления: один литерал, три лица
int dec = 100; // десятичная (обычная)
int hex = 0x64; // шестнадцатеричная
int oct = 0144; // восьмеричная
Внимание! 0144 ≠ 144. Ноль в начале — это магический префикс, который говорит компилятору: «Это восьмеричное число».
Почему это важно? Потому что в реальном коде можно случайно написать int time = 0900; (хотел указать 9 утра) — и получишь ошибку компиляции, потому что в восьмеричной системе нет цифры 9 😅
Хекс (0x) используется везде:
- Цвета в веб-дизайне: #FF5733 — это те же хексы
- Адреса памяти в отладчике
- Битовые маски для флагов в настройках
Суффиксы: когда нужно говорить компилятору напрямую
100U // unsigned int
100L // long
100ULL // unsigned long long
10.0F // float (а не double!)
Зачем? Чаще всего — чтобы избежать предупреждений. Например, если у тебя переменная типа float, а ты пишешь:
float pi = 3.14; // компилятор: "Эй, 3.14 это double, могут быть потери!"
Правильно:
float pi = 3.14F; // компилятор: "Понял, принял"
Лайфхак: Всегда используй заглавную L, а не строчную l — потому что l легко спутать с единицей: 100l выглядит как 1001 🤦
Символы: когда 'A' это число, а не буква
Вот это реально ломает шаблон первый раз:
char letter = 'A';
printf("%c\n", letter); // выведет: A
printf("%d\n", letter); // выведет: 65
Что происходит? Символ 'A' — это на самом деле число 65 (его код в таблице ASCII). Компьютер не знает букв, он знает только числа. Когда ты пишешь 'A', компилятор переводит это в 65.
Одинарные vs двойные кавычки
'A' // символ (тип int, значение 65)
"A" // строка (массив из двух элементов: 'A' и '\0')
Это не взаимозаменяемо. Если напишешь:
char c = "A"; // ❌ ОШИБКА
Компилятор скажет: «Ты пытаешься засунуть массив в переменную под один символ. Ты серьёзно?»
Почему это важно? Потому что все текстовые протоколы, все форматы данных, вся работа с текстом в C строится на понимании этой разницы. HTTP-запросы, JSON, XML — всё это манипуляции символами как числами.
Бонус: символы в шифровании
Хочешь простейший шифр? Сдвиг символов:
char secret = 'H' + 3; // теперь это 'K'
Это основа шифра Цезаря — того самого, которым пользовались древние римляне (и который взламывается за 5 секунд, но это уже детали 😏).
Вещественные числа: когда 10 ≠ 10.0
int a = 10; // целое число (int)
double b = 10.0; // вещественное (double)
Для математики это одно и то же. Для компилятора — принципиально разные типы.
Почему? Потому что:
- Целые числа хранятся точно
- Вещественные числа хранятся приблизительно
Вот почему 0.1 + 0.2 в любом языке программирования даёт не 0.3, а 0.30000000000000004 🤯
Экспоненциальная форма
double big = 1e9; // 1 × 10⁹ = 1 000 000 000
double small = 5e-3; // 5 × 10⁻³ = 0.005
Где используется:
- Физические расчёты (скорость света: 3e8 м/с)
- Работа с очень большими числами (количество операций GPU)
- Научные вычисления (постоянная Планка: 6.62607015e-34)
sizeof: оператор, который показывает правду
printf("%zu байт\n", sizeof(int)); // обычно 4
printf("%zu байт\n", sizeof(char)); // всегда 1
printf("%zu байт\n", sizeof(double)); // обычно 8
Зачем это нужно? Потому что размеры типов не фиксированы стандартом C. На твоём компе int может быть 4 байта, а на каком-нибудь микроконтроллере — 2 байта.
sizeof — это способ писать переносимый код, который будет работать везде.
Применение в жизни:
- Выделение памяти: malloc(n * sizeof(int))
- Копирование данных: memcpy(dest, src, sizeof(data))
- Проверка размеров структур для оптимизации
Главный инсайт 💡
Компилятор C не угадывает твои намерения. Он берёт то, что ты написал, и интерпретирует строго по правилам.
- 'A' — это символ
- "A" — это строка
- 100 — это int
- 100.0 — это double
- 0100 — это восьмеричное ~~и потенциальная головная боль~~
Понимание этих деталей — это не зубрёжка ради зубрёжки. Это ключ к тому, чтобы писать код, который делает то, что ты имел в виду, а не то, что получилось случайно.
Это разница между программистом, который пишет код, и программистом, который понимает, что происходит на уровне железа. А понимание = власть 🔥
🔥 Хочешь копнуть глубже? Полный учебный материал с детальными примерами, схемами и крутыми иллюстрациями ждёт тебя на нашем сайте!