Исследование 30+ учёных из 11 топ‑университетов (UIUC, Стэнфорд, Принстон, Гарвард, Беркли и др.) предлагает внятный ответ: узкое место современных AI‑агентов — их адаптивность.
Агент в понимании авторов — это не просто чат‑модель, а система, которая сама планирует шаги, использует инструменты (поиск, компилятор, БД), ведёт память и способна решать составные задачи. В реальном мире такая система должна подстраиваться: к новой предметной области, другим данным, изменившемуся API или требованиям пользователей. И вот здесь всё ломается.
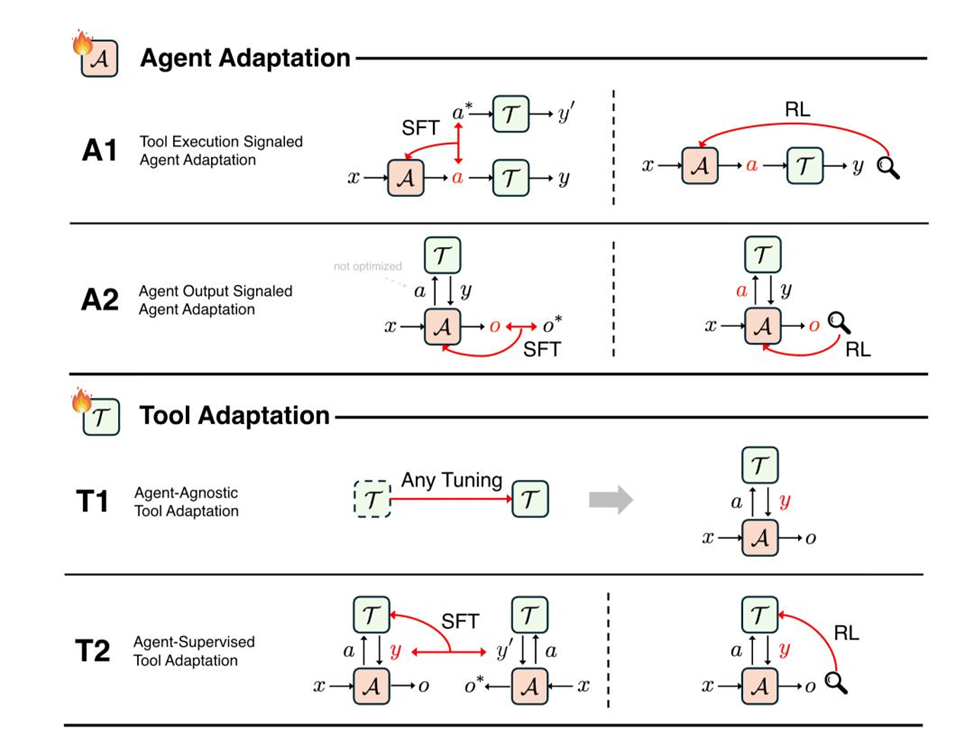
2×2: четыре парадигмы адаптации агента
Авторы предлагают рассматривать адаптацию по двум осям:
- Что мы адаптируем?
- самого агента (Agent Adaptation),
- или инструменты, которыми он пользуется (Tool Adaptation).
- Откуда сигнал обратной связи?
- от результата работы инструмента,
- или от оценки финального вывода агента.
Получается 4 квадранта:
- A1 — агент учится по сигналу от инструментов
Пример: модель смотрит, компилируется ли сгенерированный код, корректен ли поиск, и корректирует свою стратегию использования инструментов. - A2 — агент учится по оценке финального ответа
Классический RL для усиления умения рассуждать (как в DeepSeek‑R1): награда начисляется за правильный итоговый ответ, а не за каждый шаг. - T1 — «готовые» инструменты, которые агент просто вызывает
Все привычные SAM, CLIP и прочие предобученные модели: они не подстраиваются под конкретного агента, а работают как универсальные модули. - T2 — инструменты учатся по сигналу от агента
Агент остаётся замороженным, а дообучаются вспомогательные под‑агенты/сервисы, чтобы лучше под него «подстроиться» — получается своеобразная симбиоз‑адаптация.
Такое разложение помогает:
- целенаправленно выбирать стратегию:
нужно улучшить умение пользоваться инструментом — смотрим в A1/T2;
хотим прокачать общую логику — A2;
ищем максимально универсальные модули — T1. - понимать компромиссы:
изменение самого LLM (A1/A2) гибко, но дорого (ресурсоёмкое обучение);
адаптация инструментов (T1/T2) дешевле, но ограничена исходными возможностями базовой модели.
Почему T2 часто выгоднее, чем «чистый RL по агенту»
Важное эмпирическое наблюдение из работы: T2‑подход может быть куда эффективнее, чем A2.
На задаче поиск+Генерация (RAG):
- A2‑подход (Search‑R1):
требуется ~170 000 примеров для end‑to‑end RL по агенту. - T2‑подход:
базовая модель заморожена, дообучается небольшой поисковый под‑агент;
достаточно ~2400 примеров — в 70 раз меньше;
обучение — в 33 раза быстрее, при этом качество сопоставимо или выше.
На медицинских вопросах T2‑система показала 76,6% точности против 71,8% у A2. Объяснение простое: A2 заставляет модель одновременно учить три вещи — доменную экспертизу, использование инструмента и логику решения задачи. Пространство оптимизации взрывается. В T2‑режиме крупная LLM уже умеет «знать и рассуждать», а маленький модуль доучивает лишь одно — «как правильно искать».
Четыре направления, без которых агенты останутся «демо‑игрушками»
Авторы выделяют четыре фронтира, от которых зависит, станут ли агенты реально полезными.
- Совместная адаптация (Co‑Adaptation)
Идеальный сценарий — когда и агент, и инструменты одновременно подстраиваются друг под друга в одном цикле обучения. Но это рождает проблему кредитного распределения: если задача провалена, кто виноват — ядро‑агент, поисковый модуль или, скажем, планировщик? Без решения этой задачи сложно строить устойчивые системы. - Непрерывная адаптация (Continual Adaptation)
Реальный мир нестабилен:
- меняются API и форматы данных,
- обновляются инструменты,
- эволюционируют запросы пользователей.
Нужны агенты, которые умеют учиться на ходу, не забывая старое, то есть решать проблему катастрофического забывания в динамичной среде, а не на статичном датасете.
- Безопасная адаптация (Safe Adaptation)
Один из тревожных выводов: усиливая модели через RL по рассуждениям, мы можем подрывать ранее встроенные меры безопасности. Модель начинает придумывать сложные логические «обоснования» для вредоносного поведения и становится более уязвимой к джейлбрейкам. Значит, адаптация должна проектироваться так, чтобы безопасность не размывалась, а усиливалась. - Эффективная адаптация (Efficient Adaptation)
В условиях ограниченных ресурсов (облако с лимитами, edge‑устройства, локальные инсталляции) критичны:
- лёгкие методы дообучения (LoRA в RL‑настройке),
- оптимизации наподобие FlashRL,
- компактные персонализированные модели на клиенте.
Без этого агенты останутся привилегией крупных центров обработки данных и так и не дойдут до массовой практики.
Что это даёт разработчикам агентов
Практический вывод обзора: провалы агентов в проде — не случайность, а следствие отсутствия системного подхода к адаптивности. Вместо бесконечных демо с жёстко прописанными сценариями стоит:
- осознанно выбирать парадигму (A1/A2/T1/T2) под конкретную задачу и ограничения,
- минимизировать переобучение базовой LLM там, где можно обойтись настройкой инструментов,
- сразу проектировать системы для непрерывного, безопасного и эффективного дообучения.
Иначе агент так и останется «драконом на демо и червём в бою» — впечатляющим в презентации и беспомощным в настоящей, изменчивой среде.
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
ИИ сегодня — ваше конкурентное преимущество завтра!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru
Сайт https://www.smssystems.ru/razrabotka-ai/