Привет, друзья! На связи Денис Куров. На своем канале «AI по Фейнману» я разбираюсь в сложных AI-темах, чтобы вы могли применять их в бизнесе и IT.
Сегодня мы поговорим о наболевшем: почему так много AI-проектов застревают на стадии прототипа и никогда не доходят до реальных пользователей? Несмотря на бум в разработке и доступность мощных LLM, лишь малая часть проектов приносит значимую коммерческую выгоду. В чем же дело?
Проблема в том, что разработка на основе LLM кардинально отличается от традиционного программирования. Инженеры сталкиваются с непредсказуемым, стохастическим поведением моделей, где привычные тесты не работают. Как оценить качество, когда результат меняется от запуска к запуску? Как гарантировать, что улучшение в одном сценарии не сломает десять других?
Ответ кроется в смене парадигмы. Вместо хаотичных итераций и субъективных оценок («кажется, стало лучше») нам нужен инженерный подход, заимствованный из лучших практик разработки ПО. Этот подход называется Eval-Driven Development (EDD), или разработка на основе оценок (Evals).
EDD превращает создание AI-систем из искусства в науку. Это практическое, end-to-end руководство о том, как использовать EDD в качестве основного процесса при создании AI-системы production уровня. Мы пройдем по реалистичному сценарию: от идеи до развертывания системы, которая заменяет трудоемкий ручной процесс.
Парадигма Eval-Driven Development (EDD)
Eval-Driven Development (EDD) — это методология разработки AI-систем, которая зеркально отражает принципы Test-Driven Development (TDD) из классической инженерии ПО. Главный сдвиг — фокус смещается с немедленного построения модели на предварительное определение, проектирование и автоматизацию оценок (evals).
Проще говоря: прежде чем написать строчку кода для модели, мы определяем, как будем измерять её успех.
Это не просто тесты, а полноценный фреймворк, который становится ядром всего жизненного цикла разработки.
Ключевые принципы EDD
- Принцип "Сначала оценка" (Evaluation-First Mindset). Сначала пишутся сценарии оценки и критерии успеха. Например, мы заранее определяем, что система распознавания инвойсов должна достичь точности >95% на ключевых полях (сумма, дата, поставщик).
- Автоматизированное и инкрементальное тестирование. Метрики (точность, полнота, F1-score, задержка) вычисляются автоматически в рамках CI/CD пайплайна. Каждое изменение в коде или промпте должно проходить полный набор эвалов, чтобы мгновенно выявлять регрессии.
- Согласование с целями бизнеса (Stakeholder Alignment). Метрики разрабатываются совместно с экспертами (в нашем случае — бухгалтерами) и бизнесом. Вместо абстрактной «точности» мы измеряем «стоимость ошибок в долларах», напрямую связывая технические показатели с ROI.
- Итеративное улучшение. При обнаружении новых ошибок или пограничных случаев мы не просто исправляем систему, а сначала расширяем набор эвалов, чтобы зафиксировать этот новый сценарий. Это гарантирует, что проблема не вернется в будущем.
- Прозрачность и воспроизводимость. Весь код эвалов, наборы данных и определения метрик хранятся в системе контроля версий вместе с кодом модели. Это обеспечивает воспроизводимость результатов и возможность аудита любого решения.
Критерии качественного набора оценок (Eval Set)
Чтобы эвалы действительно были полезны, они должны отвечать пяти ключевым критериям:
- Реалистичность. Evals должны точно отражать реальные производственные сценарии и данные, с которыми столкнется система.
- Согласованность с человеком. Результаты автоматических метрик должны коррелировать с оценкой качества, которую дал бы человек-эксперт.
- Всесторонность (Eval Coverage). Набор должен покрывать широкий спектр сценариев: не только «счастливые пути», но и критические пограничные случаи, которые могут привести к значительным проблемам.
- Воспроизводимость. При неизменной системе повторный запуск эвалов должен давать стабильные результаты, позволяя надежно отслеживать прогресс.
- Секретность. Модель не должна обучаться на данных для оценки. Это предотвращает "подгонку" под тесты и гарантирует, что модель действительно обладает нужным уровнем обобщения.
Приняв эту парадигму, вы переходите от метода «научного тыка» к управляемому, итеративному улучшению от прототипа до продакшена.
Практическое руководство: Создание системы анализа инвойсов
Практическое руководство: Создание системы анализа инвойсов
Мы пройдем по реалистичному сценарию: создадим систему для автоматического анализа инвойсов, заменив ручной труд бухгалтерии.
Хотите сразу перейти к коду? Весь код из этой статьи доступен в Google Collab, где вы можете экспериментировать с ним вживую.
Этот кейс основан на типичном процессе обработки входящих счетов (invoices) в средней компании, такой как розничная сеть или производственное предприятие, где бухгалтерия ежедневно сталкивается с сотнями документов от поставщиков. Автоматизация позволит сократить время на обработку с часов до минут, минимизировать ошибки и повысить compliance с налоговым законодательством.
Наш бизнес-кейс: Автоматизация обработки счетов-фактур
Чтобы наш проект был максимально приближен к реальности, давайте подробно разберем бизнес-процесс, который мы собираемся автоматизировать.
Текущий процесс: Ручная работа и её цена
Представьте себе отдел бухгалтерии средней компании. Каждый день сюда стекаются от 50 до 200 счетов (инвойсов) от разных поставщиков — по почте, в виде PDF-файлов на email или сканов в общей папке.
Шаг 1: Сбор и первичная обработка
Сотрудник (бухгалтер или менеджер) собирает все эти документы, сканирует бумажные версии и загружает их в единую систему. Уже на этом этапе возникает путаница.
Шаг 2: Ручное извлечение данных
Далее начинается самая трудоемкая часть. Бухгалтер открывает каждый документ и, как детектив, выискивает ключевую информацию, вручную перепечатывая её в учетную систему (например, 1С или SAP):
- Идентификаторы: Номер и дата инвойса.
- Контрагенты: Названия и налоговые номера продавца и покупателя.
- Содержание: Каждая строка товара или услуги, количество, цена.
- Финансы: Итоговые суммы (без НДС, с НДС), условия и сроки оплаты.
На один документ уходит от 5 до 15 минут. Сложные инвойсы с десятками позиций могут "съесть" и полчаса.
Шаг 3: Проверка и аудит ("Четыре глаза")
После ввода данных начинается проверка. Бухгалтер должен:
- Проверить арифметику: Убедиться, что количество × цена + НДС сходится с итоговой суммой.
- Проверить на полноту: Есть ли номер, дата и данные поставщика? Если чего-то нет, инвойс отправляется на ручной аудит.
- Применить бизнес-правила: Если сумма счета превышает $1000, он автоматически уходит на дополнительную проверку старшему бухгалтеру.
Проблемные места: Где процесс даёт сбой
Эта система работала годами, но с ростом бизнеса она стала "бутылочным горлышком".
- Человеческий фактор: Перегрузка и ошибки. В конце месяца, когда счетов особенно много, бухгалтеры работают на пределе. Это приводит к ошибкам:
Пропущенный аудит (False Negative): Самая дорогая ошибка. Около 3% проблемных счетов проходят незамеченными. Это может привести к переплате поставщику или налоговым штрафам на сумму $30–$100 за каждый такой случай.
Стоимость ручного труда: Обработка одного инвойса обходится компании в $0.20–$0.50 с учетом зарплаты и времени сотрудника. - Ловушка роста: Процесс не масштабируется. Если количество счетов вырастет на 50%, компании придется нанять еще 2-3 бухгалтеров. Это дополнительные $100,000+ в год на фонд оплаты труда, что делает рост бизнеса неэффективным.
- Задержки в оплате. Ручная обработка занимает 1–3 дня. Это может приводить к просрочке платежей и потере скидок за быструю оплату.
Цель автоматизации: От ручного труда к умной системе
Наша миссия — создать AI-ассистента, который возьмет на себя 80-90% рутинной работы.
- Автоматическое извлечение: Система должна "читать" изображения и PDF, извлекая все нужные данные в структурированном виде.
- Интеллектуальная валидация: Система будет автоматически проверять арифметику и применять бизнес-правила (например, проверять сумму > $1000).
- Умная эскалация: Более 95% "чистых" инвойсов должны обрабатываться автоматически. И только менее 5% сложных или подозрительных случаев будут направляться человеку на проверку, причем система сама подсветит, на что обратить внимание.
Критерии успеха: Как мы поймём, что победили?
Именно здесь теория Evals соединяется с практикой. Мы будем измерять успех на двух уровнях:
- Технические метрики (для команды разработки):
Точность извлечения данных > 95% (F1-score): Насколько правильно система распознает номера, даты и суммы.
Полнота обнаружения аудитов > 98% (Recall): Насколько хорошо система находит все инвойсы, которые требуют проверки. Пропустить проблемный счет гораздо хуже, чем зря отправить на проверку хороший.
Скорость обработки < 5 секунд на документ. - Бизнес-метрики (для стейкхолдеров):
Стоимость обработки < $0.05 за инвойс.
Окупаемость инвестиций (ROI) > 200% в первый год.
Доля ручной работы < 10% от общего потока.
Жизненный цикл нашего проекта
Не каждый проект протекает одинаково, но у большинства есть общие компоненты. Наш процесс будет итеративным, где каждый цикл уточняет наше понимание задачи и улучшает систему.
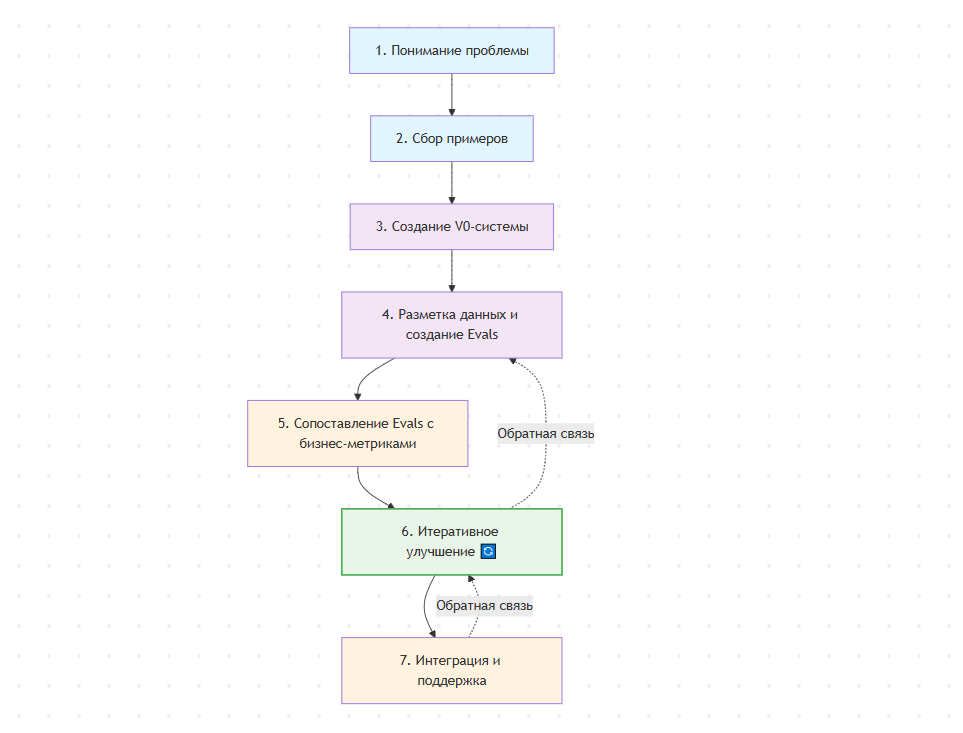
- Понимание проблемы: Начинаем с опроса экспертов (бухгалтеров), чтобы понять их текущий процесс и критерии принятия решений. Этот этап непрерывен — новые детали будут всплывать на протяжении всего проекта.
- Сбор примеров: Находим и подготавливаем данные. Мы начнем с небольшого, но репрезентативного набора изображений инвойсов.
- Создание V0-системы: Быстро строим "скелет" системы, который принимает нужные входные данные (изображения) и выдает результат в правильном формате, даже если он пока неточный.
- Разметка данных и создание Evals: Используем V0-систему для "черновой" разметки. Затем эксперты исправляют эти данные, и на основе их правок мы создаем первые оценочные наборы (evals).
- Сопоставление Evals с бизнес-метриками: Строим модель затрат, чтобы понять, какие ошибки системы стоят компании дороже всего. Это поможет сфокусировать усилия на самом важном.
- Итеративное улучшение: Используем результаты evals для улучшения системы (промпты, модели) и самих evals (добавление новых кейсов).
- Интеграция и поддержка: Внедряем систему в реальный рабочий процесс и настраиваем сбор данных из продакшена для постоянного мониторинга и улучшения.
Часть 1: Постановка задачи и создание V0-системы
Для нашего проекта мы будем использовать изображения из открытого датасета katanaml-org/invoices-donut-data-v1, опубликованного на Hugging Face под лицензией Apache 2.0. Этот набор содержит разнообразные примеры счетов, что идеально подходит для демонстрации нашего подхода. Мы добавим свои собственные метки, чтобы рассказать историю на небольшом количестве примеров.
V0: Строим первую версию системы
На практике мы бы создали систему на базе REST API с веб-интерфейсом. Но для простоты мы сведем все к двум Python-функциям:
- extract_invoice_details: Принимает изображение инвойса и извлекает из него структурированную информацию.
- evaluate_invoice_for_audit: Принимает извлеченные данные и решает, нужен ли инвойсу аудит.
Такое разделение на шаги упрощает разработку и отладку. Однако есть и минус: информация может теряться на каждом этапе, как в игре в «испорченный телефон». В этой статье мы намеренно разделяем шаги, чтобы сделать процесс оценки более наглядным.
Настройка окружения и API
Мы будем использовать модели через OpenRouter, который предоставляет доступ к различным LLM через единый API.
Как получить API-ключ OpenRouter:
Зарегистрируйтесь на сайте openrouter.ai.
Перейдите в раздел "Keys" в вашем аккаунте.
Создайте новый ключ (Create Key).
Скопируйте полученный ключ. В коде ниже мы вставим его в переменную окружения. Для безопасности в реальных проектах используйте менеджеры секретов (например, переменные окружения .env или секреты в Google Colab).
Блок 1: Импорты и настройка окружения
Это наш стартовый набор инструментов.
- os, pathlib, mimetypes, base64: Стандартные Python-библиотеки для работы с файлами и кодирования данных. base64 нам понадобится, чтобы "превратить" изображение в текст для отправки через API.
- json: для работы с данными в формате JSON, на котором мы будем общаться с моделью.
- typing: для аннотации типов. Делает код чище и понятнее.
- openai: Официальная библиотека от OpenAI для взаимодействия с их API. OpenRouter использует тот же формат, поэтому эта библиотека нам идеально подходит.
- pydantic: Супер-важная библиотека. Она позволяет нам определять строгие схемы данных. Это наш "контракт" с LLM: мы говорим модели, в каком именно формате хотим получить ответ.
- rich: Для красивого вывода в консоль.
- try...except ImportError: Простая проверка, запущен ли код в среде Google Colab. Это позволяет нам адаптировать логику (например, использовать виджет загрузки файлов Colab).
Блок 2: Настройка API и выбор моделей
- OpenRouter: Мы используем openrouter в качестве base_url. OpenRouter — это агрегатор моделей. Он дает доступ к десяткам LLM (от OpenAI, Google, Mistral, Anthropic и др.) через единый API. Это очень удобно для экспериментов: можно легко переключать модели, не меняя код. К тому же, у многих моделей есть бесплатные лимиты (:free), что идеально для прототипирования.
- Выбор моделей: Мы используем две разные модели для двух разных задач. Это ключевое архитектурное решение.
MODEL = "mistralai/mistral-small-3.2-24b-instruct:free" Задача: Извлечение информации из изображения.
Почему эта модель? Это мультимодальная модель (vision model), то есть она умеет "смотреть" на картинки и понимать их содержимое. Нам нужна именно такая модель для первого шага. mistral-small — это хороший компромисс между мощностью, скоростью и стоимостью. Важно: Наша модель должна уметь работать со Structured Output
AUDIT_MODEL = "x-ai/grok-4-fast:free" Задача: Логический анализ уже извлеченных текстовых данных (JSON) и принятие решения об аудите.
Почему эта модель? На втором шаге нам не нужно смотреть на картинку. Нам нужна модель с сильными логическими и "рассуждательными" способностями для анализа структурированных данных. Grok хорошо справляется с такими задачами. Использование отдельной, более дешевой и быстрой текстовой модели для второй задачи — это оптимизация. Мы используем правильный инструмент для каждой работы. Важно: Наша модель должна уметь работать со Structured Output
Блок 3: Модели данных Pydantic
Без Pydantic мы бы просто просили модель: "верни JSON". Но она могла бы вернуть его с ошибками, с другими именами полей, в другой структуре. Это был бы хаос.
Pydantic — это наш гарант порядка.
- Надежность: Мы определяем точную структуру, типы данных (str, bool, List) и даже можем указать, какие поля необязательны (Optional).
- Валидация: Когда мы получаем ответ от LLM, InvoiceDetails.model_validate(details) автоматически проверяет, соответствует ли JSON нашей схеме. Если нет — мы сразу получаем ошибку и можем ее обработать.
- Подсказки для LLM: Современные API (как у OpenAI/OpenRouter) могут использовать схему Pydantic напрямую, чтобы гарантировать, что ответ модели будет в нужном формате (мы увидим это в параметре response_format).
Field(description=...) — это метаинформация. Она не только помогает нам (разработчикам), но и может быть использована для генерации более точных промптов или документации.
Блок 4: Разбор промптов. Инструкции для "мозга" системы
Если Pydantic-модели — это "скелет" нашей системы, то промпты — это ее "мозг" и "инструкции". Именно здесь происходит магия промпт-инжиниринга. Плохой промпт даст вам хаотичный результат, хороший — превратит LLM в исполнительного и точного сотрудника. Давайте посмотрим, почему наши V0-промпты устроены именно так.
Промпт №1: INVOICE_EXTRACTION_PROMPT
Цель этого промпта: Взять на вход изображение и превратить визуальный хаос пикселей в структурированные данные. Мы просим модель (mistral-small в нашем случае) выступить в роли внимательного оператора ввода данных.
Почему он хорош (даже для V0):
- Четкая постановка задачи: Первая строка Given an image... extract... format as a structured response не оставляет места для двусмысленности. Модель сразу понимает свою роль и конечный продукт.
- Структура с заголовками (# и ##): Использование Markdown-заголовков (# Task Description, ## Important Guidelines) разбивает промпт на логические блоки. Это помогает модели лучше понять контекст и приоритеты.
- Конкретика вместо абстракции: Мы не говорим "извлеки все важное". Мы даем исчерпывающий чек-лист в разделе Task Description. Обратите внимание, что этот список (пункты 1-4) почти дословно повторяет структуру нашей Pydantic-модели InvoiceDetails. Это создает мощную связку: промпт говорит что делать, а json_schema говорит, в каком формате это сделать.
- Обработка несовершенств реального мира: Строка If information is unclear or missing, return null for that field — это ключевая инструкция для работы с реальными документами. Мы заранее учим модель не выдумывать данные, а честно признавать их отсутствие.
- Правила форматирования: Указания вроде Format dates as they appear on the invoice и Format all monetary values as they appear очень важны. Мы не хотим, чтобы модель "умничала" и меняла 15/10/2012 на 2012-10-15. На первом этапе нам нужны сырые данные, как они есть. Анализом мы займемся позже.
- Упрощение сложных задач: Инструкция Extract addresses in full_address field — это пример прагматичного подхода. Разбор адресов на город, штат, индекс — сложная задача. Для первой версии мы упрощаем ее для модели, прося просто извлечь адрес целиком. Это повышает надежность.
Промпт №2: INVOICE_AUDIT_PROMPT — «Мозг» Системы
Цель этого промпта: Взять на вход структурированные текстовые данные (JSON) и выступить в роли внутреннего аудитора. Здесь не нужно зрение, здесь нужна логика, внимание к деталям и умение следовать правилам.
Почему он настолько эффективен:
- Ролевая игра: С самого начала мы задаем роль — "Оцени данные... определи, нужен ли аудит". Модель (Grok в нашем случае) понимает, что от нее требуется не извлечение, а суждение.
- Жесткие, как гвозди, правила: Пять пронумерованных критериев — это не рекомендации, это закон. Использование UPPERCASE для названий правил (AMOUNT_OVER_LIMIT) помогает модели сфокусироваться на них как на ключевых сущностях.
- Декомпозиция сложной задачи (MATH_ERROR): Это шедевр промпт-инжиниринга. Вместо того чтобы сказать "проверь математику", мы даем модели пошаговый алгоритм:Проверь каждую строку.
Проверь сложение итогов.
Проверь сложение итогов с НДС.
Это разбивает одну сложную задачу на несколько простых и значительно повышает точность. - Прагматичность и знание предметной области: Инструкция Allow for rounding differences up to $0.02. В финансах часто возникают погрешности округления. Без этого правила система бы ложно срабатывала на каждом втором инвойсе.
- Требование «Показать работу»: Фразы For each criterion, determine if it is violated (true) or not (false) и Provide your reasoning заставляют модель не просто выдать итоговое needs_audit: true/false, а объяснить, как она пришла к этому выводу. Это бесценно для отладки и для доверия к системе со стороны бизнес-пользователей.
- Финальная логика агрегации: Предложение An invoice needs auditing if ANY of the criteria are violated — это вишенка на торте. Оно четко определяет финальное правило: если хотя бы один флаг true, то итоговое решение тоже true. Это логическая операция OR, описанная простым языком.
Таким образом, эти два промпта — это не просто текст, а тщательно спроектированные алгоритмы для LLM. Они являются основой нашего V0-прототипа и отличной стартовой точкой для дальнейших итераций и улучшений.
Блок 5: Основные функции
extract_invoice_details
- Кодирование изображения: Компьютер не может отправить "картинку" по сети в ее сыром виде через JSON. Мы читаем файл в байтах, кодируем его в base64 (безопасный текстовый формат) и формируем data URL. Это стандартный способ передачи изображений в веб-запросах.
- Вызов API (client.chat.completions.create): model=model: Используем нашу vision-модель (mistral-small).
messages: Это список сообщений. Для мультимодальных моделей content сам является списком, где мы передаем и текст (наш промпт), и изображение (image_url). - response_format: Ключевой параметр! "type": "json_schema" говорит модели, что мы ждем от нее JSON, который соответствует определенной схеме.
"schema": InvoiceDetails.model_json_schema(): Здесь мы передаем схему, которую Pydantic сгенерировал из нашего класса InvoiceDetails. Модель будет изо всех сил стараться вернуть JSON, который пройдет валидацию по этой схеме.
"strict": True: Этот режим заставляет модель быть еще более точной в следовании схеме.
temperature=0.1: Мы ставим низкую "температуру", чтобы ответы были более предсказуемыми и менее "творческими". Для задач извлечения фактов это то, что нужно. - Парсинг и валидация: Получаем текстовый ответ (content), превращаем его из строки JSON в Python-словарь (json.loads) и, наконец, пропускаем через InvoiceDetails.model_validate, чтобы убедиться, что все на месте.
Обработка ошибок (try...except): Блок fallback пытается сделать тот же запрос, но с более простым response_format={"type": "json_object"}. Это полезно, если основная модель или json_schema режим по какой-то причине не сработали. Это делает наш код более устойчивым к сбоям.
evaluate_invoice_for_audit
Если extract_invoice_details была нашими "глазами", то evaluate_invoice_for_audit — это наш "мозг" и "судья". Функция берет структурированные данные, которые мы уже извлекли, и применяет к ним железную логику правил, описанных в промпте. Это чисто аналитическая работа.
Давайте пошагово разберем, как она это делает.
Разбор "шапки" функции:
- invoice_details: InvoiceDetails: Это входной параметр. Обратите внимание на тип данных — InvoiceDetails. Это не просто какой-то словарь, это Pydantic-объект, который уже прошел валидацию на предыдущем шаге. Мы точно знаем, что у него есть поля invoice_number, total_gross_worth и т.д. Это делает наш код предсказуемым и надежным.
- model: str = AUDIT_MODEL: Мы передаем имя модели, которую будем использовать. По умолчанию это AUDIT_MODEL (x-ai/grok-4-fast), но мы можем легко подменить ее для экспериментов.
- -> InvoiceAuditDecision: Это аннотация возвращаемого значения. Функция обещает вернуть объект типа InvoiceAuditDecision. Это наш контракт. Если она вернет что-то другое, инструменты проверки типов сразу сообщат об ошибке.
Теперь к самому интересному — к "телу" функции.
- Ключевой момент: Здесь мы комбинируем наш промпт-инструкцию (INVOICE_AUDIT_PROMPT) с конкретными данными (invoice_json). Мы буквально говорим модели: "Вот правила игры, а вот игровые фигуры. Начинай анализ".
- response_format={"type": "json_schema", ...}: Это самый надежный способ получить структурированный ответ. Мы отдаем модели точную схему нашей Pydantic-модели InvoiceAuditDecision. Это заставляет модель вернуть JSON, который на 100% соответствует нашему формату.
- temperature=0.1: Для аналитической задачи нам не нужно творчество. Нам нужна точность и предсказуемость. Низкая температура гарантирует, что модель будет следовать инструкциям максимально буквально.
V0-система в действии: Первый полет и анализ результатов
Итак, мы собрали наш конвейер и нажали кнопку "Старт". В Google Colab мы загрузили тестовый инвойс image.jpg.
Шаг 1: Результат extract_invoice_details
Система отработала, и мы получили два JSON-ответа и итоговый вердикт. Давайте разберем этот результат более подробно.
Что мы видим?
Модель-экстрактор (mistral-small) выступила как старательный, но немного невнимательный стажер.
- Хорошо: Она правильно определила номер и дату инвойса, имя продавца и его налоговый номер. Числовые данные (цена, количество, итоги) также извлечены верно. Адреса, как мы и просили в промпте, были записаны в поле full_address.
- Плохо: Модель полностью пропустила три важных поля:
Имя клиента (client: null).
Налоговый номер клиента (client_tax_id: null).
Описание товара в строке (description: null).
Это классическая ошибка OCR/извлечения на V0-системе. Мы получили частично верные данные.
А вот здесь начинается самое интересное!
Модель-аудитор (Grok) получила на вход неполные данные с предыдущего шага и вынесла свой вердикт.
- Рассуждения (reasoning): Модель совершенно логично рассуждает: сумма меньше $1000, номер и дата есть, математика сходится (на тех данных, что есть!).
- Итоговое решение: На основе своего анализа модель приходит к выводу, что аудит не нужен (needs_audit: false).
Ключевой вывод: Модель-аудитор сработала идеально в рамках предоставленной ей информации! Проблема не в ее логике. Проблема в том, что она работала с "грязными" данными.
Сравнение с эталоном (Ground Truth)
Результаты сравнения
Поле: client
Результат нашей V0-системы: null
Эталон (Ground Truth): "Jackson, Odonnell and Jackson..."
Анализ: ❌ Критическая ошибка
Поле: client_tax_id
Результат нашей V0-системы: null
Эталон (Ground Truth): "998-87-7723"
Анализ: ❌ Критическая ошибка
Поле: items[0].description
Результат нашей V0-системы: null
Эталон (Ground Truth): "Leed's Wine Companion..."
Анализ: ❌ Критическая ошибка
Поле: invoice_number
Результат нашей V0-системы: "40378170"
Эталон (Ground Truth): "40378170"
Анализ: ✅ Успех
Поле: total_gross_worth
Результат нашей V0-системы: "$8,25"
Эталон (Ground Truth): "$8,25"
Анализ: ✅ Успех
Поле: seller
Результат нашей V0-системы: "Patel, Thompson and Montgomery"
Эталон (Ground Truth): "Patel, ... New James, MA 46228"
Анализ: ⚠️ Структурное различие
Анализ сравнения:
- Критические ошибки: Мы не смогли извлечь информацию о клиенте и описание товара. В реальном бизнес-процессе это могло бы привести к серьезным проблемам (например, если бы мы были обязаны проверять client_tax_id).
- Структурное различие: Наша модель правильно разделила имя продавца и его адрес на разные поля (seller и seller_location), в то время как в эталоне они склеены в одно поле. Это не ошибка контента, а разница в подходе к структурированию, которую нужно будет учесть при создании наших автоматических эвалов.
Итог первого полета
Этот простой тест на одном инвойсе вскрыл главную проблему многослойных AI-систем: ошибки каскадом распространяются вниз. Ошибка на этапе извлечения привела к формально правильному, но по сути неверному решению на этапе аудита.
Мы только что получили свою первую, абсолютно конкретную и измеримую точку для улучшения: "система не извлекает информацию о клиенте и описание товара". Это больше не субъективное "кажется, работает не очень", а четкая инженерная задача.
Теперь, вооружившись этим знанием, мы готовы перейти к следующему шагу: созданию автоматизированного набора оценок (Evals), который позволит нам отслеживать такие ошибки на десятках и сотнях примеров, и итеративно улучшать нашу систему. Об этом — в следующей части