Индексация – это процесс, при котором поисковая система заносит страницы сайта в свою базу. Только после этого страницы могут появляться в поисковой выдаче. Если страница не проиндексирована – для Google ее как будто не существует. А теперь представьте, что из индекса выпадают ВСЕ страницы сайта.
Именно с такой критической ситуацией мы столкнулись, работая над поисковым продвижением сайта образовательной платформы одного из крупнейших производителей алюминия. Разбираемся, почему это произошло, как восстановили видимость сайта и какие выводы сделали.

Полное обнуление в поиске
С середины марта 2025 года Google начал исключать из индекса страницы сайта, реализованного с помощью JS-фреймворка React.
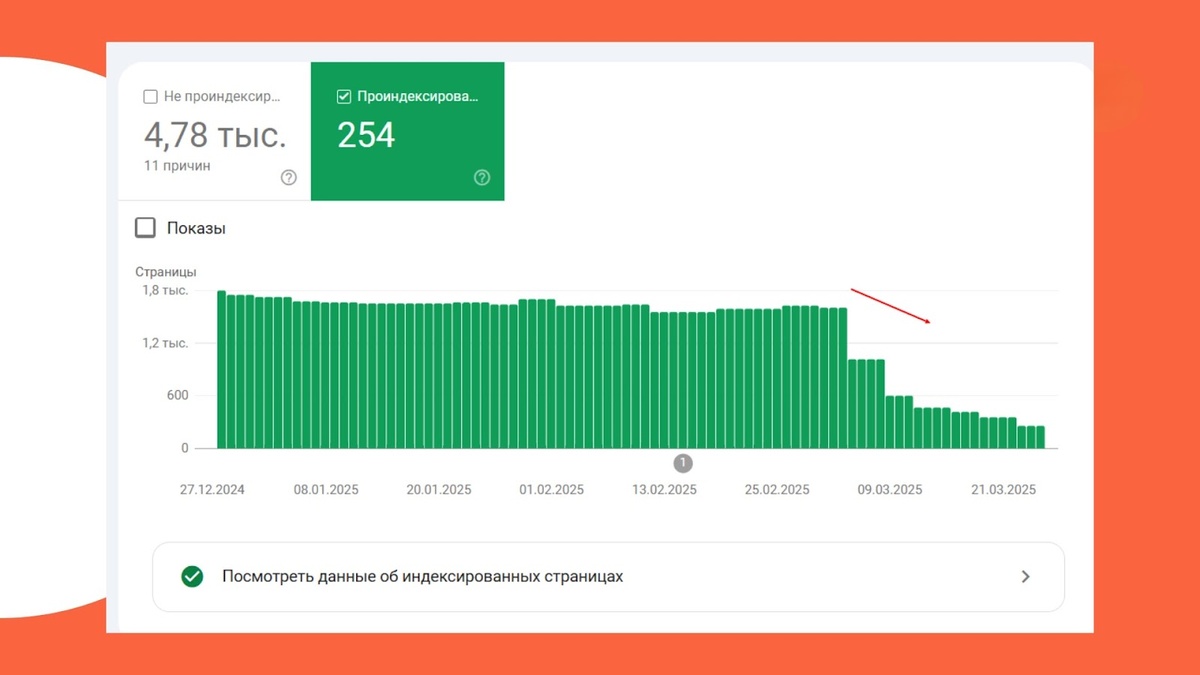
Уже к началу апреля ни одна страница сайта, включая главную, не индексировалась в Google.
Отметим, что проблема затронула только Google, индексация в Яндексе осуществлялась без нареканий. Вот что показал технический аудит:
- все страницы открываются нормально – сервер отвечает кодом 200 OK, то есть страницы доступны и загружаются без ошибок;
- Google видит контент – через Search Console выяснили, что страницы доступны и отображаются корректно;
- есть серверный рендеринг (SSR) – поисковики получают полные HTML-версии страниц, а не только «пустую оболочку» без контента;
- правильные canonical-ссылки – на всех страницах указано, какая версия считается основной;
- нет запретов на индексацию – в метатегах robots не стоит запрет на сканирование;
- файл robots.txt не мешает – он запрещает только дублирующие страницы с параметрами, а не основные.
То есть все страницы были технически доступны, но при этом Google их не индексировал.
Проверили сайт под микроскопом
Мы решили провести детальную проверку и выдвинули несколько предположений, почему сайт не индексируется в Google.
- Ответ сервера 403 или другой блокирующий код.
Предположение: если сервер возвращает код 403 Forbidden, Googlebot не сможет просканировать страницу.
Проверка: страницы доступны для всех поисковых ботов, включая Googlebot, и возвращают код ответа 200 OK.
Вывод: серверные ответы корректны, блокировки по статус-кодам отсутствуют.
- Защита на стороне сервера (WAF или антибот-защита).
Предположение: некоторые серверы или CDN (например, Cloudflare) могут блокировать автоматических ботов (включая Googlebot), если они подозрительно выглядят или не проходят проверку. Особенно часто это делают веб-файрволы (WAF), если сайт защищен.
Проверка: на сайте действительно установлена защита, ограничивающая доступ из некоторых стран. Однако обращения от Googlebot из любых регионов успешно проходят, блокировки не зафиксированы.
Вывод: защитные механизмы не препятствуют доступу Googlebot к сайту.
- Некорректный пустой < meta name="robots"/ >.
Предположение: на страницах сайта присутствует < meta name="robots"/ > без корректного значения атрибута content. В некоторых случаях поисковые системы могут интерпретировать некорректные или пустые значения как noindex.
В нашем случае было зафиксировано:
{"name":"robots","content":"$undefined"}
Такое значение может быть интерпретировано Googlebot как отсутствие инструкции либо как запрет на индексацию.
Проверка: протестировано, метатеги robots устранены, значения content="$undefined" убраны.
Вывод: в этом случае наличие content="$undefined" в метатеге robots не оказывает влияния на сканирование и индексацию со стороны Googlebot.
- Избыточный вес страниц.
Предположение: страницы (например, главная) могли стать слишком «тяжелыми» за счет большого объема CSS, JavaScript и неоптимизированных изображений. Это потенциально влияет на рендеринг: Googlebot имеет ограничения по ресурсам и времени обработки, и при перегрузке скриптами он может не успевать добраться до основного HTML-контента, особенно на React-проектах.
Также учитывалась вероятность несовместимости с обновленной версией React, которая могла случайно добавить лишний код или нарушить SSR.
Проверка: структура бандла не изменилась, новые библиотеки не добавлялись, размер CSS и JS файлов оставался стабильным. Вес страниц не имел значительного увеличения.
Вывод: производительность и вес страниц не изменились, проблем с рендерингом и индексацией по этой причине не выявлено.
Скрытая ошибка, которую мы все-таки нашли
Основную причину выпадения страниц из индекса мы обнаружили спустя пару недель. Кто же был «виновником» торжества?