Pusa-VidGen
Исследователи представили Pusa — модель диффузии для генерации видео, которая использует подход с векторизованными временными шагами вместо традиционных скалярных.
🔘Что такое Pusa?
Pusa (от китайского "Тысячерукая Гуаньинь") — это парадигмальный сдвиг в моделировании видео-диффузии через покадровый контроль шума с векторизованными временными шагами.
🔘Впечатляющие результаты Pusa V1.0
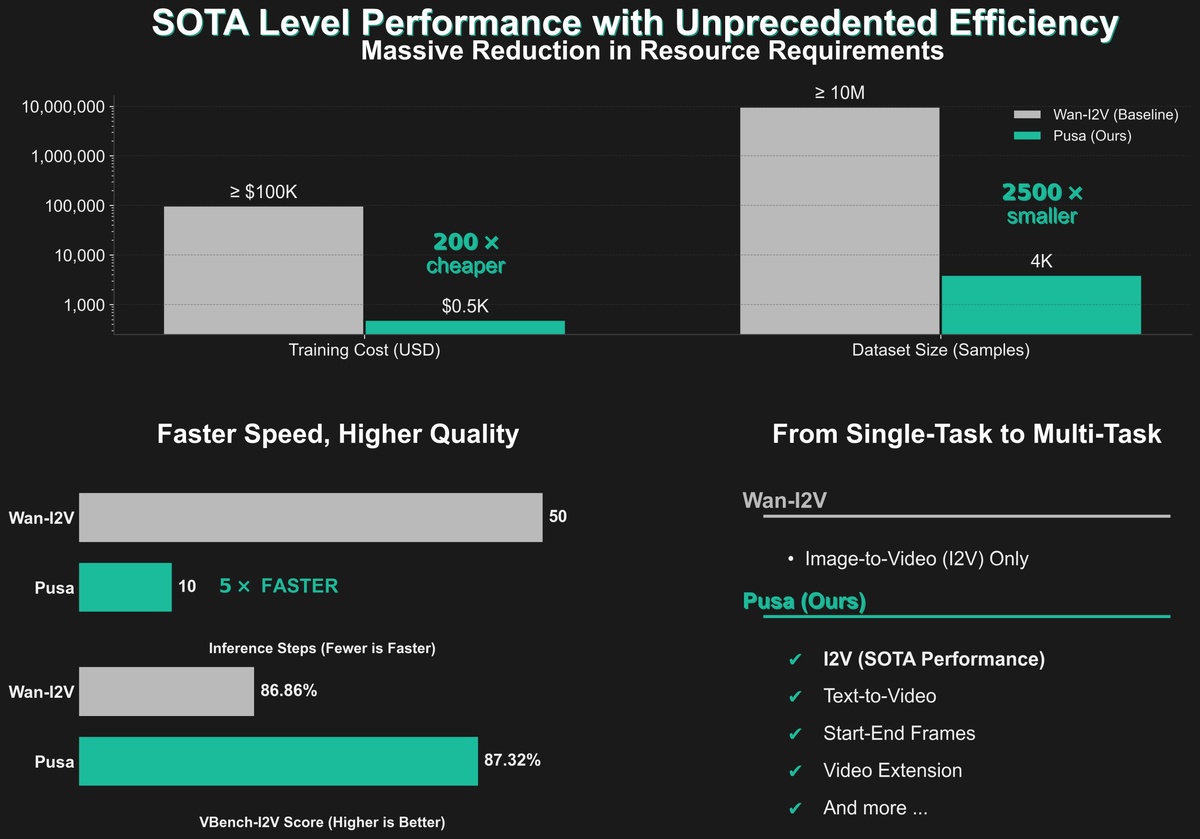
Эффективность:
- Превосходит Wan-I2V-14B при 1/200 стоимости обучения ($500 против $100,000)
- Обучается на датасете в 1/2500 раз меньше (4K против 10M образцов)
- Достигает VBench-I2V score 87.32% (против 86.86% у Wan-I2V-14B)
🔘Ключевые возможности
Мультизадачность
- Text-to-Video — генерация видео из текста
- Image-to-Video — анимация статичных изображений
- Start-End Frames — создание видео между ключевыми кадрами
- Video Extension — продление существующих видео
- Video Transition — плавные переходы между роликами
🔘Архитектура
Vectorized Timestep Adaptation (VTA):
- Покадровый контроль шума
- Неразрушительная модификация базовой модели
- Сохранение всех возможностей оригинальной T2V модели
🔘Примеры использования
Генерация Image-to-Video
python ./demos/cli_test_ti2v_release.py \
--model_dir "/path/to/Pusa-V0.5" \
--prompt "The camera remains still, the man is surfing" \
--image_dir "./input.jpg" \
--num_steps 30
Мульти-кадровая генерация
python ./demos/cli_test_multi_frames_release.py \
--prompt "Drone view of waves crashing" \
--multi_cond '{"0": ["start.jpg", 0.3], "20": ["end.jpg", 0.7]}'
🔘 Доступные версии
Pusa V1.0 (на базе Wan-T2V-14B)
✅Полный открытый исходный код
✅LoRA веса модели и датасет
✅Технический отчет
✅Скрипты обучения и инференса
Pusa V0.5 (на базе Mochi)
✅Inference скрипты для всех задач
✅Код полного fine-tuning
✅Обучающий датасет
🔘Что делает Pusa особенной?
1. Новая парадигма диффузии с векторизованными временными шагами
2. Универсальная применимость к другим SOTA моделям (Hunyuan Video, Wan2.1)
3. Неразрушительная адаптация — сохраняет все возможности базовой модели
4. Открытость — полный код, веса и датасеты доступны
📚 Научная основа
Pusa основана на исследовании FVDM, которое впервые представило концепцию покадрового контроля шума с векторизованными временными шагами.
🔗Полезные ссылки: