В последние годы большие языковые модели (LLM) поражают своими возможностями, но их высокая стоимость и задержки при выводе остаются серьёзным ограничением. Исследователи из Университета Эмори предложили новый подход — SpeedupLLM, который впервые системно доказал: LLM действительно могут становиться быстрее и эффективнее по мере накопления опыта, как и человек.
Как сделать LLM «более опытными»?
В человеческом обучении навык приходит с практикой: чем больше мы решаем похожие задачи, тем быстрее и точнее справляемся с ними. Например, после десятков тренировок можно собирать кубик Рубика вслепую, а знакомую задачу по математике решить за секунды. Исследователи задались вопросом: могут ли LLM учиться так же?
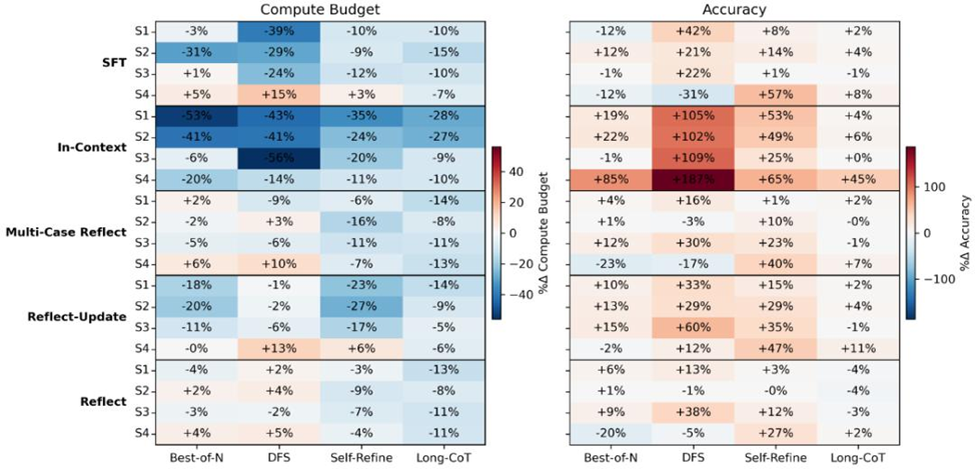
Ответ — да! В работе SpeedupLLM впервые показано, что языковые модели действительно становятся «более опытными»: при повторяющихся или похожих задачах они не только не теряют в качестве, но и существенно ускоряют вывод, снижая вычислительные затраты на 56% и даже повышая точность.
В чём суть SpeedupLLM?
SpeedupLLM — это единый исследовательский фреймворк, который сочетает два ключевых механизма:
- Динамическое распределение вычислительных ресурсов — модель сама решает, сколько ресурсов тратить на знакомые задачи, экономя на повторяющихся сценариях.
- Механизмы памяти — использование различных видов памяти (кэш, in-context, fine-tuning, рефлексия), чтобы ускорять вывод на основе прошлых решений.
Ключевые результаты и открытия
Эксперименты показали:
- Экономия ресурсов: при повторяющихся или похожих задачах LLM может экономить до 56% вычислительных затрат, не теряя в точности, а зачастую даже улучшая её.
- Чем выше схожесть задач, тем сильнее ускорение: для полностью одинаковых или переформулированных вопросов ускорение максимальное, для задач с разной структурой — минимальное.
- Память — не всегда благо: если задачи слишком разные, память может даже мешать, снижая точность и увеличивая расходы.
- Сюжетная память эффективнее рефлексии: методы вроде in-context и supervised fine-tuning дают больший прирост скорости, чем рефлексивные подходы.
- In-Context лучше SFT на малых данных: при небольшом количестве примеров in-context обучение быстрее и точнее.
- Пределы текстовой памяти: in-context и рефлексия быстро достигают потолка из-за ограничений окна контекста, а SFT может накапливать опыт без таких ограничений.
- Обобщающая рефлексия ускоряет лучше: механизмы, которые учат модель абстрагировать правила, а не просто запоминать примеры, дают лучший прирост скорости.
Почему это важно?
SpeedupLLM открывает новую парадигму: ускорять вывод LLM можно не только за счёт железа, но и за счёт накопленного опыта. Это особенно актуально для сфер с повторяющимися задачами — поддержка клиентов, поиск, медицинские консультации и т.д. «Памятливые» LLM смогут работать быстрее, дешевле и точнее, а также лучше адаптироваться под пользователя.
Вывод
Работа SpeedupLLM впервые системно доказала: большие языковые модели действительно могут становиться «быстрее с опытом», как люди. Это не только снижает расходы на вычисления, но и открывает путь к созданию ИИ с настоящей «человеческой» обучаемостью и гибкостью.
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
ИИ сегодня — ваше конкурентное преимущество завтра!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru