Для многих разработчиков будет полезно ознакомиться с тремя важнейшими алгоритмами, которые решают задачи по поиску кратчайших путей.
Немного теории
Графом называется набор вершин, некоторые из которых соединены ребрами. Граф называется связным, если из любой вершины можно достичь любой другой по ребрам графа. Циклом называется путь по ребрам графа, который начинается и заканчивается в одной вершине. Граф считается взвешенным, если каждому ребру сопоставлен вес. Не может быть двух ребер, соединяющих одни и те же вершины.
Каждый из приведенных алгоритмов будет решать задачу по поиску кратчайших путей во взвешенном связном графе. Кратчайший путь между двумя вершинами - это путь, где сумма весов ребер, по которым мы прошли, минимальна.
Для наглядности приведем пример реальной задачи. Предположим, что в стране есть несколько городов и дорог, соединяющих их. Каждая дорога имеет свою длину. Вы хотите добраться из одного города в другой, пройдя минимальное расстояние.
Предположим, что в графе n вершин и m ребер. Все реализации в данной статье написаны на языке Java.
Алгоритм Флойда-Уоршалла
Данный алгоритм вычисляет расстояние от каждой вершины до всех остальных за время, пропорциональное n^3 операциям. При этом веса ребер могут быть отрицательными, однако не допускаются циклы с отрицательной суммой весов (в противном случае можно было бы бесконечно проходить по такому циклу, уменьшая общую сумму, что не представляется интересным).
В массиве d[0… n — 1][0… n — 1] на i-м шаге храним результат исходной задачи, где ограничены вершины, которые мы используем как "пересадочные" в пути, до вершины с номером i-1 (вершины нумеруются с нуля). Предположим, что сейчас выполняется i-я итерация, и нам нужно обновить массив для i + 1-й. Для этого для каждой пары вершин мы пробуем использовать i-1-ю вершину как "пересадочную", и если это улучшает ответ, мы оставляем это изменение. Мы делаем всего n + 1 итераций, и по завершении последней из них мы можем использовать любую вершину в качестве пересадочной, а массив d будет представлять собой итоговый ответ.
Итак, для выполнения этого алгоритма требуется n итераций, в каждой из которых осуществляется n итераций, итого получается порядка n^3 операций.
int[][] g = new int[n][n]; // g[0 ... n - 1][0 ... n - 1] - массив, в котором хранятся веса рёбер, g[i][j] = 1000000000, если ребра между i и j нет
int[][] d = new int[n][n];
for (int i = 0; i < n; i++) {
System.arraycopy(g[i], 0, d[i], 0, n);
}
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
for (int k = 0; k < n; k++) {
if (d[j][k] > d[j][i] + d[i][k]) {
d[j][k] = d[j][i] + d[i][k];
}
}
}
}
// вывод матрицы d
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
System.out.print(d[i][j] + " ");
}
System.out.println();
}
Алгоритм Беллмана-Форда
Этот алгоритм находит расстояние от одной вершины (давайте обозначим ее номером 0) до всех остальных за время, пропорциональное произведению n и m операций. Подобно предыдущему алгоритму, веса ребер могут быть отрицательными, но не допускаются циклы с отрицательной суммой весов.
Мы создаем массив d[0… n — 1], в котором на i-м шаге храним результат исходной задачи с ограничением на число ребер в пути до вершины, которое должно быть меньше i. Если не существует пути до вершины j, то d[j] устанавливается равным 2000000000 (это фиктивная константа, обозначающая "бесконечность"). В начале все значения d заполнены этой константой. Чтобы обновить массив на i-м шаге, мы просто проходим по каждому ребру и пытаемся улучшить расстояние до соединенных с ним вершин. Кратчайшие пути не содержат циклов, поскольку все циклы неотрицательны, и мы можем убрать цикл из пути без ухудшения его длины. Это также помогает нам обнаружить отрицательные циклы в графе: достаточно выполнить дополнительную итерацию и проверить, не улучшилось ли расстояние до какой-либо вершины. Длина кратчайшего пути не превышает n — 1, следовательно, после n-й итерации массив d будет содержать ответ на задачу.
Для выполнения этого алгоритма требуется n итераций по m шагов в каждой, общее количество операций составляет порядка n * m.
int[] d = new int[n];
for (int i = 0; i < n; i++) {
d[i] = 2000000000;
}
d[0] = 0;
for (int i = 1; i <= n; i++) {
for (int j = 0; j < m; j++) {
if (d[e[j].second] > d[e[j].first] + e[j].value) {
d[e[j].second] = d[e[j].first] + e[j].value;
}
if (d[e[j].first] > d[e[j].second] + e[j].value) {
d[e[j].first] = d[e[j].second] + e[j].value;
}
}
}
// вывод массива d
for (int i = 0; i < n; i++) {
System.out.print(d[i] + " ");
}
Алгоритм Дейкстры
Этот алгоритм находит расстояние от вершины с номером 0 до всех остальных за количество операций порядка n^2, предполагая, что все веса ребер неотрицательны.
На каждой итерации определенные вершины помечаются, а другие остаются непомеченными. Для этого используются два массива: mark[0… n — 1], где True означает пометку вершины, а False - отсутствие пометки, и d[0… n — 1], где для каждой вершины хранится длина кратчайшего пути, проходящего только через помеченные вершины как "пересадочные". Гарантируется, что длина пути до помеченных вершин в массиве d и есть искомый ответ. На начальном этапе только вершина 0 помечена, а g[i] равно x, если между 0 и i существует ребро весом x, 2000000000, если ребер нет, и 0, если i = 0.
На каждой итерации выбирается вершина v с наименьшим значением в d среди непомеченных вершин. Значение d[v] становится ответом для вершины v. Это можно доказать следующим образом: предположим, что кратчайший путь от 0 до v проходит не только через помеченные вершины и короче, чем d[v]. Тогда найдем первую непомеченную вершину на этом пути, обозначим ее как u. Длина пути до u равна d[u], но по предположению длина пути до v (len) меньше d[v]. Следовательно, d[v] > len >= d[u], что противоречит тому, что v имеет минимальное значение d[v] среди непомеченных вершин.
После пометки вершины v и пересчета d алгоритм продолжается до тех пор, пока все вершины не будут помечены, и d не станет окончательным ответом.
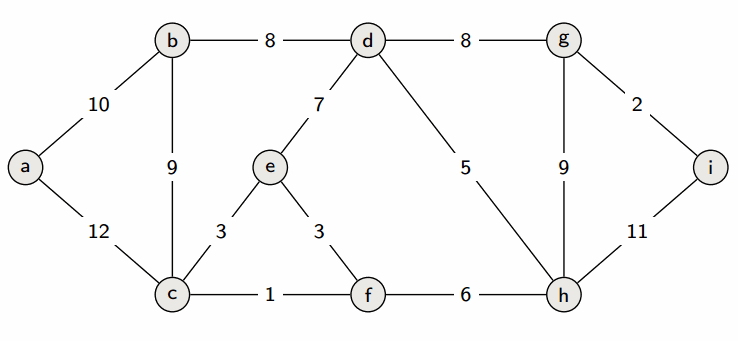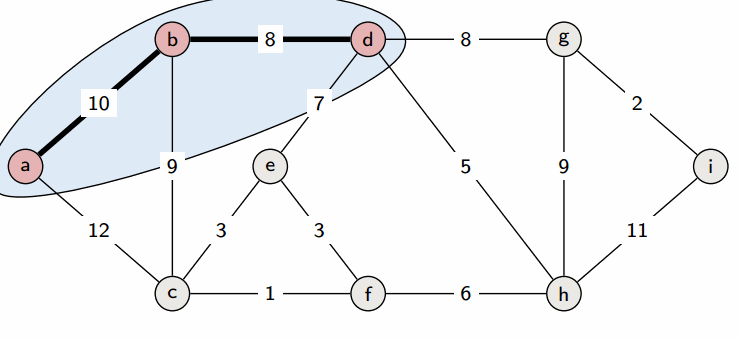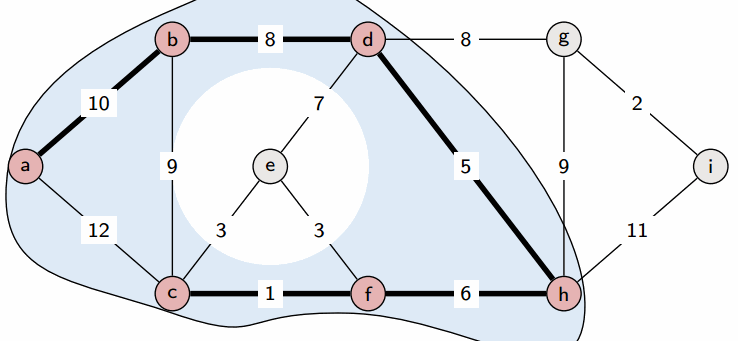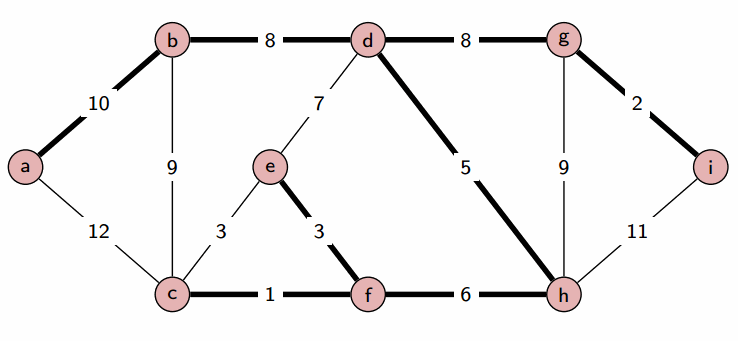
Выполнение этого алгоритма требует n итераций, каждая из которых включает поиск вершины v, что приводит к общему числу операций порядка n^2.
int[][] g = new int[n][n]; // g[0 ... n - 1][0 ... n - 1] - массив, в котором хранятся веса рёбер, g[i][j] = 1000000000, если ребра между i и j нет
int[] d = new int[n];
boolean[] mark = new boolean[n];
for (int i = 0; i < n; i++) {
System.arraycopy(g[i], 0, d, 0, n);
}
d[0] = 0;
mark[0] = true;
for (int i = 1; i < n; i++) {
mark[i] = false;
}
for (int i = 1; i < n; i++) {
int v = -1;
for (int j = 0; j < n; j++) {
if (!mark[j] && (v == -1 || d[v] > d[j])) {
v = j;
}
}
mark[v] = true;
for (int j = 0; j < n; j++) {
if (d[j] > d[v] + g[v][j]) {
d[j] = d[v] + g[v][j];
}
}
}
// вывод массива d
for (int i = 0; i < n; i++) {
System.out.print(d[i] + " ");
}
Для разреженных графов данный алгоритм работает немного по-другому. Данный вариант алгоритма работает аналогично алгоритму Дейкстры, но потребляет менее m * log(n) операций. Следует отметить, что m может достигать порядка n^2, что означает, что данный вариант алгоритма Дейкстры не всегда превосходит классический подход по скорости, а лишь при небольших значениях m.
Для реализации алгоритма Дейкстры нам необходимо иметь возможность находить вершину с минимальным значением d и обновлять это значение для определенной вершины. В стандартной реализации мы используем простой массив, в котором поиск минимальной вершины по значению d занимает порядка n операций, а обновление значения d для вершины - 1 операцию. Для улучшения производительности используем бинарную кучу .
Бинарная куча поддерживает следующие операции: добавление нового элемента в кучу (за порядка log(n) операций), поиск минимального элемента (за 1 операцию), удаление минимального элемента (за порядка log(n) операций), где n - количество элементов в куче.
Мы создаем массив d[0… n — 1] (его значения остаются такими же, как и ранее) и кучу q. В куче мы храним пары из номера вершины v и значения d[v] (элементы сравниваются по d[v]). Кроме того, в куче могут присутствовать фиктивные элементы из-за того, что значения d[v] обновляются, но мы не можем изменить их в куче. Поэтому в куче может быть несколько элементов с одним номером вершины, но разными значениями d (при этом общее количество вершин в куче не превысит m - это гарантировано). При извлечении минимального элемента из кучи необходимо проверить, является ли этот элемент фиктивным. Для этого достаточно сравнить значение d в куче с его реальным значением. Кроме того, вместо двоичного массива для представления графа используется массив списков.
Добавление каждого элемента в кучу производится m раз, что в сумме дает порядка m * log(n) операций для этого этапа алгоритма.
List<Pair<Integer, Integer>>[] g = new ArrayList[n]; // g[0 ... n - 1] - массив списков, в i-ом списке хранятся пары: first - вершина, соединённая с i-ой вершиной ребром, second - вес этого ребра
int[] d = new int[n];
boolean[] mark = new boolean[n];
PriorityQueue<Pair<Integer, Integer>> q = new PriorityQueue<>(Comparator.comparingInt(Pair<Integer, Integer>::getFirst));
for (int i = 0; i < n; i++) {
g[i] = new ArrayList<>();
}
d[0] = 0;
Arrays.fill(d, 1, n, 2000000000);
for (Pair<Integer, Integer> i : g[0]) {
d[i.getFirst()] = i.getSecond();
q.add(new Pair<>(i.getSecond(), i.getFirst()));
}
for (int i = 1; i < n; i++) {
int v = -1;
int val = -1;
while (v == -1 || d[v] != val) {
Pair<Integer, Integer> top = q.peek();
v = top != null ? top.getSecond() : -1;
val = top != null ? top.getFirst() : -1;
if (top != null) {
q.poll();
}
}
mark[v] = true;
for (Pair<Integer, Integer> pair : g[v]) {
if (d[pair.getFirst()] > d[v] + pair.getSecond()) {
d[pair.getFirst()] = d[v] + pair.getSecond();
q.add(new Pair<>(d[pair.getFirst()], pair.getFirst()));
}
}
}
// вывод массива d
for (int i = 0; i < n; i++) {
System.out.print(d[i] + " ");
}
Таким образом, мы рассмотрели три основных алгоритма нахождения кратчайших путей на графах.