В комментариях к первой части статьи было несколько коротких, но интересных, дискуссий. И во второй части статьи я буду учитывать эти дискуссии. Поэтому начну с чуть более подробного рассмотрения некоторых прикладных и связанных с ними вопросов.
Если вы еще не успели прочитать первую часть статьи, самое время сделать это сейчас
Давайте ненадолго отвлечемся от разрядности ЭВМ и бросим ретроспективный взгляд на них в целом. Это поможет нам лучше понять и связанные с разрядностью вопросы.
Небольшая ретроспектива о программировании для первых ЭВМ
В "доисторические времена" программирование ЭВМ было нелегкой задачей. Ведь программист должен был хорошо знать еще ЭВМ, для которой он разрабатывает программу. Алгоритм решения задачи нужно было вручную перевести в коды машинных команд, которые и вводились в ЭВМ. И распределить переменные по ячейкам памяти нужно было вручную. Не было ни компиляторов, ни языков программирования.
Именно тогда и возникло разделение труда, которое сегодня часто воспринимается как анахронизм:
- Постановщик задач описывал прикладную проблему в том виде, который был пригоден для решения на ЭВМ. И это было не так просто, поскольку возможности первых машин были весьма ограниченными, а само применение ЭВМ делало лишь первые шаги. Постановщик задач выполнял формализацию запросов заказчика переводя их расплывчатые формулировки в четкие параметры.
- Программист разрабатывал алгоритм решения задачи, которую получал от постановщика. Словесные описания он переводил а алгоритмы, максимально близкие к той машине, на которой задача будет решаться.
- Кодировщик выполнял преобразование подготовленных программистом алгоритмов в последовательность машинных команд, в виде кодов, и определял расположение переменных в памяти. По сути, он выполнял работу компилятора.
Это было неудобно, но неизбежно, так как возможности машин были малы. Для облегчения работы программы записывали не только в машинных кодах, но и в виде мнемоник, сокращений словесных названий команд. Так человеку было проще разобраться, что написано другими, найти ошибку в своей программе, внести необходимые изменения.
Давайте, для примера, посмотрим на фрагмент системы команд ЭВМ Урал
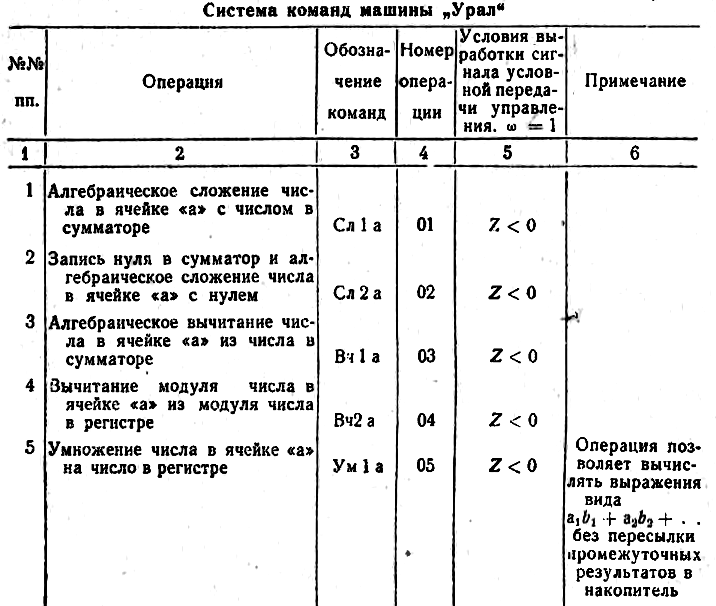
Это только коды операций. Полная машинная команда содержала и дополнительные поля: признак переадресации, признак длины ячейки, адрес ячейки. Здесь можно увидеть мнемонические обозначения операций, но составление командного слова выполнялось человеком, а не машиной.
Если вы думаете, что для зарубежных ЭВМ все было по иному, то ошибаетесь. Вот небольшой фрагмент документации для UNIVAC-I
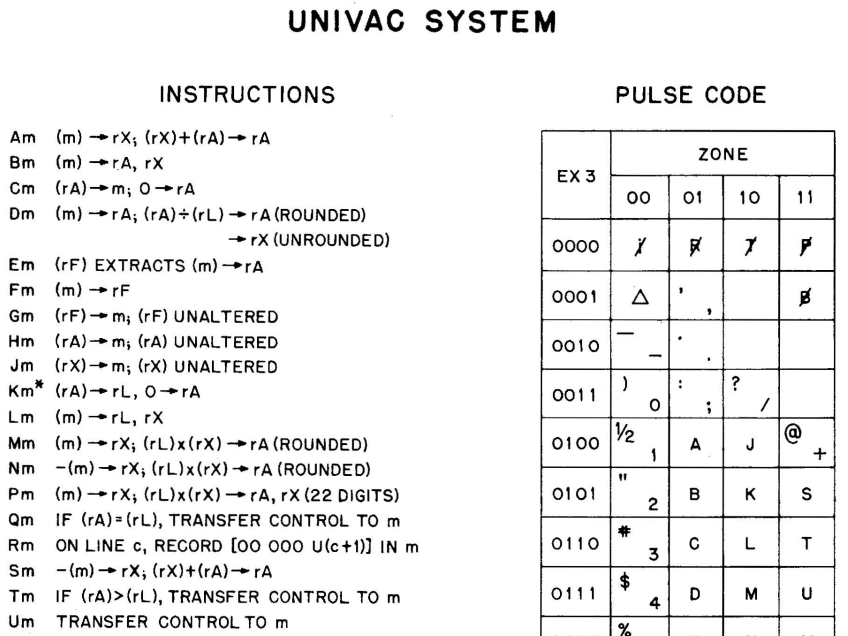
Здесь же видно и кодирование символов для этой ЭВМ. Это еще не называют "байт", это просто коды символов. И они 6-битные.
Вы можете сами посмотреть, как выглядели руководства по программированию для таких ЭВМ:
Причем "Basic" это не название языка программирования, а "Базовый". Другими словами, первая ссылка это "Введение в программирование для UNIVAC-I".
Вот так, примерно, выглядел результат труда программиста, который поступал к кодировщику
А вот и фрагмент готовой программы
Хорошо видно, что программирование было не самой легкой задачей. И это было проблемой для массового распространения ЭВМ. Каждая машина выпускалась относительно небольшими партиями. И каждая машина была уникальной.
Было невозможно просто взять результат работы, даже не кодировщика, а программиста, и использовать его для другой ЭВМ.
Ассемблер
С развитием ЭВМ стало возможным передать самой машине преобразование мнемонической записи программы (последовательности машинных команд) в коды операций. Это был большой шаг вперед, так как машина стала использоваться не только для вычислений. Программы выполняющие такое преобразование впоследствии получили название "Ассемблер". Теперь кодировщику не требовалось вручную формировать двоичные коды машинных команд. Это делала сама машина.
Формат мнемонической записи машинных команд программы уточнялся, добавлялись служебные операторы, которые не преобразовывались в машинные команды, но управляли работой компилятора, появились макросы. Так появился "язык ассемблера", или в просторечии ассемблер или макроассемблер, а программу стали называть транслятором. Ассемблер это запись программы с использованием мнемонического обозначения команд. У каждой ЭВМ (семейства ЭВМ) свой ассемблер, так как и наборы машинных команд разные, и технические детали архитектуры разные. Не существует "Единого языка ассемблера".
Ассемблер жестко привязан к конкретной машине, точнее, семейству машин. При этом формат записи мнемоник команд и операндов может отличаться у разных трансляторов. Достаточно наглядным примером могут служить masm, tasm, as, для IBM-PC совместимых машин (процессор Intel x86). Суть от этого не меняется. Ассемблер сильно облегчил разработку программ, но многие вопросы оставались нерешенными. Слишком большим был разрыв между "языком" машины и математикой или прикладными областями применения ЭВМ. Да и перенос программы на другую машину становился все более актуальным.
Языки программирования высокого уровня (ЯВУ) и операционные системы (ОС)
Перенести на другую машину двоичный исполняемый код невозможно принципиально, если у этих машин разные процессоры. Не поможет и исходный текст программы на языке ассемблера, так как это просто мнемонический вариант двоичного кода. Нужен был способ записи программ не зависящий от конкретной машины. Ни аппаратные особенности, ни тип архитектуры, ни набор машинных команд, ни разрядность, ни тип и количество внешних устройств ввода-вывода, не должны (в идеале!) влиять на запись программы.
Эта задача разбивается, как минимум, на две подзадачи:
- Обеспечение независимости от конфигурации аппаратных средств машины.
- Обеспечение независимости от набора машинных команд процессора.
Первая подзадача была возложена на ОС. Сначала ОС была больше набором типовых процедур ввода-вывода, которые позволяли программисту оперировать не регистрами конкретного периферийного устройства, а более высокоуровневыми понятиями - чтением и записью блоков данных. Файлы и файловые системы появились гораздо позднее.
Фактически, ОС позволяла создать некую усредненную абстрактную машину из машины реальной. Весь зоопарк различных устройств ввода-вывода стал сводиться к типовым:
- Устройства последовательного ввода-вывода
- Устройства ввода-вывода с произвольным доступом
Типичным примером последовательных устройств являются магнитные ленты, а устройств с произвольным доступом магнитные диски и барабаны. Иногда из последовательных устройств выделяли подгруппу символьных, предназначенных для взаимодействия с человеком.
Однако, создаваемая ОС абстрактная машина не решал вопрос абстракции от самого главного элемента ЭВМ - процессора с его набором команд. Решить эту проблему были призваны языки программирования высокого уровня (ЯВУ). ЯВУ опираются на создаваемую ОС абстракцию машины и сами являются средством, позволяющим абстрагироваться от процессора.
Нужно было приблизить машину к специалистам в прикладных областях, включая математиков. Программист не должен влезать в технические аспекты конкретной машины. Иначе программирование и использование ЭВМ так и останутся уделом небольшой кучки избранных. Идеальный мир виделся как возможность свободно использовать любую прикладную программу на любой ЭВМ без каких-либо изменений, а сами программы должен уметь легко писать любой специалист, в любой прикладной области.
Одним из первых ЯВУ был Fortran. Причем первые версии языка сильно отличались от самого популярного варианта - Fortran IV, который еще помнят многие. Этот язык был ориентирован именно на математическое программирование, не случайно название произошло от FORmula TRANslator - транслятор формул. Довольно быстро язык стали использовать не только для вычислительных задач. Стали появляться его новые, значительно расширенные версии. Стали появляться другие языки программирования. Но Fortran нам интересен именно как пример "отрыва" программирования от деталей машины.
Записанная на Fortran программа абсолютно не похожа на программу на любом из Ассемблеров. Нет даже малейшего намека на машинные команды какой-либо ЭВМ. Хотя в наследие и осталось форматирование исходного текста.
Программа на Fortran не могла выполняться машиной непосредственно. Она преобразовывалась либо в текст на ассемблере конкретной машины, либо напрямую в машинные команды, специальной программой - компилятором. При этом к написанному программистом добавлялась и солидная порция кода, который помогал обеспечивать ту самую независимость от конкретного процессора.
Исходный текст программы на ЯВУ, не только на Fortran, действительно можно просто перенести на другую машину и запустить на выполнение после компиляции. Никакое изменение программы не потребуется. Во всяком случае, теоретически. Идеал далеко не всегда достижим.
Но давайте вернемся к разрядности машины.
Машинонезависимые типы данных. Или возвращаемся к разрядности
В Fortran небольшой набор типов данных, а создавать свои типы программист не может. Но эти типы действительно абстрагированы от машины. И они не привязаны ни к разрядности конкретной машины, ни к особенностям представления данных в конкретной машине! Во всяком случае, в идеале:
- INTEGER - целые числа. Причем всегда числа со знаком, как и положено в математике.
- REAL и DOUBLE PRECISION - вещественные числа, конечно со знаком. С вещественными числами не получилось полностью абстрагироваться от машины, так как объем доступной памяти был еще не столь велик и это приходилось учитывать. Числа с двойной точностью не только имели гораздо большее количество цифр, но и занимали больше места. А операции с ними выполнялись медленнее.
- COMPLEX - комплексные числа. Fortran один из немногих языков, который поддерживает комплексные числа изначально. Комплексные числа представлялись парой вещественных.
- LOGICAL - логические данные. Над логическими данными можно было выполнять лишь логические операции.
Нет вообще никакого упоминания разрядности машинного представления. Конечно, конкретные реализации могли иметь существенные ограничения на диапазон представим чисел, это описывалось в документации на компилятор. Для повышения эффективности и скорости вычислений эти базовые типы данных могли привязываться, но не программистом, а компилятором (и это важно), к машинному представлению чисел в процессоре. Но это было совершенно не обязательно.
Даже на 8-битной машине переменные типа INTEGER могли быть представлены 32 битами (4 байтами). Компилятор скрывал от программиста детали машинной реализации. Машина могла не поддерживать числа с плавающей запятой, но компилятор скрывал и это, программист по прежнему мог использовать тип REAL в своих программах. Это сказывалось на быстродействии, но программа продолжала нормально работать.
Увы, наш реальный мир далеко не идеален. Поэтому реализации языков программирования для конкретных машин часто содержат элементы привязки к аппаратным особенностям машины. Например, возможность указывать разрядность некоторых типов данных. Иногда это может становиться частью последующих стандартов языка. Например, можно было указывать количество байт в числе так
INTEGER*4 VAR_A
REAL*8 VAR_B
Переменная VAR_A будет всегда занимать 4 байта (32 бита), даже если программа компилируется на 16-разрядной машине и тип INTEGER (без уточнения разрядности) занимает 2 байта. Переменная VAR_B будет всегда занимать 8 байт, на любой машине, при этом увеличение разрядности касается только мантиссы, но не порядка.
То есть, реальные компиляторы иногда (часто) поддерживали расширения стандарта языка, которые позволяли программисту чуть больше управлять генерируемым компилятором кодом и разрядностью данных, если в этом действительно была необходимость.
В некоторых ЯВУ пошли еще дальше для снижения влияния машинных тонкостей. Например, в языке ADA для чисел можно указывать диапазон возможных значений. Вот примеры описания типов чисел в ADA:
- type Integer is range -(2 ** 31) .. +(2 ** 31 - 1);
- type My_Int is range 1 .. 20;
- type Mod_Int is mod 2 ** 5;
- type T15 is digits 15;
- type T_Norm is new Float range -1.0 .. 1.0;
Сколько разрядов будет использоваться для таких чисел решит компилятор. Более того, компилятор будет определять и машинное представление переменных разных типов. Так целое число в программе вполне может оказаться представленным числом с плавающей запятой на уровне машины. А число с плавающей запятой, но небольшим количеством цифр после запятой, вполне может на машинном уровне быть представлено целым числом.
Существуют и языки программирования, где любая переменная, в любой момент времени, может иметь любой тип. Это обычно, но не обязательно, интерпретируемые, а не компилируемые языки. Есть и весьма странные высокоуровневые языки, которые кажутся предназначенными скорее не для человека, а для марсианина. Например, язык APL, который ориентирован на математическое применение. Но иногда все таки требуется быть "немного ближе к машине". В таких случаях на помощь может придти, например, язык С.
ЯВУ, вместе с ОС, обеспечивают весьма большую независимость программы от "причуд" конкретных ЭВМ. И это не только удобно для программистов, но очень важно. И чем выше уровень языка, тем больше он абстрагирован от реальной машины, на которой выполняется программа. Включая ее разрядность.
Сегодня байт и символ не одно и тоже
В предыдущей статье я показал, что байт действительно не всегда состоял из 8 бит. Байт был машинным представлением печатного символа и сначала занимал 5 или 6 бит. Позднее, с появлением стандартных кодировок символов, байт стал занимать привычные сегодня 8 бит. Но сегодня используются и кодировки включающие в себя и национальные символы, и специальные символы, и пиктограммы. Поэтому символ, не только печатный, может занимать и гораздо больше одного байта.
Поэтому термин "байт" сегодня означает не печатный символ, а совокупность 8 бит. Старый смысл термина почти забылся. Отсюда и неприятие молодым поколением программистов слов, что "байт это не всегда 8 бит". Впрочем, это ведь и сегодня верно, действительно не всегда 8! Но к этому мы еще вернемся позже.
А пока для нас важно, что для прикладных программистов не важна не только разрядность численных данных, но и разрядность данных текстовых. Более того, важно понимать, что символ это зачастую отнюдь не байт. И что старые способы работы с текстовыми данными сегодня чаще всего неприменимы. Например, преобразование строчных букв в прописные прибавлением к коду символа константы или лексикографический перебор алфавита.
За редким исключением, программист сегодня должен абстрагироваться от разрядности текстовых данных, а для работы с ними использовать специальные функции и операторы, которые предоставляет язык программирования или стандартные библиотеки.
Абстрагируемся от разрядности машины на аппаратном и низкоуровневом программном уровнях
Итак, ЯВУ предоставляют нам прекрасную возможность абстрагироваться от машинных тонкостей. В основе этого лежит преобразование конкретной машины в усредненную абстрактную машину. Давайте заглянем немного глубже в то, как такая абстракция может осуществляться. Но коснемся мы, очень кратко и упрощенно, только разрядности данных.
Начнем с математики. ЭВМ, при выполнении абсолютно любой программы, прежде всего работает с различными числами. С точки зрения программиста и пользователя эти числа являются закодированными сущностями прикладной области и реального мира. Но с точки зрения машины это просто числа, которые могут быть представлены по разному.
Для двоичных машин это будут совокупности бит - биты, байты, слова, тетрады, и т.д. Каждый бит является минимальной порцией информации в двоичной машине. Фактически, все, что делает ЭВМ, это именно "жонглирование битами". Семантическая составляющая информации для ЭВМ совершенно не важна, это показал Клод Шеннон. Более того, машине не важна и группировка бит в байты, слова, и т.д. Такая группировка лишь учитывает ограничения реального мира и удобство для человека. Если взглянуть более внимательно, то станет видно, что каждый бит, в любом агрегате данных, это лишь одна двоичная цифра числа.
Для десятичных машин, хоть сегодня они и являются редкой экзотикой (именно чисто десятичные), как и в привычной нам математике, число это совокупность десятичных цифр. Для двоичных машин, естественно, число это совокупность двоичных цифр.
Остается вспомнить, что мы пользуемся позиционными системами счисления. И именно это дает нам возможность свести арифметические операции с числами к совокупности операций с отдельными цифрами этих чисел. Но с учетом того, что эти цифры все таки взаимосвязаны. Да, я говорю о межразрядных переносах/заемах. Примером являются знакомые всем еще по школе операции "в столбик". Например, сложение
Мы складываем цифры соответствующих разрядов чисел, справа налево, от младших разрядов к старшим, и учитываем возникающий при сложении предыдущих разрядов перенос. Нам совершенно не важно, сколько цифр в слагаемых. На выполнение операции сложения (и вычитания) это никак не влияет. Если не считать затраченного времени, конечно. Это касается и операций умножения/деления. Тут немного сложнее, но в конечном итоге все опять таки сводится к операциям с отдельными цифрами чисел
Я не буду приводить пример умножения двоичных чисел, он очевиден. То есть, мы снова можем свести операцию над числами к совокупности операций над отдельными цифрами этих чисел. Ни для двоичных, ни для десятичных чисел, нам совершенно не важно количество цифр в числах. А поскольку цифра числа соответствует одному (очередному) разряду, нас не интересует разрядность.
Более того, на двоичной машине мы можем выполнять любые вычисления, над числами любой разрядности, с помощью всего лишь одноразрядного процессора (или АЛУ)! Просто одна арифметическая операция будет совокупностью некоторого количества машинных операций над отдельными битами (разрядами) этих чисел. Разрядность машины не накладывает ограничений на разрядность обрабатываемых данных (чисел). Но влияет на время выполнения арифметических операций на числами в целом. Просто в большинстве случаев совокупность машинных операций будет медленнее, чем одна машинная операция. Впрочем, не всегда, а при равной тактовой частоте.
Но мы можем выполнять операции не только над отдельными цифрами чисел, но и над совокупностью расположенных рядом цифр. Например, мы можем разбить число не на отдельные цифры, а на группы по 4 цифры. Это совершенно не повлияет на результат операции. Но в таком случае, нам уже потребуется не однобитный процессор, а четырехбитный (для нашего примера).
Именно это позволяет на машине любой разрядности обеспечить работу с числами требуемого диапазона значений. Компилятор ЯВУ просто будет формировать вместо одной машинной команды последовательность команд, если разрядность данных превышает естественную разрядность машины. А само число, на уровне машины, а не ЯВУ, будет представлено как совокупность чисел с меньшей разрядностью. Это повлияет на время выполнения, что может иногда быть очень важным. Но, в общем случае, позволяет просто не обращать внимания на разрядность машины.
Мы пока рассматривали только целые числа, а как быть с вещественными или комплексными? Точно так же. Просто вещественные числа, если они представлены в формате с плавающей запятой, состоят из мантиссы и порядка, которые можно обрабатывать по отдельности, как целые числа. Вещественные числа в формате фиксированной запятой можно просто обрабатывать как целые. Комплексные числа это пара вещественных чисел.
Получается, ЯВУ действительно могут быть независимыми от разрядности машины. Если разработчик компилятора немного постарается. А стандарты ЯВУ не случайно игнорируют само понятие разрядности машины. Но влияние на быстродействие, конечно, при этом будет. Впрочем, не все так просто...
Давайте заглянем еще глубже и перейдем от низкоуровневого программного уровня на уровень аппаратный. Правда это будет функциональный уровень, а не схемотехнический, ведь наше рассмотрение упрощенное. Распространим рассмотренный подход к работе с числами повышенной разрядности на уровень самого процессора. Внимательные читатели заметили, что я частично уже это сделал.
Процессор ЭВМ может быть построен по разному. На канале есть цикл статей (не законченный), в котором я рассказываю о процессорах более подробно. Но нам сегодня достаточно того, что процессор любой разрядности может быть построен из совокупности процессоров меньшей разрядности. Например, мы можем собрать 32-битный процессор из двух 16-битных, или из четырех 8-битных, и т.д.
Теоретически, это позволит строить процессоры наращиваемой разрядности. Причем наращиваемой даже в процессе эксплуатации. Причем даже самими пользователями. Просто нужно добавить секций процессора в стойку и изменить параметры в ОС и компиляторе. И это не такая уж "голая теория". Хотя подводных камней здесь много.
И действительно существуют секционированные процессоры, причем выпускаемые (или выпускавшиеся) в виде комплектов микросхем. Например, это серии микросхем 1800 (ЭСЛ, 4-разрядные процессорные секции), 1804 (ТТЛШ,4-разрядные процессорные секции), 1802 (ТТЛШ,8-разрядные процессорные секции), и т.п. Точнее, это микропроцессорные комплекты, которые позволяют строить процессоры требуемой для конкретной задачи разрядности.
Такой подход к построению процессоров еще называют "Bit slicing", вместо "секционированные процессоры".
Но мы можем пойти и другим путем. Процессор это весьма сложное устройство, но собственно операции в нем выполняет Арифметико-Логическое Устройство (АЛУ). Причем в процессоре может быть несколько АЛУ. Но самое интересное, что разрядность АЛУ совсем не обязательно должна быть равна разрядности процессора. Например, в 32-разрядном процессоре вполне может использоваться 16-разрядное АЛУ. Разумеется, операции на 32-разрядными числами при этом будут выполняться за два этапа, но это будет совершенно невидно извне процессора. С точки зрения пользователя и программиста процессор будет 32-разрядным, а что АЛУ в нем 16-разрядное будет знать только производитель процессора.
Скорее всего, такой процессор будет иметь внутри микропрограммное управление. Чрезвычайно кратко я рассказывал о микропрограммах в статье
Но это будет совершенно незаметно ни для программиста, ни для пользователя. Но зато мы можем построить процессор изменяемой разрядности и даже с изменяемой системой команд. Но это уже далеко выходит за рамки статьи.
Почему же массовые ЭВМ многоразрядные? На самом деле, однобитные процессоры существуют (и это не только MC14500), но действительно не массовые. Некоторое время назад существовали вполне массовые калькуляторы Wang 500, которые для обработки чисел использовали 1-битный процессор. Просто нам чаще требуется обработка именно чисел, а не потоков чисел.
Более того, мы можем собрать однобитные ЭВМ (процессор и немного памяти) в массив, причем трехмерный. И это позволит создавать весьма интересные машины. Таковым является проект STARAN. И массово-параллельные ЭВМ Connection Machine (CM2, CM5). Так строятся ассоциативные ЭВМ. Но сегодня мы не будем такие машины рассматривать.
Подробности машинного представления чисел и системы счисления мы сегодня не рассматривали, но если вам интересно, можете почитать
Заключение
Пожалуй, на сегодня достаточно. Мы лишь чуть глубже копнули, но далеко не закончили рассматривать вопросы связанные с разрядностью ЭВМ. Впереди еще много интересного. На разных уровнях.