Доброго времени суток, читатели, зрители моего канала programmer's notes. Не забывайте подписываться и писать свои комментарии к моим статьям и видео. И, конечно, не забывайте о лайках.
Библиотека requests для Python
Библиотека requests одна из лучших библиотек для получения информации из Интернет (см. также статью). Установить библиотеку можно стандартно с помощью pip3 (pip).
Простые запросы requests
В протоколе http есть несколько методов. Чаще всего мы используем метод GET. Вот с этого и начнем.
r = request.get(url)
Если запрос оказался выполненным (url доступен), то создается объект r. Всё крутится вокруг этого объекта.
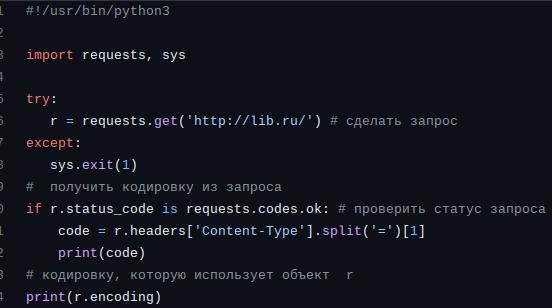
Рассмотрим программу ниже. В нем закачивается web-страница и, естественно создается объект, содержащий всю информацию о закачке. Поскольку не всегда удается выполнить запрос, в программе показано, как проверить это.
Свойство headers представляет собой словарь, где хранится та часть html-страницы, называемая head (заголовок). Например информация о кодировке. Мы показываем, как "вытащить" эту кодировку. С другой стороны, у объекта r есть свойство encoding, где как раз хранится кодировка, которая взята за основу в самом объекте. Обычно они должны совпадать. Однако, информация о кодировке на странице может и отсутствовать.
Замечание
Числовая константа requests.codes.ok равна 200, так что мы в дальнейшем будем использовать ее числовой эквивалент.
Использование json
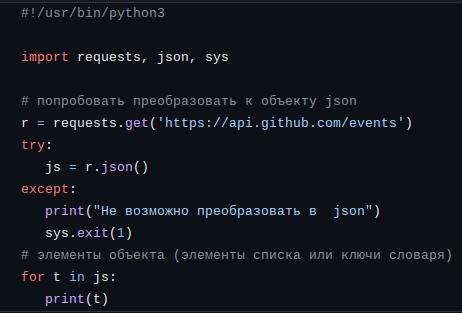
Полученные результат можно преобразовать к объекту json. Это можно сделать с помощью метода .json(). Этот подход представлен в программе ниже.
В программе ниже показан другой способ получения объекта json. Дело в том, что свойство text объекта r содержит полученный результат в виде текстовой строки. Ну а далее используются уже известные возможности модуля json.
Замечание
Объект json вещь удобная, но к сожаления очень часто представленное выше преобразование не возможно по той или иной причине. Так что придется заниматься парсингом по полной программе. Но это же интересно.
Скачивания изображения с помощью библиотеки requests
В программе ниже скачивается картинка и сохраняется в текущий каталог.
#!/usr/bin/python3
import requests
from PIL import Image
from io import BytesIO
# качаем картинку
pt = 'https://gas-kvas.com/grafic/uploads/posts/2023-09/\
1695931383_gas-kvas-com-p-kartinki-s-kotami-9.jpg'
r = requests.get(pt)
im = Image.open(BytesIO(r.content))
im.save('im.jpg')
Замечание
К библиотеке io мы обратимся в одной из следующих статей
Запросы GET с параметрами в библиотеке requests
Рассмотрим, как упростить запросы, если в строке url есть параметры. Можно, конечно, записывать всю строку целиком с параметрами или оперировать с ней как со строковой переменной, при необходимости меняя ее отдельные части. Можно, например, для поиска некоторого слова (фразы) в поисковике Яндекс использовать url
https://yandex.ru/search/?text=питон
но можно воспользоваться возможностями метода get (см. программу ниже).
#!/usr/bin/python3
import requests
# реализуем запрос к поиску в Яндекс
# https://yandex.ru/search/?text=питон
par = {'text': 'питон'}
url = 'https://yandex.ru/search/'
# страница поиска Яндекс по ключевому слову 'питон'
r = requests.get(url, params=par)
print(r.text)
В следующей программе мы обращаемся к картографической службе Яндекс
#!/usr/bin/python3
import requests
from PIL import Image
from io import BytesIO
url = "http://static-maps.yandex.ru/1.x/"
par = {'ll': '61.4291,55.154', 'spn': '0.002,0.002', 'l': 'map'}
r = requests.get(url, params=par)
map = "map.png"
f = open(map, "wb")
f.write(r.content)
Замечание
Для того, чтобы узнать, правильно ли вы сформировали url, воспользуйтесь свойством r.url - этот то самый url, который использовался в запросе.
Попробуйте, кстати, получить карту своего города.
Обработка ошибок при использовании библиотеки requests
При работе с запросами к сетевым ресурсам важна обработка ошибок. При работе с библиотекой requests обработка представляет собой сочетание использования исключений (try - except) и возвращаемого значения status_code. Пример такой обработки представлен в программе ниже.
Замечание 1
Ошибка таймаута возникает в том случае, если мы определим соответствующий параметр: requests.get(url, timeout=5) - указан промежуток 5 секунд.
Замечание 2
Как мы видим не все ошибки вызывают исключения. О части ошибок мы узнаём по значению status_code.
requests, скачивание web-страницы
Для того, чтобы анализировать полученную страницу, удобнее всего сохранить ее на диске, а потом уже применять те или иные способы анализа. В программе ниже осуществляется запрос к указанной странице и текст этой страницы сохраняется на диске. Мы, кстати, можем посмотреть ее и с помощью браузера. Ну в общем то все готово для анализа.
#!/usr/bin/python3
import requests
url = 'https://vk.com/id219876885'
r = requests.get(url)
fh = open('myweb.html', 'w')
fh.write(r.text)
fh.close()
Ну еще один важный вопрос. Некоторые сайты распознают в вашем запросе бота. Обойти это можно если представиться, например, браузером. Для этого нужно указать User-Agent. Смотрим программу ниже.
#!/usr/bin/python3
import requests
hd = {
'User-Agent': 'Mozilla/5.0 (compatible; U; ABrowse 0.6; Syllable) AppleWebKit/420+ (KHTML, like Gecko)'
}
url = 'https://lenta.ru'
r = requests.get(url, headers=hd)
fh = open('myweb.html', 'w')
fh.write(r.text)
fh.close()
Ну, пока всё!
Пишите свои предложения и замечания и занимайтесь программированием, а также проектированием баз данных, хотя бы для поддержания уровня интеллекта.