Баз данных в нашем мире существует великое множество! Эта статья - путеводитель, который поможет вам разобраться, чем примечательна каждая из них.
Честно признаться, разнообразие баз данных и меня когда-то очень покорило. Да-да, оказалось, что помимо стандартного варианта "табличек" существует и много других. И в каждой из них используются принципиально разные подходы в хранении, обработке, извлечении и самое главное - построении связей между данными.
Поэтому сегодня поговорим об основных видах БД, их особенностях и обязательно рассмотрим интересные и наглядные примеры, чтобы уложить всю информацию по полочкам!
2 главных категории:
Все существующие Базы Данных можно поделить на 2 больших клана: Реляционные и Нереляционные.
Первые как раз являются представителями "табличного" хранения и предполагают, что данные являются структурированными. Однако не всегда информацию можно представить в виде связанных таблиц. Существует большой пласт слабоструктурированных и неструктурированных данных, для обработки и хранения которых используются нереляционные БД. Их еще называют NoSQL.
Корни второго названия идут из факта, что для манипуляций с реляционными данными всегда используется язык запросов SQL (structured query language). Именно с помощью него мы можем крутить-вертеть нашими данными. В случае же с нереляционными БД этот подход не работает, но работают другие..))
поэтому группа получила название NoSQL.
Реляционные базы данных.
Это самый распространенный тип БД. Сегодня более 80% обрабатываемой информации представляют собой структурированные реляционные данные.
Тут само название уже намекает на суть механизма работы. Реляционные от слова "relational" - имеющие отношения. Основной структурной единицей здесь выступают таблицы. Каждая таблицы представляет собой набор записей, где каждая запись представляет собой кортеж (строку), а столбцы - атрибуты (поля).
Между таблицами существуют отношения - логические связи, которые позволяют объединять информацию из таблиц между собой в единую экосистему. Связь между таблицами осуществляется посредством ключей.
- Первичный ключ определяют поле (столбец) или набор полей, которые могут однозначно идентифицировать 1 запись.
- Внешние ключи - поля, которыми обеспечивают связь между записями в различных таблицах.
Как это работает?
Рассмотрим импровизированную базу данных Риэлтерского агентства. В ней есть 5 таблиц с данными. См. схему ниже
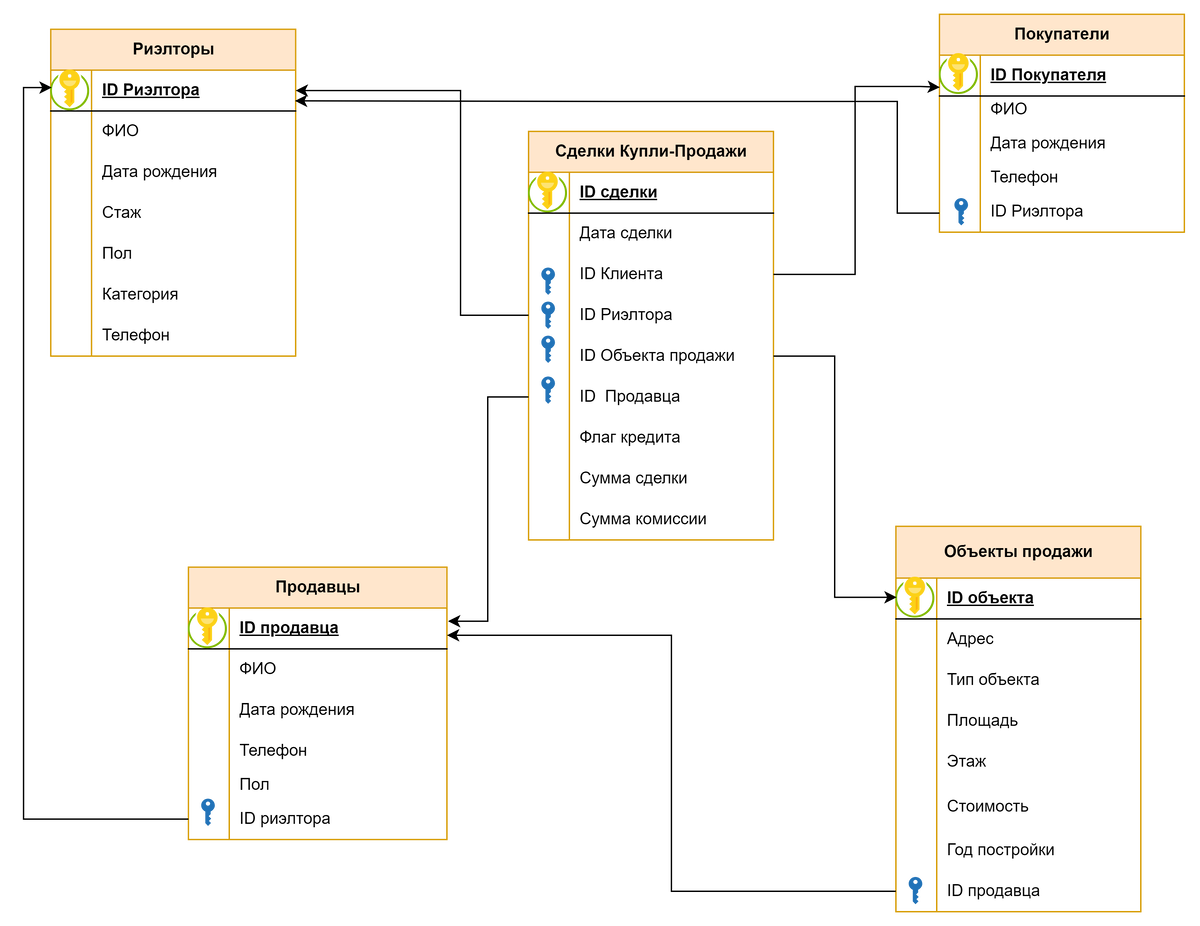
- Информация о риелторах
- Покупателях
- Продавцах
- Объектах продажи
- Совершенных сделках
У каждой таблиц есть поле ID - уникальный идентификатор одной записи. Это Первичные ключи, они помечены желтым ключиком. (Первичный ключ может быть представлен и несколькими полями)
Также эти поля могут выступать Внешними ключами в других таблицах базы. В схеме ниже они помечены синим ключиком. В этом случае по этим столбцам мы можем подтягивать информацию из других таблиц.
Для работы с реляционными базами данных используют реляционные СУБД (системы управления базами данных)
Наиболее распространенные СУБД:
Нереляционные базы данных
В этой категории начинается магия!
Существует несколько разновидностей нереляционных БД. Отличаются они типами связей.
Документо-ориентированные (Document Stores)
Хранение данных реализовано в "документах"- (обычно в формате JSON или BSON). Каждый документ - самодостаточная единица данных. Прелесть такого вида хранения в том, что мы можем иметь разный набор полей для каждого документа и этот набор варьировать. Более того, можно легко работать с вложенными данными и документами.
Рассмотрим игрушечный пример хранения каталога книг в библиотеке. Синтаксис: MongoDB.
Здесь каждая книга представлена в виде документа. Документ содержит информацию о названии, авторе, жанре и т.д.
- _id - уникальный идентификатор документа.
- title, author, genre, publish_date - это поля, содержащие информацию о книге.
- reviews - это вложенный документ, представляющий отзывы книги. Это может быть массив объектов.
Графовые (Graph Databases)
Спроектированы для эффективной работы с данными, организованными в виде графа. Используется для решения задач, связанных с анализом связей и сетей. Основные элекменты в графах
- Узлы (Nodes):Экземпляры данных или сущности.
Представляют объекты для отслеживания, например, людей, заказы, подразделения. - Рёбра (Edges): Показывают взаимосвязи между узлами.
Могут иметь направление (одно- или двунаправленные). - Свойства (Properties):Содержат описательную информацию, связанную с узлами и, иногда, с рёбрами.
Могут включать различные атрибуты, описывающие характеристики узлов или связей.
Рассмотрим пример графовой БД. Здесь фиксируется не только список фильмов, актёров и режиссёров. Не меньшее внимание уделяется связям, что позволяет одновременно хранить информацию о том, в каких фмильмах снимался актер, и какие актеры снимались в 1 фильме, и тд. Также у ребер могут быть свойства:
- У фильмов: год выпуска, жанр, длина
- У личностей: возраст, происхождение.
Примеры СУБД: Neo4j, OrientDB, Amazon Neptune.
Ключ-значение (Key-Value Stores)
Данные хранятся в виде пар "ключ-значение". Ключ служит идентификатором, а значение представляет собой данные, связанные с этим ключом.
Примером такого хранения может стать кеш-хранилище сессий для пользователей веб-приложения.
Каждая сессия помечается уникальным ключом (например, ID сессии), и ей соответствует значение, содержащее информацию о пользователе, его предпочтениях и статусе.
SessionID123: {"userID": "user123", "username": "john_doe", "preferences": {"theme": "dark", "language": "en"}, "status": "active"}
SessionID456: {"userID": "user456", "username": "jane_smith", "preferences": {"theme": "light", "language": "fr"}, "status": "inactive"}
Этот формат - один из наиболее простых и производительных для быстрого доступа к данным. Часто используется для кэширования и хранения простых данных, таких как сессии и настройки.
Примеры СУБД: Redis, DynamoDB, Riak.
Тот, кто дошел до сюда, герой! А мы приходим к последнему на сегодня, но не менее интересному виду БД.
Колоночные БД (Column-Family Stores/wide column)
Данные организованы не в виде строк, как в традиционных реляционных базах данных, а в виде семейств столбцов. Давайте рассмотрим основные аспекты колоночных баз данных более подробно:
Посмотрим на пример колоночной базы данных для отслеживания оценок студентов:
Каждая таблица представляет атрибуты студентов и их оценки, и каждый столбец содержит значения для конкретного атрибута.
Если бы у нас появился новый атрибут, например, "Спортивные достижения", мы могли бы легко добавить новый столбец без изменения всей структуры таблицы студентов.
Для сравнения в традиционной реляционной БД таблица с оценками выглядела бы следующим образом:
Здесь уже данные организованы по строкам, где каждая строка представляет уникальную комбинацию атрибутов. Также добавление новых атрибутов требует расширение структуры, что снижает гибкость БД.
В целом, колоночные БД хороши тем, что за счет хранения по столбцам и сжатия они требуют меньше места и позволяют многие запросы обрабатыват быстрее
В заключении, хочется сказать, что в современном информационном обществе базы данных - Это База!
БД являются фундаментальным инструментом для хранения, управления и анализа данных. Выбор типа базы данных всегда зависит от конкретных требований и потребностей проекта.
Но БД продолжают оставаться ключевым элементом цифровой эры, и понимание их особенностей является важным элементом успешного управления информацией в различных областях.