Решал-решал задачи проекта Эйлер, а тут на Дзене попался разбор задачи ЕГЭ (старый, 2021 года).
Захотелось сравнить. Если проект Эйлер это типа сложные задачи, то какие должны быть задачи ЕГЭ? Проще? Или нет?
Задача
В текстовом файле записан набор натуральных чисел, не превышающих 10⁹. Гарантируется, что все числа различны. Необходимо определить, сколько в наборе таких пар чётных чисел, что их среднее арифметическое тоже присутствует в файле, и чему равно наибольшее из средних арифметических таких пар. Первая строка входного файла содержит целое число N — общее количество чисел в наборе. Каждая из следующих N строк содержит одно число.
В ответе запишите два целых числа: сначала количество пар, затем наибольшее среднее арифметическое.
Решение
Ну, с виду это вполне себе начальный уровень проекта Эйлер, поэтому я решил попробовать. Ведь если это умеют школьники, то должен уметь и я :)
Так как у меня нет доступа к файлу задачи, я сгенерировал свой файл на языке PHP:
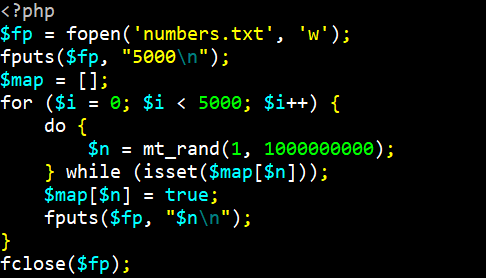
Этот скрипт генерирует 5000 гарантированно неповторяющихся чисел размером до миллиарда.
Далее можно посмотреть, как задача была решена в той статье, которую я нашёл:
Файл читается в массив, бегаем по массиву, перебираем пары чётных чисел, вычисляем среднее, ещё раз бегаем по массиву и ищем совпадения.
Проблема тут в том, что программа работает очень медленно. У автора получилось время в минутах, у меня около 15 секунд, но это всё равно медленно.
Для поиска совпадений автор решил использовать бинарный поиск, а для бинарного поиска необходимо, чтобы массив был предварительно отсортирован. Поэтому к задаче добавляется ещё и сортировка.
Подумав, я решил поступить так же, но с некоторыми изменениями.
Когда я читаю число из файла, кстати вот оно:
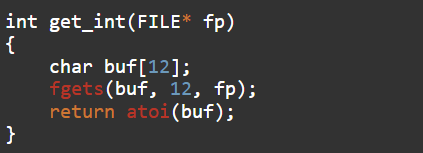
то сразу проверяю его на чётность. Чётные числа помещаю в начало массива, а нечётные в конец.
Таким образом, у меня получится массив, первая часть которого заполнена только чётными числами, а вторая только нечётными.
Каждая часть будет отсортирована независимо от другой.
Сортировку пузырьком я делаю сразу при добавлении числа в массив. То есть число всегда добавляется в уже отсортированный массив, поэтому код сортировки упрощается (общее количество операций остаётся тем же).
Вот чтение файла и добавление в массив:
Как можно видеть, для сортировки в начале и конце массива используются разные методы:
Это потому что при добавлении в конец или в начало пузырёк должен двигаться в разных направлениях, иначе получается очень неудобно с индексами. Проще сделать два метода.
Далее, нужно пройти по первой части массива, которая содержит только чётные числа, и перебрать их пары.
Вычислив среднее арифметическое пары, снова проверяю его на чётность. Если оно чётное, то ищу его в чётной части массива, а если нечётное, то в нечётной. По сути это уже первая итерация бинарного поиска, которая сразу отбрасывает половину массива.
Ну и сам бинарный поиск в заданных рамках индексов begin и end:
Вычисляем индекс-середину между begin и end. Если элемент по этому индексу больше, чем мы ищем, то все элементы правее его тоже больше (именно для этого нужен отсортированный массив), поэтому середина становится новым end. Если же меньше, то все элементы левее середины также меньше. Тогда середина становится новым begin.
Так повторяется до тех пор, пока не найден искомый элемент, либо пока begin и end не сойдутся вместе.
С этими модификациями программа стала выполняться за примерно 0.5 секунды.
Ссылка на онлайн-компилятор языка C с полным текстом программы
(Онлайн работать не будет, так как нельзя загрузить файл с данными)
Хочу обратить внимание на вот эти строчки:
Это эквивалент такого кода:
Данный приём называется branchless programming :)
Подборка задач проекта Эйлер