В этом выпуске я буду разбирать решение очередной задачи на канале:
Задача
Наибольшее произведение четырёх последовательных цифр в нижеприведенном 1000-значном числе равно 9 × 9 × 8 × 9 = 5832.

Найдите наибольшее произведение тринадцати последовательных цифр в данном числе.
Решение (и критика)
Автор сходу усложняет задачу сам себе, так как ему нужен список чисел, но руками его вбивать сложно, поэтому он делает строку копипасты из символов-цифр, а потом преобразует эти символы обратно в числа.
Начало, в общем-то, верное. Последовательность представлена как сплошная строка цифр:
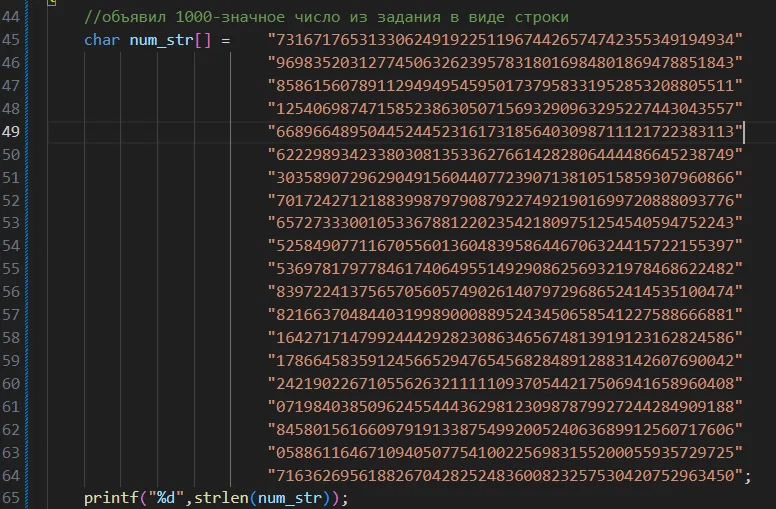
Но вот дальше с ней не надо делать НИЧЕГО.
Это уже готовые числа, ничего преобразовывать не надо.
В языке C название типа char происходит от character, то есть "символ". Мы можем присвоить переменной типа char любой одиночный символ:
char c = 'A';
Но в то же время мы можем присвоить переменной типа char любое 1-байтное число:
char c = 65;
Это значит, что в памяти и символ, и число хранятся совершенно одинаково и символ взаимозаменяем с числом.
В частности, число 65 это код символа 'A', поэтому такое условие сработает:
if (65 == 'A') printf("true");
В нашей последовательности хранятся символы-цифры, у которых есть численные значения. Символ '0' это 48, символ '1' это 49 и так далее. Следовательно, если строка это массив символов, то мы можем получить символ в позиции n и вычесть из него 48 или '0', что без разницы:
char c = data[n] - '0';
В результате, если символ был '0', после вычитания мы получим математический 0, если '1', то 1, и т.д.
Кстати, такие манипуляции можно проделывать и в других языках, где нет взаимозаменяемости чисел и символов. Там для этого можно использовать функции вроде char() и ord():
$c = ord($data[$n]) - ord('0'); // PHP
Нахождение максимального произведения
Решение автора простое: берём первые 13 символов, считаем их произведение. Это будет текущий максимум. Далее берём 13 символов начиная со второго, считаем, сравниваем с максимумом. Если больше, устанавливаем новый максимум. Берём 13 символов начиная с 3-го, считаем, сравниваем, и т.д.
В принципе всё в порядке, но обратим внимание на то, что в массиве данных присутствует довольно много нулей.
Любой 0, попав внутрь фрагмента из 13 чисел, убивает их произведение.
Значит, встретив 0, мы можем прекращать перемножать числа и сразу переставлять начальную позицию фрагмента на следующее число после нуля.
С такой поправкой я сделал свой вариант:
Ссылка на онлайн-компилятор языка C с текстом программы:
Оптимизация (?)
Представим, что нулей в данных нет. Тогда можно было бы действовать так:
Вычислить произведение первого фрагмента из 13 чисел.
Далее у фрагмента есть голова (первое число) и хвост (13-е число). Мы двигаем фрагмент дальше, выводя из него голову и вводя следующее число после хвоста. При удалении головы произведение внутри фрагмента делится на значение головы – ведь голова там была одним из множителей. При наращивании хвоста произведение умножается на значение хвоста – добавляется новый множитель. То есть фрагмент движется по массиву данных, как и раньше, но теперь не надо считать произведение 13 чисел на каждом шаге. Надо делать только одно деление и одно умножение.
Но этому опять мешают нули. Они буквально обнуляют полезную информацию. Поэтому адаптация данного метода к массиву с нулями немного усложняется.
Ссылка на онлайн-компилятор языка C с текстом программы:
В данном коде первоначально голова и хвост равны. На каждом шаге цикла хвост отползает от головы на 1 элемент и добавляет один множитель в произведение. Если встретился 0, голова перемещается на хвост, текущее произведение сбрасывается в 1, и всё происходит заново.
Когда между хвостом и головой накопилось L (=13) элементов, текущее произведение уже можно сравнить с максимумом. Голова начинает ползти за хвостом, чтобы удерживать длину фрагмента в L элементов.
Я не тестировал эту версию дотошно, но... как-то так.
Вся подборка задач: