Проведём эксперимент для сравнения производительности двух подходов: кластеры и классы как оболочка над кластерами.
Несомненно, классы представляют бОльшую функциональность по сравнению с кластерами, но сейчас интересует сравнение производительности двух подходов.
Операции «под капотом» могут показаться банальными, но это сделано, чтобы минимизировать потери на сами операции, и измерить практически чистую скорость доступа.
Кратко:
Программа для работы использует набор данных, которые собраны в кластер. В процессе работы программа берёт элемент, манипулирует с ним и возвращает в кластер.
Для сравнения остановился на следующих подходах:
- unbundle/bundle
- unbundle/bundle by name
- передать кластер в subVI, где выполнить unbundle/bundle
- unbundle/bundle by name, но саму операцию выполнить в subVI.
- обернуть кластер в класс, для доступа использовать data member access
- вызвать статический метод класса
- вызвать динамический метод класса
- заодно сделать класс-потомок и повторить два предыдущих шага.
Для измерения скоростей использую вариацию state machine, где в каждом кейсе много раз выполняется одно и то же действие.
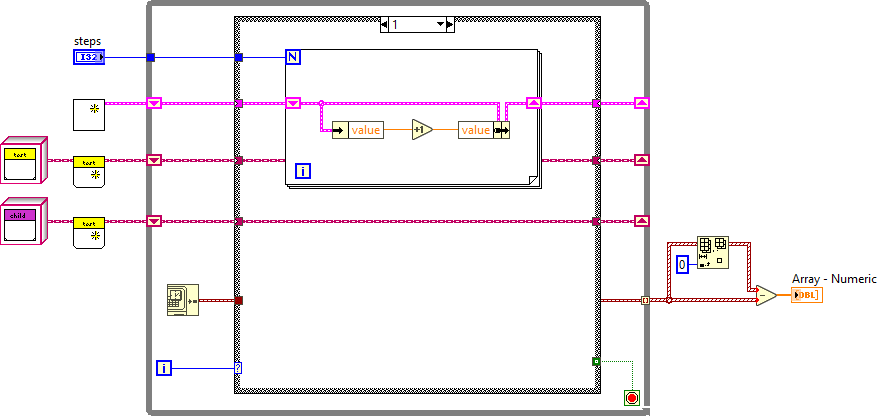
Параллельно оболочка замеряет время выполнения операции.
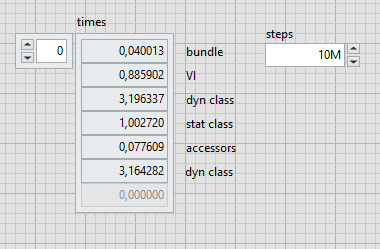
Дальше идут результаты, отсортированные по времени исполнения, и небольшие комментарии
Самое быстрое решение – работа с кластером прямо в коде.
С небольшим отрывом на грани статистической погрешности идёт (un)bundle by name.
Третье место – получение значения через методы класса. Скорость доступа вполне предсказуема, т.к. эти функции создаются в формате inline.
Наконец, добрались до классов. Наследование никак не замедляет скорость доступа к данным, даже как будто ускоряет его.
А вот динамические методы работают с три раза медленнее статических. Так что не стоит ими злоупотреблять без лишней необходимости.
Резюме:
Несмотря на то, что подход «лепи всё в одну функцию» показал самую высокую производительность (что не удивительно), не стоит им злоупотреблять.
Так же тесты показали, что делать класс только ради класса не разумно. С другой стороны, статические методы не сильно проседают по скорости, так что их вполне можно использовать как стартовую площадку для изучения классов.