Мы рассмотрели три разных архитектуры процессора, которые, по своей сути, относятся лишь к ядру процессора. Да и то лишь части ядра. Наши функциональные схемы отражали лишь взаимодействие отдельных элементов, причем в самом обобщенном виде. Чтобы показать концепцию, и не более того. Но некоторые читатели заинтересовались более подробным описанием, вплоть до принципиальных схем.
Статьи задумывались как статьи в стиле "как это устроено и работает", а не как "как это сделать". И даже близко не могут считаться "учебником".
Используемы в статье термин "ядро процессора" не соответствует "ядру процессора", как многим привычно по высокоуровневой терминологии. В данном случае, ядро процессора это именно вычислительное ядро, АЛУ и окружающие его элементы, вокруг которых и строится процессор. Несколько таких низкоуровневых вычислительных ядер, использованных в одном процессоре, не делают процессор многоядерным. Но повышают разрядность процессора.
До уровня принципиальных схем мы сегодня не дойдем, но спустимся с функционального уровня на логический. Дело в том, что концепция архитектуры может быть реализована совершенно разными схемотехническими решениями. Например, на динамической одноразрядной (последовательной импульсной) логике (синхронной). Или на привычной всем потенциальной логике (ТТЛ/КМОП/ЭСЛ, и т.д.). Непохожие друг на друга схемотехнически, процессоры будут идентичными с точки зрения архитектуры.
Сегодня мы будем рассмотрим построение ядра процессора из потенциальных логических элементов. Мы будем использовать как комбинационные элементы (например, логические или мультиплексоры), так и последовательностные (например, триггеры или счетчики). Но не будем привязываться к какой-либо определенной серии микросхем. И не будем учитывать временные параметры элементов (время переключения, задержку распространения, и т.д.).
Готовы попробовать себя в проектировании универсального ядра процессора? Тогда вперед!
Узкоспециализированное и универсальное
Процессоры можно построить как чисто аппаратные. А можно лишь выглядящие таковыми, при взгляде "снаружи". В любом случае, процессор состоит из множества узлов. Машинная команда поступает на дешифратор команд, который формирует на выходе последовательность управляющих сигналов для других узлов процессора. Но некоторые команды могут быть сложными для непосредственного схемотехнического воплощения. Например, команды умножения и деления.
Как может быть устроен блок умножения я писал в статье
Для упрощения (и удешевления) процессора умножение и деление могут быть реализованы итерационно. Но такой подход удобнее реализовывать программно. Такую программную реализацию, не видимую пользователю процессора, называют микропрограммной. При этом дешифратор команд на выходе формирует адрес начала микропрограммы, а не последовательность сигналов управления.
Очень кратко я об этом писал в статье
Нам сегодня не важно, как именно построен процессор, аппаратно или микропрограммно. Но важно, что ядро процессора использует множество внешних сигналов, причем не только сигналов данных, но и сигналов управления. И характер архитектуры во многом определяется именно этими сигналами. А ядро может быть достаточно типовым, стандартным.
Вот такое ядро мы и будем сегодня рассматривать (проектировать). Давайте еще раз взглянем на все три архитектуры. Самая простая - аккумуляторная, имеет всего один регистр (аккумулятор). Регистровая является наиболее универсальной. Но если посмотреть внимательно, то можно заметить, что от стековой она отличается лишь возможностью использовать любой регистр в явном виде. И отсутствием строгих правил (дисциплины) для доступа к блоку регистров (стеку).
Таким образом, в нашем ядре процессора можно предусмотреть блок регистров достаточного объема, что будет избыточно для реализации аккумуляторной архитектуры. Но при изготовлении ядра в виде готовой микросхемы, которая будет использовать при построении процессоров, эта избыточность будет компенсировать универсальностью.
Но мы будем стремиться к еще большей универсальности. Для этого мы не будем ограничиваться жестко заданной разрядностью (количеством обрабатываемых бит) процессора. Наше ядро должно предусматривать возможность наращивания разрядности. Кстати, именно такой подход использован в комплектах микросхем микропроцессорных секций для построения процессоров.
АЛУ
Ядром ядра процессора, которое мы сегодня рассматриваем, является АЛУ - Арифметико-Логическое Устройство. Я описывал примеры построения АЛУ в статьях
Причем на уровне логических элементов. Поэтому сегодня мы будем просто использовать АЛУ как самостоятельный элемент, без погружения в его внутренний мир. Но нам нужно определиться с его входными и выходными сигналами
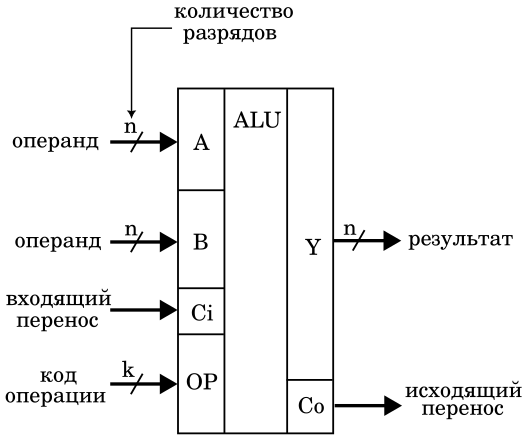
АЛУ является чистой комбинационной схемой и работает полностью асинхронно. То есть, любые изменения его входных сигналов через некоторое время приводят к изменению выходных сигналов. Это время задержки называется временем выполнения операции. Важно понимать, что выходные сигналы могут формироваться не одновременно. Например, результат может появляться на выходе АЛУ чуть раньше, чем сигнал исходящего переноса. Поэтому за время выполнения операции принимается максимальное время распространения сигнала внутри АЛУ.
АЛУ может выполнять различные операции. Конкретная операция выбирается кодом операции, который подается на вход OP. Количество разрядов кода операции зависит от количества выполняемых АЛУ команд. Но это означает, что внутри АЛУ может находиться дешифратор кода операции, который формирует сигналы управления всеми элементами АЛУ. Но дешифратора может и не быть. В этом случае "код операции" является комбинацией сигналов управления элементами и количество его разрядов может быть любым. Нас сегодня не интересуют подробности формирования кода операции, так как он поступает "из внешнего мира" (с дешифратора команд или блока микропрограммного управления, например). Поэтому просто обозначим количество разрядов кода операции как k.
При наращивании разрядности обрабатываемых данных за счет использования нескольких ядер процессора входы OP соединяются параллельно. АЛУ всех ядер выполняет оду и ту же операцию. Для упрощения логических схем вход OP будет изображаться не всегда. Для нас выполняемая АЛУ операция сегодня не важна.
Назначение входов операндов A и B достаточно очевидно. Равно как и выход результата Y. Поскольку мы договорились, что разрядность нашего ядра процессора будет наращиваемой, разрядность одного ядра может быть небольшой. Мы просто обозначили разрядность как n. Чаще всего разрядность одного ядра принимают равной 2, 4, или 8. Эта разрядность не имеет принципиального значения. Достаточно рассмотреть построение одного разряда, а потом включить параллельно несколько идентичных разрядов.
Это не всегда так. Например, построение многоразрядных сумматоров часто требует использования схем ускоренного переноса. Однако, схемы ускоренного переноса тоже имеют регулярную структуру.
Входящий (Ci) и исходящий (Co) переносы кажутся менее очевидными. Большинство читателей привыкло видеть флаги переноса в слове состояния процессора (PSW), а не в виде сигналов на входе и выходе АЛУ. Тем не менее, для некоторых операций эти сигналы являются важными, так непосредственно участвуют в выполнении операции. Примерами таких команд являются сложение и вычитание.
Почему я выделил именно сигналы переноса и проигнорировал сигналы переполнения, отрицательного или нулевого результата? Дело в том, что перенос непосредственно участвует в операциях, а остальные флаги/статусы формируются по результатам операции. Они не нужны АЛУ как входящие сигналы. Формирование этих флагов мы сегодня не будем рассматривать.
Сигналы переноса используются при каскадировании ядер процессора. При этом каждое ядро обрабатывает лишь часть разрядов данных, с которыми работает процессор. Так 4 ядра, каждое их которых является 4-разрядным, позволяют построить 16-разрядный процессор. Сигналы переноса при этом соединяются последовательно (как для обычных многоразрядных сумматоров). Или с использованием ускорителей переноса.
Защелки операндов и результата
Итак, АЛУ является комбинационным асинхронным узлом. А значит, любое изменение на входах операндов непосредственно отображается на выходе результата (через время выполнения операции). Это является проблемой, которую можно решить использованием регистров-защелок на входах и выходах данных АЛУ. Регистры-защелки часто изображают как D-триггеры. Они действительно похожи, но все таки работают немного по другому. Да и устроены проще
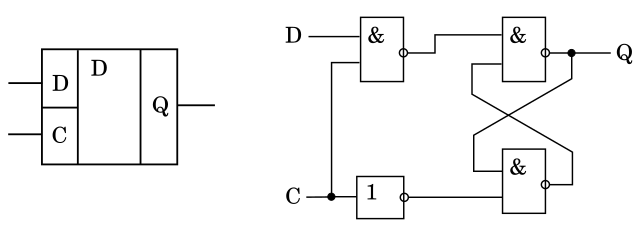
В отличии от D-триггера, в котором запись состояния информационного входа D осуществляется по фронту или спаду тактового сигнала C, защелка полностью прозрачна при "1" на входе C. Прозрачность означает, что состояние входа непосредственно отображается на состоянии выхода Q. Разумеется, с небольшой задержкой. При "0" на входе C состояние входа D не влияет на состояние выхода Q, защелка сохраняет состояние, которое было до перехода C в "0". Вы можете самостоятельно разобраться с тем, как именно работает защелка по приведенной на иллюстрации схеме. Еще раз отмечу, что D-триггер работает по фронту/спаду тактового импульса, а защелка является потенциальной.
Обратите внимание, что защелка является последовательностным устройством, а не комбинационным.
Почему защелка, а не D-триггер? Использование D-триггера сделает наше АЛУ синхронным, а защелка позволяет сохранить асинхронность. Но позволяет и использовать синхронный режим. Защелки на входах операндов нужны, но давайте подумаем, нужна ли нам защелка на выходе результата? Защелка на выходе не обязательна, поскольку фиксируя операнды на входе мы автоматически фиксируем и состояние выходов АЛУ. Таким образом мы можем оптимизировать структуру процессора исключив один регистр-защелку.
О что насчет входящего переноса? На первый взгляд, для него нужна защелка, но если подумать, то становится понятно, что защелку ставить нельзя! Да, входящий перенос участвует в выполнении некоторых операций. Но если мы каскадируем наши ядра, то распространение переноса будет не только асинхронным, но он будет распространяться независимо от операндов.
Таким образом мы получаем такой фрагмент структуры непосредственно связанный с работой АЛУ
Выбор источников операндов
Теперь посмотрим, какие источники операндов у нас могут быть.
- Один из внутренних регистров данных
- Внешняя оперативная память
- "0"
- Константа в коде машинной команды
Первые два варианта понятны, поэтому кратко остановимся на двух оставшихся. Зачем нужен операнд равный логическому "0"? Дело в том, что АЛУ выполняет операции всегда с двумя операндами. Добавлять операции использующие лишь один операнд нет смысла. Но машинные команды бывают и с одним операндом. И даже вообще без явно заданных операндов. При выполнении таких команд на вход АЛУ подают один из операндов равный "0". Как правило, это операнд B. Константа в коде команды является типовым случаем, но для нас она ни чем не отличается от операнда из внешней памяти. Разница есть для блока вычисления адреса и выборки операндов, но мы сегодня это не рассматриваем.
Таким образом, для операнда A у нас может быть два источника (регистр и память), а для операнда B три источника (регистр, память, "0"). Для процессора, который может выполнять команды с двумя расположенными в памяти операндами это так. Но такая возможность делает выполнение команды состоящим из нескольких этапов/циклов, потребуется два доступа в память для получения операндов (не считая доступа для получения кода команды). Это, безусловно, возможно, но для нашего учебного процессора излишне усложнит схему. Поэтому снизим универсальность и позволим находиться в памяти лишь одному из операндов. При этом не будем накладывать ограничения, какой именно операнд в памяти.
Выбор источника операнда осуществляется мультиплексорами, которые установлены до регистров защелок. Мультиплексоры являются стандартными элементами комплектов логических и цифровых микросхем, поэтому я не буду рассматривать их внутреннее устройство. Напомню лишь, что мультиплексор тоже является комбинационным устройством. Он позволяет передать состояние одного из входов на выход, по сути, как обычный переключатель. Но положение этого переключателя определяется не механически, а номером/адресом входа, который подается на входы управления мультиплексора.
Давайте добавим мультиплексоры выбора операндов к нашей схеме
Здесь используется два мультиплексора выбора операндов. Для операнда A использован мультиплексор 2-в-1. Выбор операнда осуществляется сигналом SEL_A. Поскольку варианта всего 2, нам достаточно одного разряда адреса. Выбор источника операнда B осуществляется вторым мультиплексором, 3-в-1, для чего требуется уже два разряда адреса (что и указано на схеме), которые соответствуют сигналу SEL_B.
Обратите внимание, что у нас разные сигналы выбора источников операндов, так операнды независимы. Точно так же, как регистры защелки набираются из n триггеров-защелок, мультиплексоры набираются из n одноразрядных мультиплексоров. И на принципиальной схеме это будет показано. Но на логической (уже не функциональной) схеме просто изображается многоразрядный мультиплексор или защелка. Фрагмент логической схемы с последней иллюстрации можно легко преобразовать в принципиальную схему с использованием конкретных микросхем.
Источник с адресом 0, любого операнда , соответствует операнду в регистре. Мы пока не детализируем в каком именно. Источник с адресом 1, любого операнда, соответствует операнду в памяти. Обратите внимание, что для операндов в регистрах показаны два независимых канала к блоку регистров. А вот для операндов в памяти лишь один канал к блоку работы с ОЗУ. Мы договорились, что в памяти может быть лишь один из операндов и такая схема является отражением этого решения. Мы можем снять наше ограничение организовав два независимых канала к блоку работы с ОЗУ. Для операнда B возможен источник с адресом 2, который позволяет подать на вход B АЛУ "0".
Блок регистров
Блок регистров может быть построен по разному. В простейшем случае, он позволяет одновременно выполнять лишь одну операцию чтения или записи по заданному адресу. Такой блок регистров состоит из матрицы триггеров, дешифратора адреса, схемы управления. Но более функционален блок регистров с несколькими каналами доступа, каждый из которых позволяет выполнять отдельную операцию, причем параллельно с остальными каналами. Как такое возможно? Довольно просто, на самом деле.
Давайте сначала рассмотрим два независимых канала доступа для чтения к матрице триггеров или набору регистров. Нам потребуется просто несколько мультиплексоров. Например, так
Я не стал показывать подробности, связанные с регистрами, поскольку они не важны. Два Обратите внимание, что регистры n-разрядные. Все ранее сказанное про защелки и мультиплексоры относится и к регистрам. По сути, мультиплексоры просто выбирают для передачи на выход блока регистров выходы одного из регистров, в соответствии с сигналами Addr_A или Addr_B. Обратите внимание, что чтение полностью асинхронное.
Примерно так же строится и канал записи. Можно реализовать несколько независимых каналов записи, но тогда потребуется схема разрешения коллизий, когда два канала требуют запись в один и тот же регистр. Наш процессор учебный, поэтому ограничимся единственным каналом записи. К тому же, это довольно типовой случай.
Канал записи это просто демультиплексор. Демультиплексор отличается от мультиплексора тем, что передает на один из выходов состояние единственного входа. Его тоже можно рассматривать как аналог переключателя, только входы и выходы поменялись местами. Демультиплексор тоже является стандартным элементом комплектов логических и цифровых микросхем, поэтому его внутреннее устройство рассматривать не будем. Разрядность адреса для демультиплексора записи такая же, как для мультиплексоров чтения. Сигнал записи, тактовый импульс, по фронту которого осуществляется запись, подается через еще один демультиплексор, так как он должен подаваться лишь на выбранный регистр. Остается добавить, что регистры могут быть построены на базе D-триггеров. Впрочем, их можно построить и на базе защелок. И получаем такую схему блока регистров
Обратите внимание, что адрес регистра для записи задается отдельным сигналом Addr_W. У нашего блока регистров есть одна важная особенность. Если адрес записываемого регистра совпадает с адресом считываемого по одному из каналов, то вновь записанная информация сразу попадает на выход. Именно по этой причине мы можем использовать в качестве элементарных ячеек в регистрах не только D-триггеры, но более простые защелки.
Насколько критичная эта особенность нашего блока регистров? Довольно критична. Но избежать связанных с ней проблем позволяю защелки на входах АЛУ. Причем для нашего простого учебного процессора мы можем перенести эти защелки в блок регистров, если блок работы с ОЗУ обеспечивает фиксацию значения операнда на время выполнения операции.
Хорошо видно, что блок регистров является довольно сложным узлом ядра нашего процессора.
Соединяем все узлы воедино
Если просто добавить блок регистров к уже нарисованной нами части схемы, то получим такое
Обратите внимание, что сигналы SEL_A и SEL_B выбирают путь получения операндов, но если операнд (операнды) в регистрах, то нам нужны дополнительные сигналы выбора конкретных регистров Addr_A и Addr_B.
Сложно? Но это еще далеко не полное ядро процессора! Мы еще не добавили схему сохранения результата. Как мы помним, результат может сохраняться в регистре или памяти. Запись результата в регистр реализовать просто, а вот с памятью сложнее. Дело в том, что память может являться и источником операнда, поэтому использовать один канал между блоком работы с ОЗУ нельзя. Обойти проблему можно разными путями. Например, можно разнести во времени получение операнда из памяти с записью в защелку и запись результата в память. Но мы просто используем два канала к блоку работы с ОЗУ. Разделение во времени мы, возможно (только возможно!) рассмотрим в отдельной статье. И у нас получается такая логическая схема процессора
Это уже вполне рабочее ядро нашего простого учебного процессора. Оно соответствует регистровой архитектуре процессора и избыточно для аккумуляторной. Но аккумуляторная архитектура этим ядром прекрасно реализуется. Как именно, мы будем рассматривать в последующих статьях. Но вот со стековой архитектурой возникают небольшие проблемы. Дело в том, что мы используем явные адреса регистров, а в стековой архитектуре они должны адресоваться только указателем на вершину стека (SP).
Добавляем аппаратный стек для стековой архитектуры
Мы можем оставить все как есть переложив необходимые операции на блок микропрограммного управления. Но давайте попробуем добавить аппаратный стек в нашу схему. Для этого превратим наш самый нижний регистр в блоке регистров в счетчик, причем реверсивный и с возможностью начальной установки. Но этого недостаточно, так как нужны еще мультиплексоры для выбора в качестве источников адресов регистров содержимое SP. Примерно так
Вот теперь мы получили универсальное ядро (вычислительное) процессора, которое может использоваться для реализации процессора любой из трех рассмотренных архитектур. Это логическая схема, без учета временных параметров. По сути, просто набросок логической схемы. Хорошо видно, что ядро нашего ядра, АЛУ, является лишь маленьким фрагментом схемы.
Связь вычислительного ядра процессора с другими узлами процессора
Мы нарисовали только ядро, это далеко не весь процессор! Это лишь его малая часть. И у нас на схеме есть сигналы, которые идут "в никуда". Давайте разберемся, в какие блоки процессора они должны идти.
Сигналы "к блоку работы с ОЗУ", как и следует из их названия, идут к блоку обеспечивающему взаимодействие процессора и внешней памяти. Причем не только ОЗУ, на самом деле. Этот блок для своей работы использует и блок вычисления адресов и выборки команд и данных. Это как минимум.
Сигналы Ci и Co используются для каскадирования ядер для обеспечения увеличенной разрядности обрабатываемых данных. А из двух крайних ядер в цепочке эти сигналы попадают в регистр состояния процессора (PSW) в виде всем знакомых флагов переноса.
Все остальные сигналы (OP, C, SEL_A, SEL_B, Add_A, Addr_B, Addr_W, W, INC_SP, DEC_SP, SEL_SP) идут в блоки управления, дешифрации команд, микропрограммного управления. В зависимости от конфигурации и архитектуры других узлов процессора.
Что еще можно добавить?
Я не буду рисовать это на схемах. Во первых, это усложнит и сделает менее наглядными (особенно, для новичков) даже логические схемы. Во вторых, это будет полезным упражнением для читателей. При желании мы можем обсудить различные варианты в комментариях и разобрать их более детально.
Одним из первых можно добавить сдвигатели данных. Сдвигатели можно включить на выходе АЛУ и на входах. В простейшем случае, сдвигатели будут реализовывать сдвиг на один разряд (можно лишь в одну сторону, а можно и в обе). В более сложном варианте можно задавать несколько шагов сдвига.
Сдвигатели осуществляют сдвиг проходящих через них данных на несколько разрядов вправо или влево. Или пропускать данные без сдвига. Причем возможно построение сдвигателей как для логических, так и арифметических сдвигов. При этом сдвигатели довольно просты в построении, достаточно лишь использовать мультиплексоры. А польза от сдвигателей значительна, особенно, для выполнения команд умножения и деления, если АЛУ не содержит аппаратных умножителей и делителей.
Гораздо менее востребованным, но весьма интересным, расширением является возможность подключения дополнительных блоков регистров для построения сложных и функциональных, но при этом быстрых, процессоров.
Есть и варианты оптимизации. Если присмотреться, наше ядро использует два независимых источника операндов и один независимый приемник результата. То есть, мы можем реализовать на нашем ядре выполнение полноценных трехадресных команд. Но более распространены более простые процессоры, в которых результат сохраняется на месте одно из операндов. Введение такое ограничения позволит упростит схему нашего ядра.
Заключение
Сегодня мы занимались попыткой практического построения вычислительного ядра, довольно простого, для некоторого учебного процессора. В результате, у нас получилась логическая схема, которую можно довольно легко преобразовать в принципиальную, причем любой выбранной вами разрядности. И даже эта схема получилась совсем не такой простой.
Именно по этой причине я не привожу в статьях принципиальные схемы процессоров, как просят некоторые читатели. Они безусловно интересны, но лишены наглядности для изучающих архитектуру ЭВМ. Просто "за деревьями" вы не увидите собственно "леса". Если привести наглядную аналогию, то находясь в одной из комнат огромного дворца не получится составить представления об архитектуре собственно дворца. Для это нужно отойти на некоторое расстояние и окинуть взглядом весь дворец. При это множество деталей останутся незамеченными, но появится возможность увидеть (и оценить!) замысел архитектора.
Я буду и дальше публиковать достаточно подробные логические схемы, но на уровень схем принципиальным спускаться точно не буду. Но если у вас возникнут практические вопросы, то отвечу и подскажу, как выйти из затруднения.
В следующей статье мы займемся выяснением, что такое адресность, адресуемость, адресация. И как все это связано с нашим процессором.