
Сегодня 25 апреля 2022 года 10 часов 23 минуты, +13
Всем доброго дня!
Продолжаем разбирать возможные вопросы на собеседовании.
Начало:
Ведущий программист 1С: вопросы на собеседовании и ответы на них (УФ)
Ведущий программист 1С: вопросы на собеседовании и ответы на них (СКД, запросы)
Ведущий программист 1С: вопросы на собеседовании и ответы на них (транзакции, блокировки)
Из темы блокировок логично вытекает тема индексов.
Индексы
В свое время я посвятил статью по способу оптимизации высоконагруженной базы в части анализа недостающих индексов.
SQL сервер: Сбор и анализ статистики по выполняемым процедурам на продуктивном сервере
Обслуживание базы в том числе и индексов
SQL сервер 2008: обслуживание, анализ производительности
Что такое индекс?
объект базы данных, создаваемый с целью повышения производительности поиска данных
ответ, как вы видите, философский. А если индекс не приводит к повышению производительности?
Предлагаю более подробно разобрать что же такое индекс.
Если вкратце, индекс - это оглавление в книге, которое значительно позволяет ускорить поиск какой-то информации.
Без оглавления, чтобы найти какую-то конкретную информацию, необходимо пролистать всю книгу.
Оглавление ограничивает поиск нужной информации определенными страницами.
Так же это работает и в базе.
Индексы представляют собой структуру, позволяющую выполнять ускоренный доступ к строкам таблицы на основе значений одного или более ее столбцов.
Индекс – это набор ссылок, упорядоченных по определенному столбцу таблицы, который в данном случае будет называться индексированным столбцом . Хотя индекс и связан с конкретным столбцом (или столбцами ) таблицы, все же он является самостоятельным объектом базы данных.
Физически индекс – всего лишь упорядоченный набор значений из индексированного столбца с указателями на места физического размещения исходных строк в структуре базы данных. Когда пользователь выполняет обращающийся к индексированному столбцу запрос, СУБД автоматически анализирует индекс для поиска требуемых значений.
Однако, поскольку индексы должны обновляться системой при каждом внесении изменений в их базовую таблицу, они создают дополнительную нагрузку на систему.
Где хранятся индексы?
Индексы сохраняются в дополнительных структурах базы данных, называющихся страницами индексов.
Какова структура индекса?
Индекс состоит из набора страниц, узлов индекса, которые организованы в виде древовидной структуры — сбалансированного дерева. Эта структура является иерархической по своей природе и начинается с корневого узла на вершине иерархии и конечных узлов, листьев, в нижней части, как показано на рисунке:
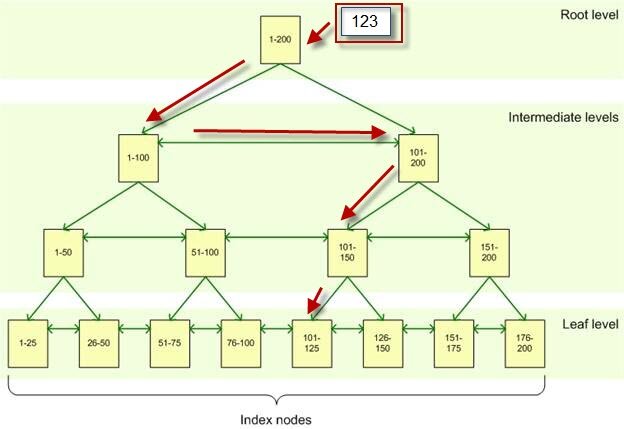
Когда вы формируете запрос на индексированный столбец, подсистема запросов начинает идти сверху от корневого узла и постепенно двигается вниз через промежуточные узлы, при этом каждый слой промежуточного уровня содержит более детальную информацию о данных. Подсистема запросов продолжает двигаться по узлам индекса до тех пор, пока не достигнет нижнего уровня с листьями индекса.
К примеру, если вы ищете значение 123 в индексированном столбе, то подсистема запросов сначала на корневом уровне определит страницу на первом промежуточном (intermediate) уровне. В данном случае первой страница указывает на значение от 1 до 100, а вторая от 101 до 200, таким образом подсистема запросов обратится ко второй странице этого промежуточного уровня. Далее будет выяснено, что следует обратиться к третьей странице следующего промежуточного уровня. Отсюда подсистема запросов прочитает на нижнем уровне значение самого индекса.
Листья индекса могут содержать как сами данные таблицы, так и просто указатель на строки с данными в таблице, в зависимости от типа индекса: кластеризованный индекс или некластеризованный.
Что такое кластеризованный (кластерный) индекс?
Кластеризованный индекс хранит реальные строки данных в листьях индекса. Возвращаясь к предыдущему примеру, это означает что строка данных, связанная со значение ключа, равного 123 будет храниться в самом индексе. Важной характеристикой кластеризованного индекса является то, что все значения отсортированы в определенном порядке либо возрастания, либо убывания. Таким образом, таблица может иметь только один кластеризованный индекс. В дополнение следует отметить, что данные в таблице хранятся в отсортированном виде только в случае если создан кластеризованный индекс у этой таблицы.
Таблица не имеющая кластеризованного индекса называется кучей.
Кластеризованный индекс – это и есть таблица. Когда вы создаете кластеризованный индекс у таблицы, подсистема хранения данных сортирует все строки в таблице в порядке возрастания или убывания, согласно определению индекса. Кластеризованный индекс это не отдельная сущность как другие индексы, а механизм сортировки данных в таблице и облегчения быстрого доступа к строкам с данными.
Что такое некластеризованный (некластерный) индекс?
В отличие от кластеризованного индекса, листья некластеризованного индекса содержат только те столбцы (ключевые), по которым определен данный индекс, а также содержит указатель на строки с реальными данными в таблице. Это означает, что системе подзапросов необходима дополнительная операция для обнаружения и получения требуемых данных. Содержание указателя на данные зависит от способа хранения данных: кластеризованная таблица или куча. Если указатель ссылается на кластеризованную таблицу, то он ведет к кластеризованному индексу, используя который можно найти реальные данные. Если указатель ссылается на кучу, то он ведет к конкретному идентификатору строки с данными. Некластеризованные индексы не могут быть отсортированы в отличие от кластеризованных, однако вы можете создать более одного некластеризованного индекса на таблице или представлении, вплоть до 999. Это не означает, что вы должны создавать как можно больше индексов. Индексы могут как улучшить, так и ухудшить производительность системы. В дополнение к возможности создать несколько некластеризованных индексов, вы можете также включить дополнительные столбцы (included column) в свой индекс: на листьях индекса будет храниться не только значение самих индексированных столбцов, но и значения этих не индексированных дополнительных столбцов. Этот подход позволит вам обойти некоторые ограничения, наложенные на индекс. К примеру, вы можете включить неидексируемый столбец или обойти ограничение на длину индекса (900 байт в большинстве случаев).
Какие другие типы индексов вы знаете?
В дополнение к тому, что индекс может быть либо кластеризованным, либо некластеризованным, возможно его дополнительно сконфигурировать как составной индекс, уникальный индекс или покрывающий индекс.
Составной индекс
Такой индекс может содержать более одного столбца. Вы можете включить до 16 столбцов в индекс, но их общая длина ограничена 900 байтами. Как кластеризованный, так и некластеризованный индексы могут быть составными.
Уникальный индекс
Такой индекс обеспечивает уникальность каждого значения в индексируемом столбце. Если индекс составной, то уникальность распространяется на все столбцы индекса, но не на каждый отдельный столбец. К примеру, если вы создадите уникальных индекс на столбцах ИМЯ и ФАМИЛИЯ, то полное имя должно быть уникально, но отдельно возможны дубли в имени или фамилии.
Уникальный индекс автоматически создается когда вы определяете ограничения столбца: первичный ключ или ограничение на уникальность значений:
Первичный ключ
Когда вы определяете ограничение первичного ключа на один или несколько столбцов, тогда SQL Server автоматически создаёт уникальный кластеризованный индекс, если кластеризованный индекс не был создан ранее (в этом случае создается уникальный некластеризованный индекс по первичному ключу)
Уникальность значений
Когда вы определяете ограничение на уникальность значений, тогда SQL Server автоматически создает уникальный некластеризованный индекс. Вы можете указать, чтобы был создан уникальный кластеризованный индекс, если кластеризованного индекса до сих пор не было создано на таблице
Покрывающий индекс
Такой индекс позволяет конкретному запросу сразу получить все необходимые данные с листьев индекса без дополнительных обращений к записям самой таблицы.
Какие рекомендации вы можете дать по использованию индексов?
Как было отмечено ранее индексы могут улучить производительность системы, т.к. они обеспечивают подсистему запросов быстрым путем для нахождения данных. Однако, вы должны также принять во внимание то, как часто вы собираетесь вставлять, обновлять или удалять данные. Когда вы изменяете данные, то индексы должны также быть изменены, чтобы отразить соответствующие действия над данными, что может значительно снизить производительность системы. Рассмотрим следующие рекомендации при планировании стратегии индексирования:
- Для таблиц которые часто обновляются используйте как можно меньше индексов.
- Если таблица содержит большое количество данных, но их изменения незначительны, тогда используйте столько индексов, сколько необходимо для улучшение производительности ваших запросов. Однако хорошо подумайте перед использованием индексов на небольших таблицах, т.к. возможно использование поиска по индексу может занять больше времени, нежели простое сканирование всех строк.
- Для кластеризованных индексов старайтесь использовать настолько короткие поля насколько это возможно. Наилучшим образом будет применение кластеризованного индекса на столбцах с уникальными значениями и не позволяющими использовать NULL. Вот почему первичный ключ часто используется как кластеризованный индекс.
- Уникальность значений в столбце влияет на производительность индекса. В общем случае, чем больше у вас дубликатов в столбце, тем хуже работает индекс. С другой стороны, чем больше уникальных значения, тем выше работоспособность индекса. Когда возможно используйте уникальный индекс.
- Для составного индекса возьмите во внимание порядок столбцов в индексе. Столбцы, которые используются в выражениях WHERE (к примеру, WHERE FirstName = 'Charlie') должны быть в индексе первыми. Последующие столбцы должны быть перечислены с учетом уникальности их значений (столбцы с самым высоким количеством уникальных значений идут первыми).
Что такое фрагментация индекса?
В индексах сбалансированного дерева (rowstore) фрагментацией называют такое состояние, когда для некоторых страниц индекса логический порядок, основанный на значении ключа, не совпадает с физическим порядком страниц индексов.
Особенности построения индексов платформой 1С
В приведенных ниже таблицах имена индексных полей приведены так, как они описаны в разделе документации "Таблицы запросов".
Для измерений, реквизитов и т.д. применяются условные имена Измерение1, Реквизит1 и т.д.
Для общих реквизитов, являющихся разделителями в режиме "независимо", будем использовать имена ОРНР (ОРНР1, ОРНР2, и т.д.).
Для общих реквизитов, являющихся разделителями в режиме "независимо и совместно", будем использовать имена ОРСР.
Если режим разделения не имеет значения, то для общих реквизитов, являющихся разделителями, будем использовать имена ОРР.
Если в конфигурации определены разделители, то в индексы может входит поле, которое содержит значение хэш-функции набора значений разделителей. Такое поле будем обозначать именем ОРРХ.
Те индексные поля, которые не являются обязательными приведены в квадратных скобках, а если в индексе присутствует набор однотипных полей, это описывается многоточием, например: Реквизит + Измерение1 + [Измерение2 +...].
Источники:
14 вопросов об индексах в SQL Server, которые вы стеснялись задать
#ведущий программист 1с #индексы #кластерные индексы #некластерные индексы #уникальный индекс